The Top Python Tools to Analyze PUMS Census Data
By
M
Marlene MhangamiAuthor(s):
M
Marlene MhangamiPublished: March 8, 2023
12 min read
In today’s data-driven world, having access to the right information can make all the difference in making wise decisions. Whether you’re a business looking to understand your target audience or a researcher interested in exploring demographic trends, the PUMS (Public Use Microdata Sample) dataset from the American Community Survey (ACS) is a treasure trove of information. The ACS is “an ongoing nationwide survey… This survey has an annual sample size of 3.5 million addresses, with survey information collected nearly every day of the year.” That sample size covers about 1% of the population. As the name suggests, the PUMS dataset is a smaller portion of the ACS that is made available to the public.
This dataset offers a wealth of information on various aspects of American society, including demographic trends, income distribution, and education levels. With the PUMS dataset, you can gain insights into the American population that can help you make better decisions.
Python is the most popular language for exploring data. With a wide range of libraries and tools specifically designed for data analysis and visualization, Python makes it easy to extract meaningful insights from most datasets. In this blog post, we’ll dive into some of the best Python tools for analyzing census data and show you how you can get the most out of the PUMS data (and don’t miss the blog we published yesterday about how to scale the dataset down). Whether you’re a data scientist, business analyst, or simply someone interested in exploring the data, you’ll hopefully find this useful!
1. Apache Arrow For Data Compression
Apache Arrow is an excellent open source tool for working with large datasets. It defines a language-independent columnar memory format for flat and hierarchical data. In this first section we’ll be using it to change our CSV files into Parquet, a more compact file format.
The first thing we’ll need to do is to get the data and store it on our machine. Grabbing the data is not too complicated. I was able to pull data from 2015 to 2022 onto my Mac with this one line in the terminal.
bash
wget --recursive -w 2 -nc --level=1 --no-parent --no-directories --accept 'csv*' --reject '*pus*' --reject '*hus*' --directory-prefix=. ftp://ftp.census.gov/programs-surveys/acs/data/pums/2020/5-Year/Successful execution of this command should result in a group of zip files in a directory. To unzip these files I used the command unzip \*.zip. At this point, we’ll have a huge collection of CSV files that are about 14.3GB in size. The most common RAM size you can find in an everyday laptop nowadays is 8GB. Many data scientists and software engineers use tools that can analyze data that fits in memory. A general rule of thumb for working with such frameworks is to have 5 to 10 times as much RAM as the size of your dataset. The CSV files we have far exceed this rule, and could greatly slow analysis work. To address this problem we’ll be using our first tool; Apache Arrow.
Before we do this, it’s important to note that the PUMS dataset is divided into data about people and data about households. Mixing these two together can corrupt the data. To avoid this, we’ll split the CSV files into subfolders. One containing people data and one containing the household data. Person data is named psam_p**.csv, and household data is named psam_h**.csv. To move the household CSVs into a folder called ‘household’, I ran this in the command line mv psam_h**.csv household. To move the people data into a folder called ‘people’ I ran mv psam_p**.csv people. Now, we are ready to write the code to compress these files.
We’ll start by importing PyArrow and the dataset module that we’ll use to read in the data.
Import dependencies create a dataset for each folder
python
import pyarrow as pa
import pyarrow.dataset as ds
#this line takes all the csvs files in the folder and adds them to the
#same dataset. It excludes pdf files.
people_dataset = ds.dataset('pums/people', format="csv", exclude_invalid_files=True)
house_dataset = ds.dataset('pums/household', format="csv", exclude_invalid_files=True)
Next, we’ll create a schema for both datasets and make sure the columns types are correct. A schema defines the column names (fields) and types in a record batch or table data structure. We’ll use the set method to change the field name or type at the position in the schema. Once the schemas are defined, we add them to the datasets we created above.
