Ibis 5.1: Faster file reading with DuckDB, Arrow-Native Workflows for Snowflake, and more
By
K
Kae SuarezandA
Anja BoskovicAuthor(s):
K
Kae SuarezA
Anja BoskovicPublished: April 24, 2023
4 min read
The Ibis 5.1 release brings various improvements, ranging from more performant internals to new features and documentation. There’s plenty to love, and we wanted to highlight some of our favorite updates.
Get to Data Faster with DuckDB
In order to achieve the goal of being an interface that uses the full power of your backends, sometimes specialization is needed to leverage the underlying performance. Ibis 5.1 now fully exploits the power of DuckDB to read files faster than ever! As for what that means, best to let the numbers speak.
Ibis 5.0, pre-optimization (26s):
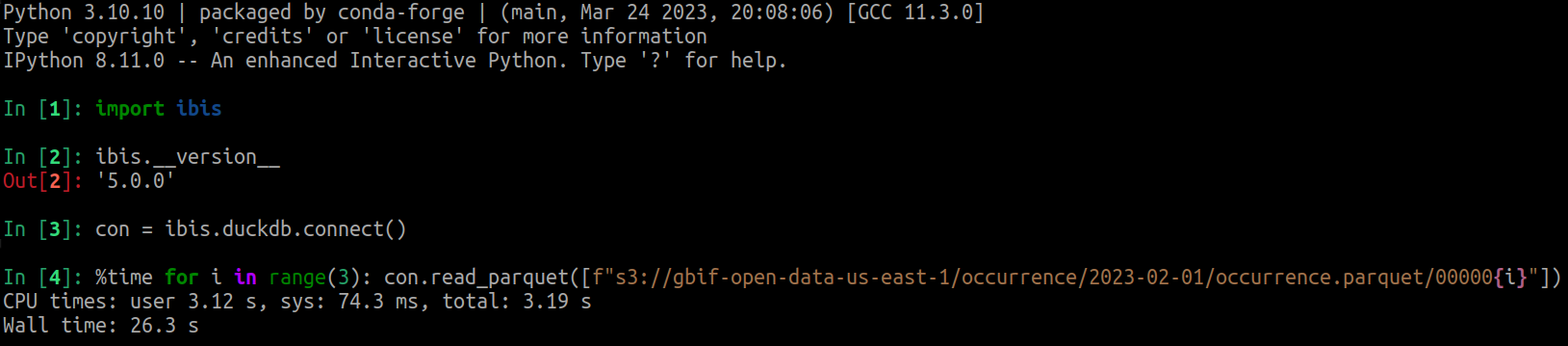
Ibis 5.1, post-optimization (1.46s):
DuckDB is very powerful when used well — a difference of 26s to 1.46s is impressive. It’s encouraging to see such attention to detail, while still maintaining 16+ backends
Getting Started with Ibis
Getting the baseline skills to use a library is often the hardest step. When you don’t know the basics, you don’t even know what questions to ask to move forward. Ibis now has a “Getting Started Guide” that should answer any questions you may have and get you up and running. It’s available for reading today on the website: https://ibis-project.org/getting_started/
If you prefer video content, Phillip Cloud recently live-streamed his journey through the guide, and you can watch that here: https://www.youtube.com/watch?v=rMeDeSNY8yI
Support for pandas 2.0
Recently, pandas 2.0 dropped with a swathe of performance improvements. Ibis provides a pandas backend and allows outputs to be served as pandas dataframes— as of 5.1, Ibis is already supporting the new version! If you’re already using Ibis with pandas, just update both libraries and you’re good to go. Or, if you haven’t yet, just set the Ibis backend to pandas with:
python
ibis.set_backend("pandas")Arrow-Native Workflows with Snowflake
Snowflake supports Arrow, the open source columnar format accelerating data workloads for many. Now, Ibis can leverage this native support to allow conversion-less use of Arrow-based data, from query to output. To use this yourself, just use to_pyarrow():
python
# This generates a pandas Dataframe as output
expr.execute()
# This yields an Arrow table
expr.to_pyarrow()Succinct Analytics with Improved distinct
distinct()is not a new function in Ibis — but it does now have new arguments! Instead of only deduplicating at the row-scale, you can now deduplicate based on values in certain columns. We’ll use the demonstration provided in the docs:
python
>>> import ibis
>>> import ibis.examples as ex
>>> import ibis.selectors as s
>>> ibis.options.interactive = True
>>> t = ex.penguins.fetch()
>>> t
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━┓
┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ … ┃
┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━┩
│ string │ string │ float64 │ float64 │ int64 │ … │
├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼───┤
│ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ … │
│ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ … │
│ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ … │
│ Adelie │ Torgersen │ nan │ nan │ NULL │ … │
│ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193 │ … │
│ Adelie │ Torgersen │ 39.3 │ 20.6 │ 190 │ … │
│ Adelie │ Torgersen │ 38.9 │ 17.8 │ 181 │ … │
│ Adelie │ Torgersen │ 39.2 │ 19.6 │ 195 │ … │
│ Adelie │ Torgersen │ 34.1 │ 18.1 │ 193 │ … │
│ Adelie │ Torgersen │ 42.0 │ 20.2 │ 190 │ … │
