Apache Arrow: Driving Columnar Analytics Performance and Connectivity
By
W
Wes McKinneyAuthor(s):
W
Wes McKinneyPublished: February 3, 2022
16 min read
Big data has come a long way since MapReduce. Jeffrey Dean and Sanjay Ghemawat’s 2004 paper from Google gave birth to the open source Apache Hadoop project along with a cascade of other new projects created out of massive developer need to capture, store, and process very large datasets.
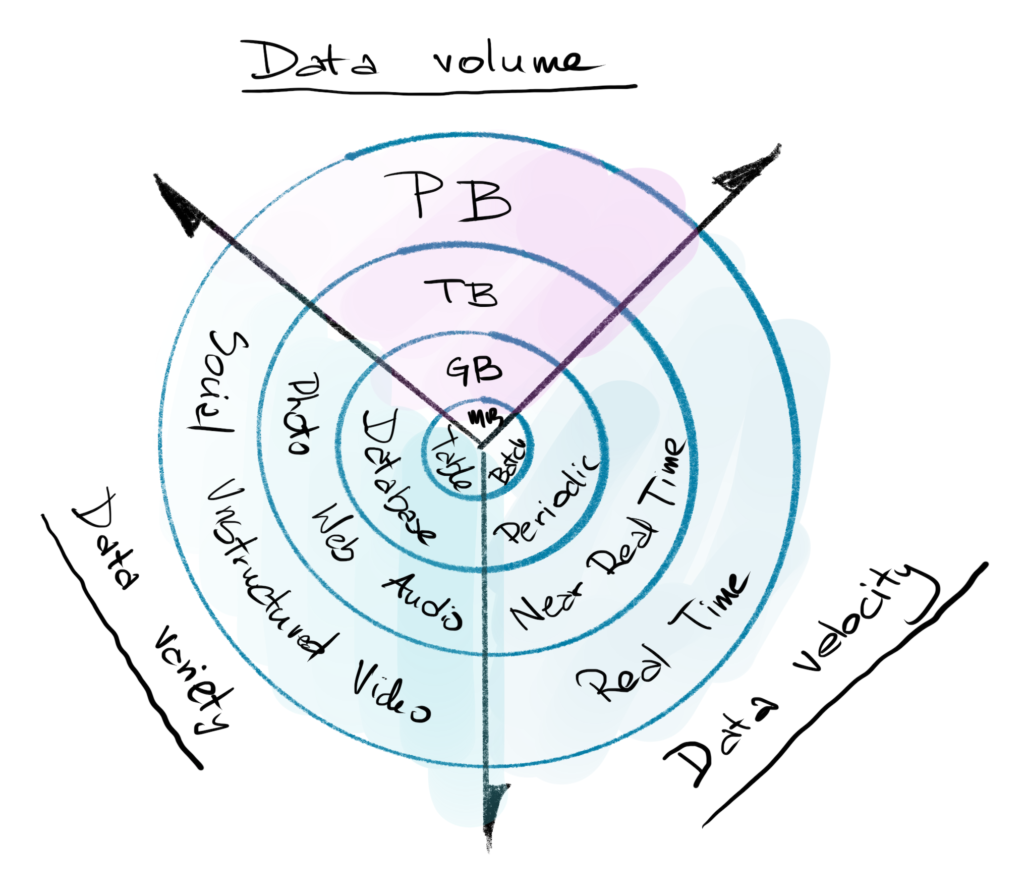
3Vs of Big Data Evolution
While the first MapReduce frameworks like Hadoop were capable of processing large datasets, they were designed for resiliency at scale (by writing the results of each processing step back to distributed storage) more than performance. Apache Spark, first released in 2010, grew to prominence with a new architecture based on fault-tolerant distributed in-memory processing. Spark’s core is implemented in Scala, a programming language for the Java Virtual Machine (JVM). Language bindings for Spark have been implemented for other programming languages such as C# .NET, Java, Python (PySpark), and R (SparkR and sparklyr), which have helped popularize its use across many developer communities.