Create a schema for the data with correct types
python
people_schema = people_dataset.schema.set(1, pa.field("SERIALNO", pa.string()))
people_schema = people_schema.set(75, pa.field("WKWN", pa.string()))
people_dataset = ds.dataset('pums/people', format="csv", exclude_invalid_files=True, schema=people_schema)
house_schema = house_dataset.schema.set(1, pa.field("SERIALNO", pa.string()))
house_dataset = ds.dataset('pums/household', format="csv", exclude_invalid_files=True, schema=house_schema)We’re now ready to convert our datasets to Parquet format. The code will convert each CSV file into a new Parquet file. It will also store the converted files on our local machine in the folders, partitioned_household and partitioned_people
Write both datasets to disk
python
part = ds.partitioning(
pa.schema([("RT", pa.string()), ("ST", pa.int16())]), flavor="hive"
)
ds.write_dataset(house_dataset, "partitioned_household", format="parquet", partitioning=part)
ds.write_dataset(people_dataset, "partitioned_people", format="parquet", partitioning=part)After running this code we see a significant drop in size of the relevant data. The partitioned_people folder is 3.29GB, and the partitioned_household folder is 1.32GB. This means our dataset went from 14.13GB to 4.6 GB. That’s a 3X reduction in size in a few lines of code!
As I mentioned earlier, our data should be at least five times smaller than RAM for us to confidently use tools like pandas. Even compressed, the PUMS data is still slightly over that range. It’s possible to reduce the size of the files further. I won’t show you how to do that in this post, but if you’d like to learn how, see this tutorial.
Since our files are still too big to fit comfortably in memory we’ll switch to our second Python package to address this.
2. Ibis For Data Pre-Processing
Ibis is a pandas-like Python interface that allows you to do robust analytics work on data of any size. It does this by letting you choose from a range of powerful database engines that can process your data queries. As an example, we’ll use Ibis to do some data exploration and pre-processing.
To begin with we’ll start by installing and importing Ibis into the Python environment of our choice.
Install and import Ibis
python
#we'll install the ibis framework with the duckdb backend specified, as this is the default backend.
!pip install 'ibis-framework[duckdb]'
#importing Ibis and setting interavtive mode to True to better visualise our data
import ibis
ibis.options.interactive = True For this example, we’ll be drawing insights from both datasets. To make it easier for Ibis to read, we’ll consolidate the parquet files in both folders into a single Parquet file each.
Create a single Parquet file for people data
python
#let's get an arrow table and turn the people and houseld datasets
# into one parquet file each
import pyarrow.parquet as pq
# Read the people parquet data into memory
pq_people = ds.dataset("./partitioned_people", format="parquet", partitioning=part)
people = pq_people.to_table()
pq.write_table(people, 'people.parquet')
# Read the household parquet data into memory
pq_household = ds.dataset("./partitioned_household", format="parquet", partitioning=part)
household = pq_household.to_table()
pq.write_table(household, 'household.parquet')Next, we’ll use read_parquet to turn the two files into Ibis tables. If you’re following along with the code you’ll hopefully notice how refreshingly fast the tables are created!
Make an Ibis table from the household Parquet data
python
#read in the two parquet files into ibis tables
people = ibis.read_parquet('people.parquet')
household = ibis.read_parquet('household.parquet')To ensure this worked as expected, let’s preview the first few rows of data by running the head function. As I stated earlier, the Ibis API should feel familiar to anyone who’s used pandas before.
Preview the data
python
people.head(python
┏━━━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━┓
┃ SERIALNO ┃ DIVISION ┃ SPORDER ┃ PUMA ┃ REGION ┃ ADJINC ┃ PWGTP ┃ AGEP ┃ CIT ┃ CITWP ┃ COW ┃ … ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━┩
│ string │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ … │
├───────────────┼──────────┼─────────┼───────┼────────┼─────────┼───────┼───────┼───────┼───────┼───────┼───┤
│ 2016000000064 │ 6 │ 1 │ 700 │ 3 │ 1086849 │ 21 │ 84 │ 1 │ ∅ │ ∅ │ … │
│ 2016000000064 │ 6 │ 2 │ 700 │ 3 │ 1086849 │ 19 │ 84 │ 1 │ ∅ │ ∅ │ … │
│ 2016000000080 │ 6 │ 1 │ 900 │ 3 │ 1086849 │ 19 │ 78 │ 1 │ ∅ │ 1 │ … │
│ 2016000000107 │ 6 │ 1 │ 302 │ 3 │ 1086849 │ 34 │ 46 │ 1 │ ∅ │ 1 │ … │
│ 2016000000107 │ 6 │ 2 │ 302 │ 3 │ 1086849 │ 30 │ 52 │ 1 │ ∅ │ ∅ │ … │
└───────────────┴──────────┴─────────┴───────┴────────┴─────────┴───────┴───────┴───────┴───────┴───────┴───┘We now have a table named people. Let’s find out how many columns and rows are contained in the dataset.
