Comparing Performance of ADBC and JDBC in Python for Arrow Flight SQL
By
P
Philip MooreandK
Kae SuarezAuthor(s):
P
Philip MooreK
Kae SuarezPublished: May 9, 2023
6 min read
TL;DR Python is the language of data science. Using Arrow Database Connectivity (ADBC) simplifies your stack and supports optimization by removing the complexities that come with Java by letting you keep your workflow in Python.
Python is frequently used as the language to organize compute and data while connected to a powerful database backend to handle execution — such as one that uses Arrow Flight SQL. Until recently, to connect to Flight SQL from Python, you needed either the Arrow JDBC driver or to develop your own bindings. Given the engineer hours and expertise needed to write these bindings, JDBC was the only reasonable way to access Flight SQL. However, to use JDBC, users needed Java in their stack, which required the shuffling of data between languages.
The recent release of the Arrow Database Connectivity (ADBC) driver enables you to stay in Python as you connect to your database, cutting down on the complexity of your stack and enhancing performance by not requiring communication between languages.
Running a Flight SQL server for use with JDBC or ADBC has never been easier, as we demonstrated in a previous blog post. Using the code from there to set up the server, we’ve set up a benchmark to compare the use of JDBC and ADBC from Python, connecting to Flight SQL.
We have provided the code and setup for the benchmarks on GitHub here. You can clone the repo and run them on your own system by following the steps in the README.
This benchmark is focused on the speed of data collection and transmission of data from an underlying database to Python. The reasoning behind this choice is that performance variance between connectors is most likely to arise in workloads that rely on high bandwidth, and complexity beyond this is unnecessary. We’ll use three setups overall:
- JDBC: Simple setup with Py4J
- JDBC: Optimized setup with built jar
- ADBC: Simple setup with standard Python package
Source data
For our test, we will use a 1 GB TPC-H dataset, specifically the “lineitem” table which represents customer order line item facts as part of a snowflake schema.
For TPC-H Scale Factor 1 - the “lineitem” table has 6,001,215 rows of data, representing about 720MB of CSV data, or 258MB of Parquet data.
Test scenario
For all of the benchmark tests, we run the same SQL statement from Python in 10 loops and calculate the average run time. The statement fetches ALL rows from the “lineitem” table - here it is:
sql
SELECT l_orderkey
, l_partkey
, l_suppkey
, l_linenumber
, l_quantity
, CAST (l_extendedprice AS float) AS l_extendedprice
, CAST (l_discount AS float) AS l_discount
, CAST (l_tax AS float) AS l_tax
, l_returnflag
, l_linestatus
, l_shipdate
, l_commitdate
, l_receiptdate
, l_shipinstruct
, l_shipmode
, l_comment
FROM lineitemFlight SQL server
For the provided results, the Flight SQL server will be running locally in Docker on a laptop (2021 Apple MacBook Pro with M1 Pro CPU and 32GB of RAM). It is using a DuckDB version 0.7.1 back-end, TLS for encryption of data transfer to/from the client, and Apache Arrow 11.0.0. See this repo for more info on the Flight SQL server.
Client
For the client, we’ll test both the Arrow JDBC and ADBC drivers using Python 3.11 on the same laptop as the Flight SQL server.
JDBC setup
JDBC requires Java. We’re using Python libraries: jpype and py4j, which allow you to use the JVM from Python.
JDBC driver benchmark tests
For the JDBC driver, we are running two benchmark tests:
1: benchmark_jdbc_py4j.py: Basic Py4j with the regular Arrow JDBC Driver version 11.0.0 - where we query the lineitem table, and use the default JDBC behavior of deserializing data from Arrow format to JDBC’s row-based format. Note: our test may not represent the best setup for Py4J and JDBC - if you find a better way to run this scenario - please let us know via a Pull Request!
TL;DR We include the py4j scenario because it represents the easiest route to interact with Flight SQL over JDBC from Python.