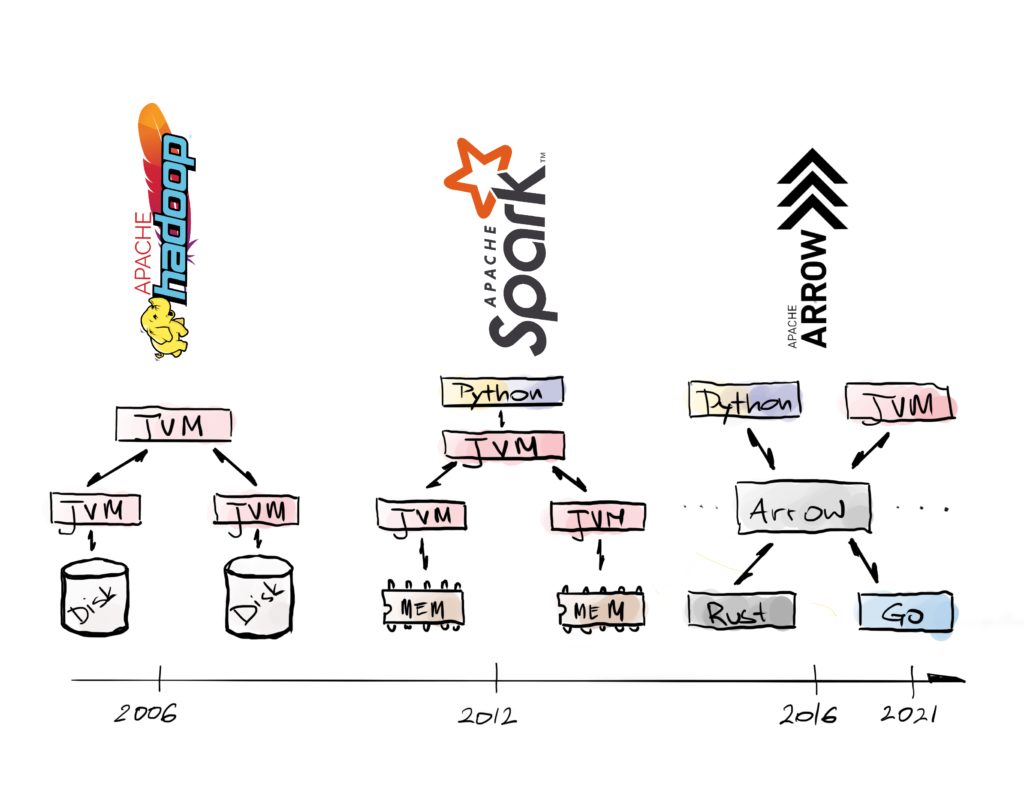
Data Processing Ecosystem Evolution
Source: Voltron Data
Over the last decade, interpreted programming languages like Python and R have grown out of their past niches in scientific computing and academic statistics, respectively, to become the mainstream tools for modern data science, business analytics, and AI. These programming languages have completely dominated data processing work happening at “laptop-scale”. Large-scale data processing frameworks like Hadoop and Spark offered programming interfaces for interpreted languages like Python, but using these bindings would often result in much worse performance and resource utilization compared with the “native” interfaces running on the JVM.
The performance penalty paid by interpreted languages when using mainstream big data systems is primarily rooted in data interoperability issues. In order to expose data from the core runtime of a Java application to a user’s custom Python function (“user-defined function” or “UDF”), data must be converted into a format that can be sent to Python and then converted into built-in Python objects like lists, dicts, or array-based objects like pandas DataFrames. Worse still, many frameworks, including Spark and Hadoop, originally only provided a value-at-a-time execution model for user-defined functions, where tools like NumPy or pandas are designed to execute an array-at-a-time to avoid Python interpreter overhead. The combination of expensive data conversion and interpreter overhead made many big data frameworks computationally impractical for large-scale data processing in Python.