python
#number of columns
household.columns.__len__() 234
python
#number of rows
household.count()15570658
This is a fairly large dataset with 234 columns and over 15.5 million rows. When using Ibis, working with a dataset this big should feel light. Now, besides getting information about the dataset, we can also use Ibis to wrangle the data into its most valuable form. In this next example, we’ll use Ibis to gather some insightful information about the different American states.
Let’s use the household data to find the average income a household makes across various states in the U.S. As a reminder, to know what each column name is code for visit the PUMS data dictionary here. I’ll be using the HINCP column in the household table, which contains the household income for the past 12 months. I’ll also use the ST column that has a list of numbers, corresponding to the states.
Average income by state
python
# Calculate the average income for each state
household_av_income_by_state = household.group_by(household.ST).aggregate(total_income = household.HINCP.mean())
household_av_income_by_statepython
┏━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ ST ┃ total_income ┃
┡━━━━━━━╇━━━━━━━━━━━━━━━┩
│ int16 │ float64 │
├───────┼───────────────┤
│ 1 │ 69498.190371 │
│ 2 │ 86871.838259 │
│ 4 │ 82166.030477 │
│ 5 │ 65227.495030 │
│ 6 │ 111270.668560 │
│ 8 │ 99906.747200 │
│ 9 │ 120057.369737 │
│ 10 │ 92746.759751 │
│ 11 │ 137634.856483 │
│ 12 │ 83942.223405 │
│ … │ … │
└───────┴───────────────┘I’d like to have the names of the states instead of a number. Here’s the code I used to get this.
python
#tip: I used chatgpt to convert the pdf list to a string list in Python to save time
us_states = {
'01': 'Alabama/AL','02': 'Alaska/AK','04': 'Arizona/AZ','05': 'Arkansas/AR','06': 'California/CA','08': 'Colorado/CO','09': 'Connecticut/CT','10': 'Delaware/DE','11': 'District of Columbia/DC','12': 'Florida/FL','13': 'Georgia/GA',
'15': 'Hawaii/HI','16': 'Idaho/ID','17': 'Illinois/IL','18': 'Indiana/IN','19': 'Iowa/IA','20': 'Kansas/KS','21': 'Kentucky/KY','22': 'Louisiana/LA','23': 'Maine/ME','24': 'Maryland/MD','25': 'Massachusetts/MA','26': 'Michigan/MI','27': 'Minnesota/MN','28': 'Mississippi/MS','29': 'Missouri/MO','30': 'Montana/MT','31': 'Nebraska/NE','32': 'Nevada/NV','33': 'New Hampshire/NH','34': 'New Jersey/NJ','35': 'New Mexico/NM','36': 'New York/NY','37': 'North Carolina/NC','38': 'North Dakota/ND','39': 'Ohio/OH','40': 'Oklahoma/OK','41': 'Oregon/OR','42': 'Pennsylvania/PA','44': 'Rhode Island/RI','45': 'South Carolina/SC','46': 'South Dakota/SD','47': 'Tennessee/TN','48': 'Texas/TX','49': 'Utah/UT','50': 'Vermont/VT','51': 'Virginia/VA','53': 'Washington/WA','54': 'West Virginia/WV','55': 'Wisconsin/WI','56': 'Wyoming/WY','72': 'Puerto Rico/PR'
}
#we'll use pandas to quickly turn the dictionary into a dataframe and convert that back to an ibis table called states_table
import pandas as pd
df = pd.DataFrame(us_states.items(), columns=['ST', 'ST_names'])
df['ST'] = df['ST'].astype('int16')
states_table = ibis.memtable(df)We’ll use an outer join to join the states and income tables together and order the table in descending order
python
average_income_by_state = average_income_by_state.outer_join(states_table, average_income_by_state.ST == states_table.ST)
average_income_by_state = average_income_by_state.drop('ST_y')
#lets print the household average income for the top 10 states
ordered_household_av_income_by_state= household_av_income_by_state.order_by(ibis.desc(_.total_income))
ordered_household_av_income_by_state.head(10)python
┏━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ST_x ┃ total_income ┃ ST_names ┃
┡━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ int16 │ float64 │ string │
├───────┼───────────────┼─────────────────────────┤
│ 11 │ 137634.856483 │ District of Columbia/DC │
│ 34 │ 120492.395816 │ New Jersey/NJ │
│ 9 │ 120057.369737 │ Connecticut/CT │
│ 24 │ 116315.314629 │ Maryland/MD │
│ 25 │ 115931.946704 │ Massachusetts/MA │
│ 6 │ 111270.668560 │ California/CA │
│ 15 │ 107295.314168 │ Hawaii/HI │
│ 51 │ 106822.981572 │ Virginia/VA │
│ 36 │ 103103.407528 │ New York/NY │
│ 53 │ 101366.955999 │ Washington/WA │
└───────┴───────────────┴─────────────────────────┘As we can see, Washington D.C. has the highest mean household income. We can plot this as a graph with the code below.