│ … │ … │ … │ … │ … │ … │
└─────────┴───────────┴────────────────┴───────────────┴───────────────────┴───┘Now, let’s say we want to only keep the first of each species/island combination, we just do the following:
python
>>> t.distinct(on=["species", "island"], keep="first")
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━┓
┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_… ┃ flipper_length_mm ┃ ┃
┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━┩
│ string │ string │ float64 │ float64 │ int64 │ │
├───────────┼───────────┼────────────────┼──────────────┼───────────────────┼──┤
│ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ │
│ Adelie │ Biscoe │ 37.8 │ 18.3 │ 174 │ │
│ Adelie │ Dream │ 39.5 │ 16.7 │ 178 │ │
│ Gentoo │ Biscoe │ 46.1 │ 13.2 │ 211 │ │
│ Chinstrap │ Dream │ 46.5 │ 17.9 │ 192 │ │
└───────────┴───────────┴────────────────┴──────────────┴───────────────────┴──┘Ibis is only getting more concise as time passes, and this is another example of an eye for detail.
Migrate More Workflows with pivot_wider
For those working in SQL, PIVOT may be a familiar command. Re-defining values into columns can be a powerful way to create new routes to analytics. Now, workloads that rely on this technique can be brought to Ibis, with the addition of pivot_wider(). It works in a familiar way for SQL users and enables new workflows for existing Ibis users. The following code pulls an example table of fish sightings, turns the station column’s values into column titles, and uses the seen column to fill in values:
python
>>> fish_encounters = ibis.examples.fish_encounters.fetch()
>>> fish_encounters
┏━━━━━━━┳━━━━━━━━━┳━━━━━━━┓
┃ fish ┃ station ┃ seen ┃
┡━━━━━━━╇━━━━━━━━━╇━━━━━━━┩
│ int64 │ string │ int64 │
├───────┼─────────┼───────┤
│ 4842 │ Release │ 1 │
│ 4842 │ I80_1 │ 1 │
│ 4842 │ Lisbon │ 1 │
│ 4842 │ Rstr │ 1 │
│ 4842 │ Base_TD │ 1 │
│ 4842 │ BCE │ 1 │
│ 4842 │ BCW │ 1 │
│ 4842 │ BCE2 │ 1 │
│ 4842 │ BCW2 │ 1 │
│ 4842 │ MAE │ 1 │
│ … │ … │ … │
└───────┴─────────┴───────┘
>>> fish_encounters.pivot_wider(names_from="station", values_from="seen")
┏━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━┓
┃ fish ┃ Release ┃ I80_1 ┃ Lisbon ┃ Rstr ┃ Base_TD ┃ BCE ┃ BCW ┃ … ┃
┡━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━┩
│ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ … │
├───────┼─────────┼───────┼────────┼───────┼─────────┼───────┼───────┼───┤
│ 4842 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ … │
│ 4843 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ … │
│ 4844 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ 1 │ … │
│ 4845 │ 1 │ 1 │ 1 │ 1 │ 1 │ NULL │ NULL │ … │
│ 4847 │ 1 │ 1 │ 1 │ NULL │ NULL │ NULL │ NULL │ … │
│ 4848 │ 1 │ 1 │ 1 │ 1 │ NULL │ NULL │ NULL │ … │
│ 4849 │ 1 │ 1 │ NULL │ NULL │ NULL │ NULL │ NULL │ … │
│ 4850 │ 1 │ 1 │ NULL │ 1 │ 1 │ 1 │ 1 │ … │
│ 4851 │ 1 │ 1 │ NULL │ NULL │ NULL │ NULL │ NULL │ … │
│ 4854 │ 1 │ 1 │ NULL │ NULL │ NULL │ NULL │ NULL │ … │
│ … │ … │ … │ … │ … │ … │ … │ … │ … │
└───────┴─────────┴───────┴────────┴───────┴─────────┴───────┴───────┴───┘Closing Statement
These are just a few highlights — with 132 PRs making up the milestone on GitHub, Ibis 5.1 brings a breadth of fixes and features. If you already use Ibis, you can update it right now, it’s already published on condaforge and pip. If you’re new, you can get started with it right away at https://ibis-project.org/ , and use the new “Getting Started” documentation to learn.
If you want to accelerate your success with Ibis, learn about Voltron Data Enterprise Support options.
Photo by Samuel-Elias Nadler

Keep up with us