Apache Spark was able to ameliorate some of the language interoperability pain with Python by introducing Spark DataFrames, a new pandas-like API for Spark SQL which avoids the need to transfer data between the Spark runtime and Python. Unfortunately, any application which needs to make use of Python’s data science or machine learning libraries was out of luck. This presented a difficult choice for data scientists and data engineers: develop faster in Python in exchange for slower, more expensive workloads or rewrite critical workloads in Scala or Java.
The Genesis of Apache Arrow
The origin story for Apache Arrow is a bit like the creation of calculus: independent groups of open source developers all had a “Eureka moment” around the same time in the mid-2010s.
In late 2014, I joined Cloudera and started working closely with the Apache Impala and Apache Kudu teams there led by Marcel Kornacker and Todd Lipcon, respectively. We were interested in building an intuitive and fast developer experience for Python programmers (and pandas users, in particular) on top of large-scale distributed storage and data processing engines. One glaring issue was the absence of a standardized, high-speed column-oriented “data protocol” for transporting data efficiently between engines and programming languages. We didn’t want to create a custom data format for our use case nor use data serialization technology like Google’s Protocol Buffers or Apache Thrift because those introduced too much computational overhead. We began designing a new columnar data format but knew that if it was a primarily Cloudera-led project it might risk not succeeding in the highly political climate of big data open source projects.
At the same time, Julien Le Dem and Jacques Nadeau, respectively co-creators of the Apache Parquet file format and Apache Drill query engine, were exploring a way to turn Drill’s in-memory columnar format used for query execution into an independent open source project. This data format was being used as the basis of Dremio, an open source SQL-based data lake engine, and its adoption would result in faster and more efficient connectivity across different storage and data processing systems in the cloud.
Thankfully, Julien, Marcel, and Todd had all worked together several years prior on designing the Parquet file format, and so we connected and decided to work to solve the problem together rather than launching separate and almost-surely incompatible projects. We had a rapid-fire series of in-person meetings (almost unthinkable now in 2022!) where we started recruiting other open source big data leaders to join us in creating a new project, including Julian Hyde (Apache Calcite), Reynold Xin (Apache Spark), Michael Stack (Apache HBase), and many others.
After launching Apache Arrow as a top-level project in The Apache Software Foundation in 2016, we have worked to make Arrow the go-to project for data analytics systems that need to move and process data fast. Since then, the project has become the de facto standard for efficient in-memory columnar analytics and low-overhead data transport, with support for more than 10 programming languages. Beyond providing an in-memory data format and protocols for interoperability, we have created an expansive toolbox of modular computing libraries to provide a strong foundation for the next generation of analytical computing systems.
Only a year after launching the Arrow project, working with my new colleagues at Two Sigma and collaborators from IBM, we were able to accelerate PySpark use with Arrow, achieving 10-100X performance improvements in some cases and significantly improving the experience of using Python and pandas with Apache Spark. It was exciting to see our vision for a faster and more interoperable future start to come true.
In 2018, I formed Ursa Labs in partnership with RStudio and Two Sigma as a not-for-profit industry consortium with the mission to make Arrow a robust computing foundation for the next generation of data science tools. My involvement in Arrow, aside from addressing data interoperability issues, had also been intended to address problems of memory management and in-memory computing efficiency on modern hardware. We were fortunate to have additional sponsorship from NVIDIA, Intel, G-Research, Bloomberg, ODSC, and OneSixtyTwo Technologies.