python
import matplotlib.pyplot as plt
av_income_by_state = ordered_household_av_income_by_state.head(10).execute()
#get the state abbreviations instead of full names
names = [name.split('/')[1] for name in av_income_by_state.ST_names]
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.bar(names,av_income_by_state.total_income)
plt.show()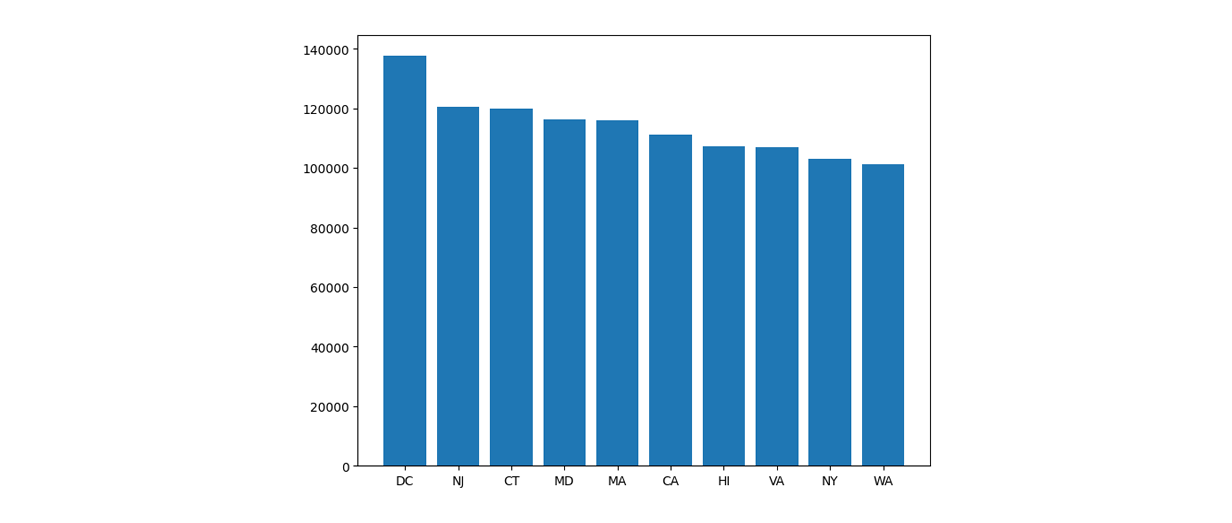
Average income by state
The popularity of Ibis shows that more data scientists and engineers see the benefits of leveraging a wide array of powerful database engines for more efficient Python analytics. Another popular approach to speeding up analytics work is to use a GPU. CuDF, the final Python package we will discuss, does just that!
3. CuDF for Feature Rich Analysis on the GPU
CuDF is a GPU-accelerated dataframe library that offers fast processing speeds and high performance for large-scale data analysis. Similarly to Ibis, it offers a pandas-like syntax, that should work as a drop-in replacement for pandas workflows. CuDF tries to be as similar to pandas as possible so its API contains most of the methods you’re familiar with using. Compared to Ibis and PyArrow, if you’re looking for a fuller feature set on GPU, CuDF is a great choice. It’s also open source and, as a fun side note, I’ve been a contributor in the past!
Before we look at the code, I’d like to note that as I began working on writing the code for this post, I ran into some of CuDF’s downsides. Firstly, it runs exclusively on Ubuntu, and for an avid Mac user like me, this was a rough start. Fortunately, the RAPIDS Project has a getting started Google Colaboratory Notebook for anyone who may not be on Linux or have a GPU. Secondly, I’d initially decided to analyze the people.parquet file. When I tried to use cudf.read_paruet to read it in I got several memory errors. Even in its compressed form, the people Parquet file is very large. It’s important to keep in mind that CuDF doesn’t handle memory for you in the same way Ibis does. To make things easier, I used Ibis to create a smaller people file that contained only the people data from people in the North region of the US (Mountain). I named this file nr_people.parquet and loaded it up to Colab. With all of that in mind let’s dive into the code.
Install CuDF and dependencies
To get going, you’ll need to check that you have a GPU available on your machine or in the cloud. Confirm this by running !nvidia-smi. If you didn’t get an error and saw a table returned you should be good to go. We’ll now go ahead and install the necessary dependencies needed for CuDF to work. If you’re working from your local machine and are wondering what the command you should run is, I recommend taking a look at the RAPIDS Get Started page. If you scroll down the page, you’ll see a table like the one pictured below. Select the options that are relevant to you and then copy the command at the bottom of the page in your command line to install.
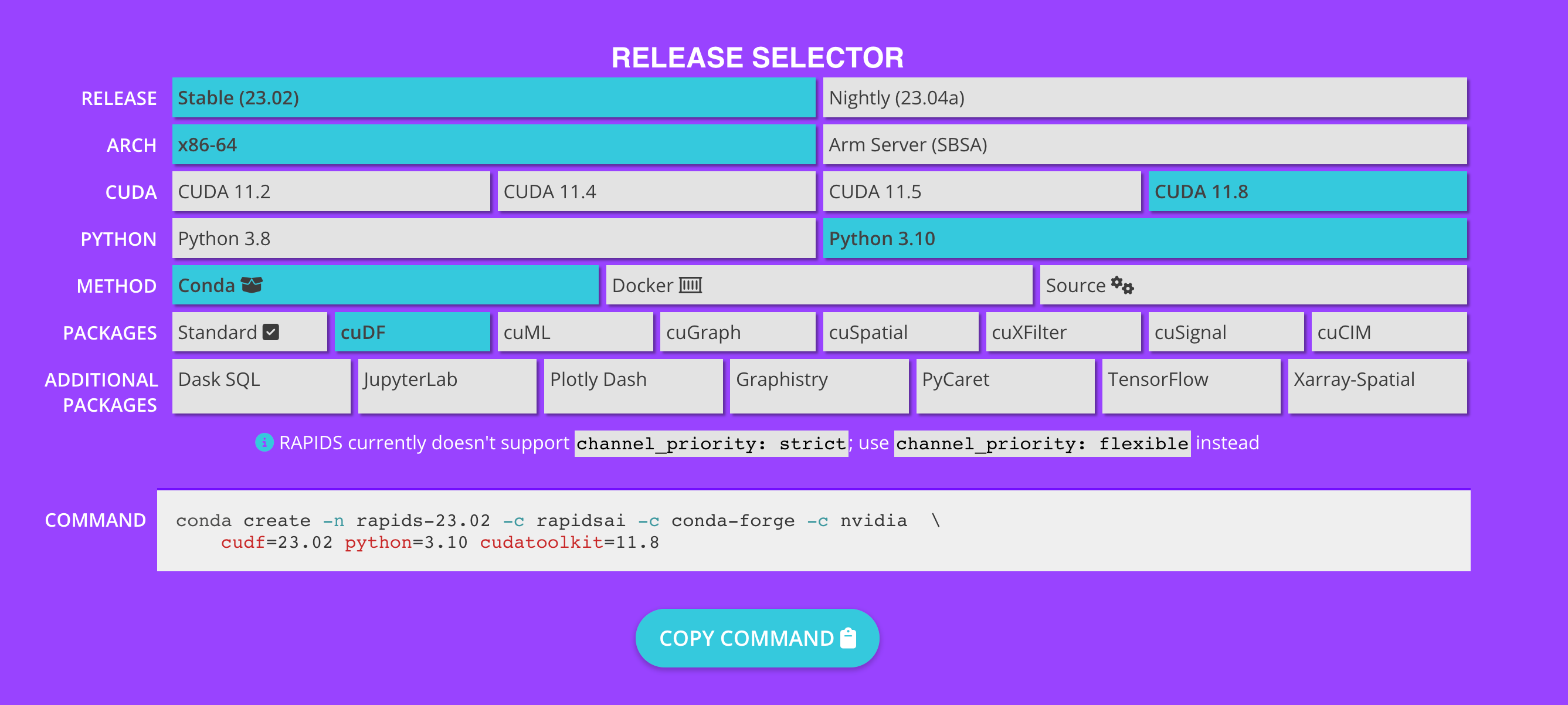
RAPIDS Getting Started: https://rapids.ai/start.html
As a reminder if you don’t have a GPU on your machine or if you’re working from a MAC use the notebook here and run the first few Colab cells in order. Once we’ve successfully installed CuDF we’ll import it and read the nr_people.parquet file in a similar way to Ibis.