After more than 4 years of Apache Arrow development, it became clear to us that catalyzing the next stage of Arrow’s growth and impact in businesses would take a larger investment of capital than what could be obtained through industry sponsorships. In late 2020, we decided to spin the Ursa Labs team out of RStudio (which has provided most of the funding and operational support for Ursa Labs) to form a for-profit company, Ursa Computing, and raised a venture round in late 2020. Not long after, in early 2021 we had the opportunity to join forces with innovators in GPU analytics on Arrow, BlazingSQL and leadership from RAPIDS, to form a united Arrow-native computing company, Voltron Data. Ursa Labs has become Voltron Data Labs, a team within Voltron Data, with the ongoing mission of growing and supporting the Arrow ecosystem while upholding the open and transparent governance model of the Apache Way.
Apache Project Growth
Today the Arrow developer community has grown to over 700 individuals with 67 of them having commit access. We are driven by creating cross-language open standards and building modular software components to reduce system complexity while improving performance and efficiency. We have been thinking about the project as a software development toolkit designed to enable developers to unlock the benefits of Apache Arrow’s in-memory format and to also solve the first- and second-order problems (like reading Parquet files from cloud storage and then doing some in-memory analytical processing) that go along with that. Without a trusted, batteries-included software stack to build Arrow-enabled computing applications to go with it, Arrow’s columnar format would serve only in essence as an alternative file format.
Most recently, having made the Arrow columnar format and protocols stable for production use, the community has been focused on providing fast Arrow-native computing components. This work has been most active in C++ and Rust. Using the query engine projects in these languages (DataFusion for Rust and as-yet-unnamed C++ subproject), you can easily add embedded Arrow-native columnar data processing to your application. This could include workloads that you might otherwise express with SQL or with data frame libraries like pandas or dplyr. New high-performance data frame libraries like polars are being built as Arrow-native from the start. At Voltron Data we are actively working to make these capabilities available seamlessly to Python and R programmers.
One of the compelling reasons for the project to adopt Arrow’s data interoperability protocols is to reap the future benefits of simple and fast connectivity with any other project that can also “speak” Arrow. Early adopters had to take a leap of faith that this would be the case, and it has paid enormous dividends. Now, any project which can read and write Arrow has a fast path to connect to data frame libraries (like pandas and R) and many machine learning systems (PyTorch, TensorFlow, Hugging Face).
Arrow contributors have expanded the project’s capabilities by collaborating closely with other open source projects. Recently, work with DuckDB Labs enabled seamless querying using DuckDB as an embedded execution engine. R or Python are now able to seamlessly query their Arrow data using DuckDB either using data frame-like APIs (like dplyr) or SQL. This integration was enabled by Arrow’s C data interface.
An important part of bringing about wider Arrow adoption is making it easier to use Arrow’s binary format in data services and distributed systems. Since non-trivial middleware code is needed to use the Arrow protocol optimally with a general-purpose data services framework like gRPC or Apache Thrift, the community has developed Flight, a developer framework and client-server protocol for Arrow-native data services. Flight provides high-level libraries for implementing server and client logic while using the industry-standard gRPC library for its internal communications. By eliminating unnecessary data serialization through the use of a common in-memory format in both the client and server, users can achieve levels of data throughput (multiple gigabytes per second in some cases) previously inconceivable in a language-independent protocol. Flight libraries are now available in many of the Arrow language libraries (C++, Python, R, Java, Rust, Go), with more languages surely to be added in the future.