Use the corr method to find the correlation
python
import cudf
#uploaded the nr_people file to my google drive and accessed it from there
people = cudf.read_parquet('/content/drive/MyDrive/nr_people.parquet')
#The age column for person data is AGEP
#the wages or salary income column for person data is WAGP
#the wage column has nulls in it so we fill those with the mean value
mean_wagp = people['WAGP'].mean()
people['WAGP'] = people['WAGP'].fillna(int(mean_wagp))
# Calculate the correlation between age and income
correlation = people[["AGEP", "WAGP"]].corr()
print(correlation)python
AGEP WAGP
AGEP 1 -0.040834
WAGP -0.040834 1This is interesting — let’s go ahead and visualize the data so the relationship between the two is clearer.
Visualize the data
python
# Create a scatter plot to visualize the relationship between age and income
plt.scatter(people["AGEP"], people["WAGP"])
plt.xlabel("Age")
plt.ylabel("Income")
plt.title("Age vs Income")
plt.show()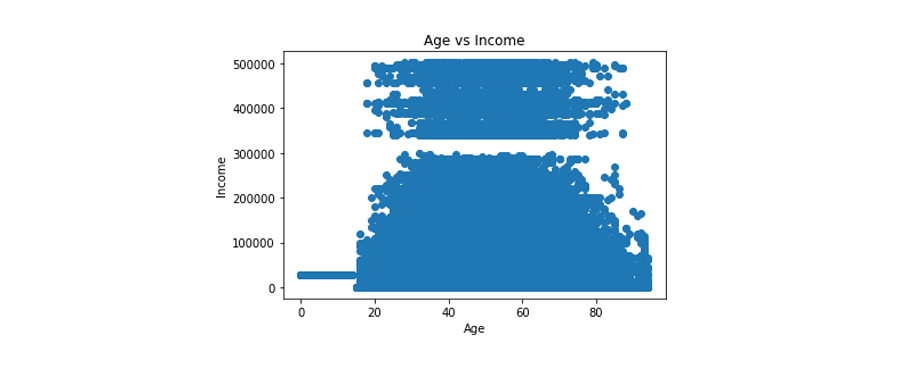
Correlation between age and income
We can see from the plot that the highest earners are in their late 30’s to just over 70 years old. We see that earners can be grouped into two classes those earning below $300,000 and those earning below it. Remember that this is data representing the North, Mountain region. I’d be curious to know your thoughts on this and whether you think this is similar to the rest of the U.S. or the world. Feel free to tweet at me @marlene_zw with your thoughts.
Conclusion
That’s all the code and awesome Python tools I have for you in this post. As the landscape of analytics libraries grows, we’re increasingly moving away from having to deal with bottlenecks in our workflows. In fact, this post highlights the fact that building a system where you use the best tool for the job for different parts of your work can make you more productive. Here are Voltron Data we know a lot about building efficient systems. If you’d like to learn more or just have any questions feel free to reach out. Thanks for reading!
Photo by: Jack Nagz
Previous Article

Keep up with us