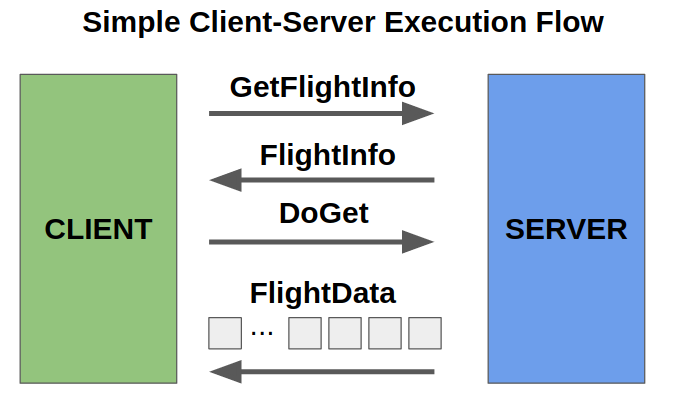
Source: https://arrow.apache.org/img/20191014_flight_simple.png
Databases are some of the most ubiquitous data services, and standard database interfaces like ODBC and JDBC are designed for interoperability and compatibility but not at all for speed. Flight thus brings the possibility to have the best of both worlds: interoperability without compromising on performance. However, Flight as a developer framework and protocol does not have any built-in notions of how SQL databases work, including things like user sessions, the lifecycle of executing a query, or prepared statements. There is also a risk that each database system will implement its Flight server a little bit differently so that users have to use a different Flight client to access each kind of database. To solve these problems – client-server standardization for SQL databases and high level feature-parity with ODBC and JDBC – a Flight application extension called Flight SQL has been created. Now, database developers can implement a common Flight SQL server and users will be able to use a standard Flight SQL client to access any Flight SQL-enabled database.
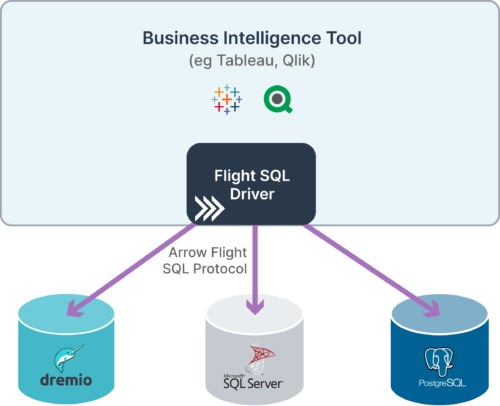
Source: https://www.dremio.com/subsurface/arrow-flight-sql-a-universal-jdbc-driver
The Growth of the Apache Arrow Ecosystem and Adoption
The growth of the Arrow project and its ecosystem has been powered by the success of its early adopters. Arrow has, by and large, become the standard tool for Python users to interact with datasets stored in file formats like Parquet. As mentioned above, early in the project we worked with the Spark community to accelerate PySpark with faster data transfer to pandas using Arrow. On the heels of some of these early success stories, many other projects have adopted Arrow to enable faster interoperability and in-memory processing, in many cases deleting prior custom-built solutions.
By adopting Arrow for data transport, Streamlit was able to delete custom code while substantially improving application performance. Streamlit’s legacy serialization framework was based on Protocol Buffers and was used to send tabular data from a Python backend to a JavaScript frontend. By replacing the custom serializer with Arrow, Streamlit achieved 15x better performance and was able to simplify their codebase by using an off-the-shelf solution.
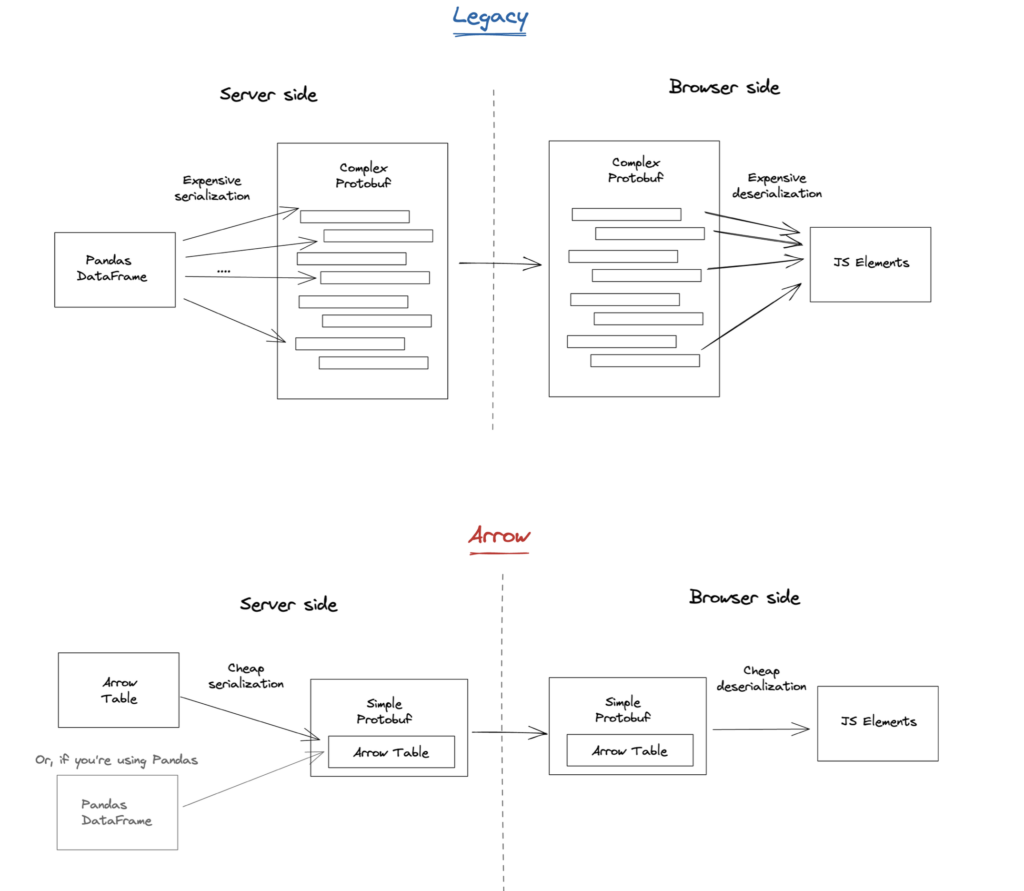
Source: https://blog.streamlit.io/content/images/2021/07/legacy-vs-arrow-2-1.png#shadow
Dremio has been built from the ground up with Apache Arrow at its core. Co-founded by Jacques Nadeau, Dremio is a distributed query engine for data lakes. Dremio developed an LLVM-based, just-in-time expression compiler called Gandiva (now a part of the Arrow project) that generates efficient machine code for executing against Arrow columnar memory. This enables faster performance versus interpreted expressions executed in the JVM.
Recently, Databricks released a Cloud Fetch connector to connect business intelligence tools (like Tableau or Power BI) with data stored in the cloud. Historically, the speed of the data retrieval from traditional data warehouses was limited by the speed of fetching data on a single thread from a SQL endpoint. This limited the usefulness of interactive data exploration tools. Cloud Fetch uses the Arrow wire protocol to stream data in parallel from cloud storage, yielding up to a 12x performance improvement over traditional approaches.
These are just a few examples of projects that use parts of the Arrow project to accelerate data movement or in-memory processes. As more projects become Arrow-enabled, users will derive compounding efficiency benefits. For example, after Snowflake implemented retrieving data from their systems in an Arrow format, their Python and JDBC clients saw a data retrieval speedup of up to 5x. This not only made Snowflake queries run faster but has allowed products that integrate with Snowflake to run faster as well. For example, Tellius, an AI-powered analytics platform, was able to accelerate their integration with Snowflake by 3x using Arrow versus the previous implementation.
The Community
Apache Arrow’s popularity is constantly growing. In fact, PyArrow, Arrow’s Python library, was downloaded 46 million times in January 2022, almost 8 million more downloads than in October 2021, the previous record. We expect this trend to continue as more and more projects adopt Arrow as a dependency.
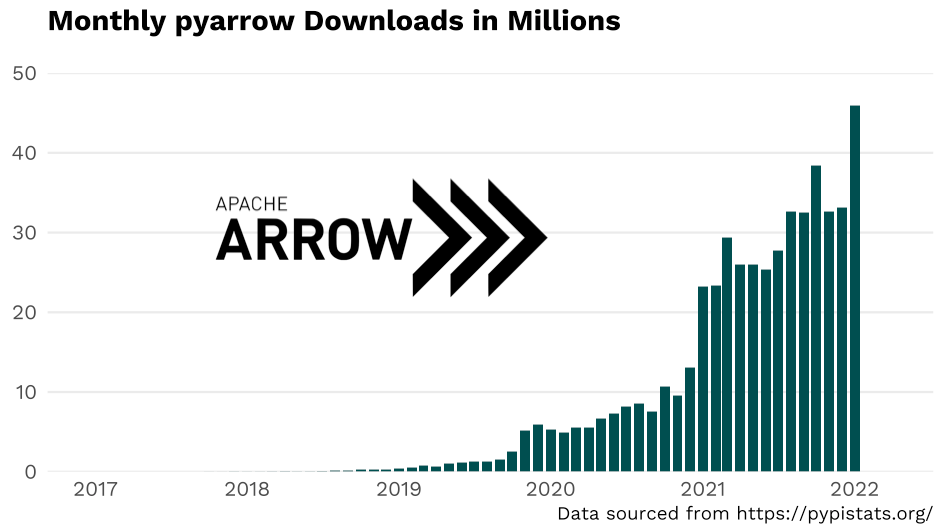
Source: https://pypistats.org/, Voltron Data
Arrow provides a robust foundation for data transport, high-speed access to binary files like Parquet, and rapidly-developing computing engines. It has taken many years of work and a large community to make this possible. Over the last 6 years, the Arrow developer community has grown Apache Arrow’s community considerably: 676 unique developers contributed to the project since its initial release in 2016, with 105 contributors having worked on the Arrow 7.0.0 release.
Like all projects in The Apache Software Foundation, we follow the Apache Way which is a framework for open and transparent open source project governance. Project discussions and decision-making must take place in public, like on mailing lists or on GitHub. Contributors engage as individuals, not as representatives of the companies they work for. By conducting all project business in public, we can maintain an inclusive and professional atmosphere welcoming diverse perspectives from contributors all around the world. The Apache Way values many kinds of contributions: answering user questions, triaging bug reports, and writing documentation are valued just as much as making pull requests. The main developer mailing list is dev@arrow.apache.org.
After working consistently in the project over a period of time, a contributor may be promoted to be a “committer” (who has the write access to the project git repositories) through a vote by the Project Management Committee (PMC). Committers who have demonstrated a commitment to growing and steering the project community may later be promoted to join the PMC. The PMC members are the project steering committee and have a binding vote on releases and other major decisions in the project. There are currently 67 committers and 38 PMC members.
The Future
As the Arrow developer community grows, so does the project scope. The project started six years ago to design a language-independent standard for representing column-oriented data and a binary protocol for moving it between applications. Since then, the project has steadily grown to provide a batteries-included development toolbox to simplify building high-performance analytics applications that involve processing large datasets. We expect Arrow to be a critical component of next-generation big data systems.
We expect work on open standards and interfaces to continue to unite and simplify the analytical computing ecosystem. We are involved with Substrait, a new open source framework to provide a standardized intermediate query language (lower level than SQL) to connect frontend user interfaces like SQL or data frame libraries with backend analytical computing engines. Substrait was founded by Arrow project co-creator Jacques Nadeau and is growing fast. We think that this new project will make it easier to evolve programming language interfaces with analytical computing from the execution engines that power them.
Join Us!
Growing the Apache Arrow project is a big part of our mission at Voltron Data! We look forward to continuing to work with the community to move the ecosystem forward. You can subscribe to our newsletter to stay informed and consider following us on Twitter @voltrondata for more news. You can also explore Voltron Data Enterprise Support subscription options designed to help developers and companies working in the Apache Arrow Ecosystem.
Previous Article

Keep up with us