2: benchmark_jdbc_super_jar.py: A performance-enhanced setup that requires we build a specialized jar that combines the Arrow JDBC driver with Arrow Java libraries, thus cutting out most costs from inter-language communication. This special setup was inspired by this article by Uwe Korn. The “super-jar” was built one time using this script. For ease of use, we just put the jar artifact directly in the repo so that you shouldn’t have to build it, but feel free to do so.
ADBC setup
Using the new Python ADBC driver for Flight SQL is quite simple, just install it with pip (as documented in the README.md). We run script: benchmark_adbc.py for the ADBC benchmark.
Test results
After running the tests, we found that the new ADBC driver for Flight SQL performs best. Here are the performance numbers:
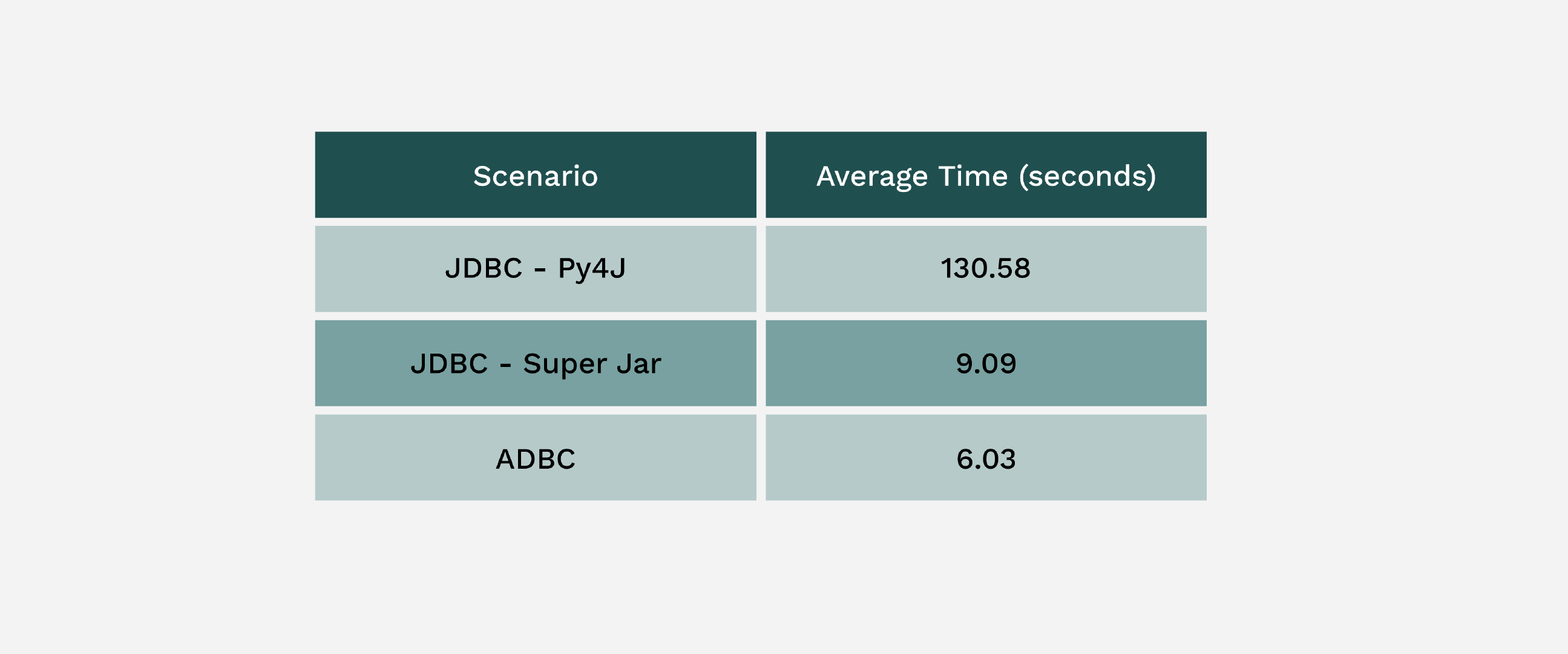
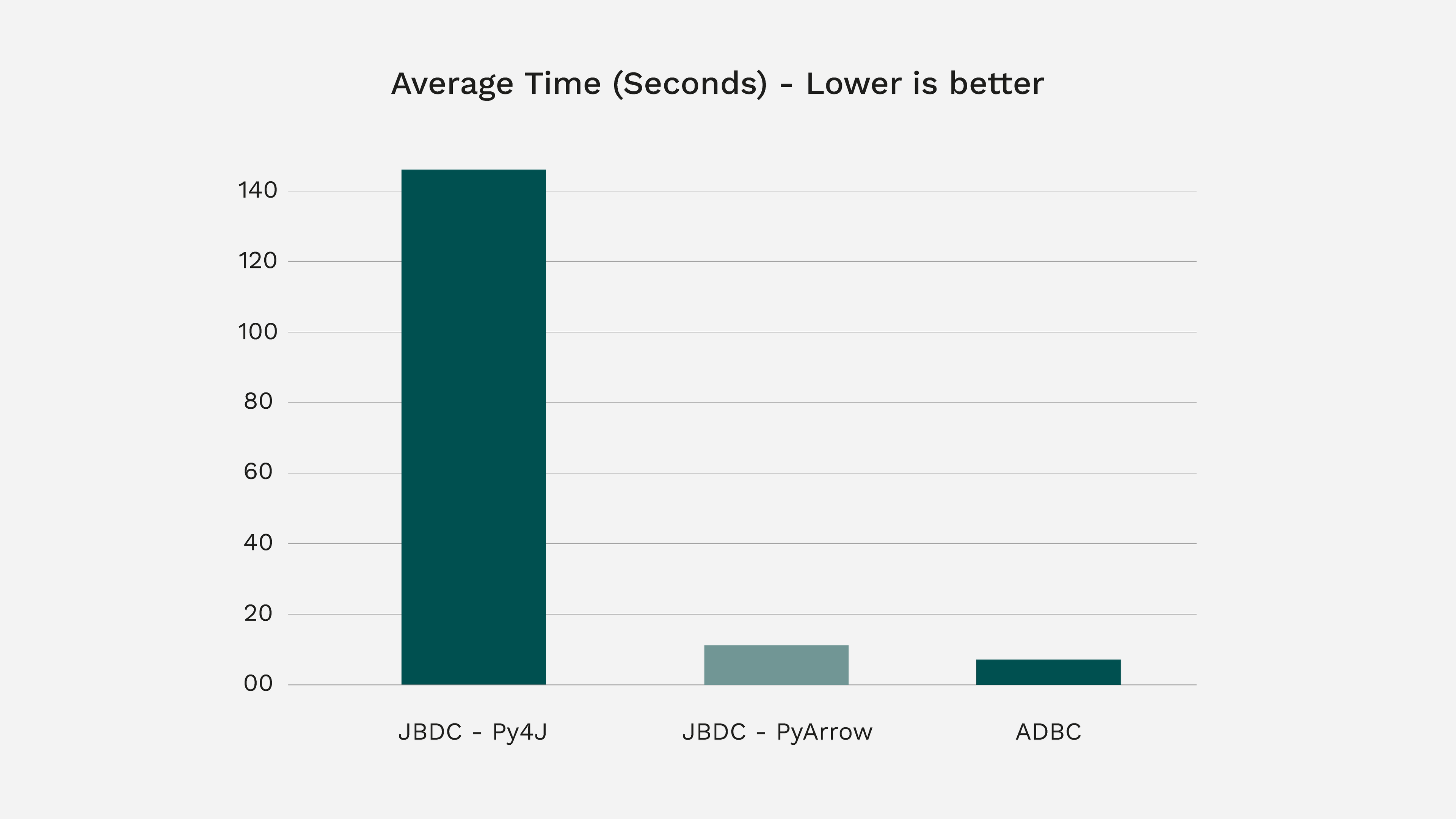
As you can see, ADBC performs over 33% faster than a very optimized JDBC setup, and over 21x faster than the default JDBC configuration! Further, the Python code complexity is much less for ADBC and works out of the box with minimal setup.
Here is the distribution of timings:
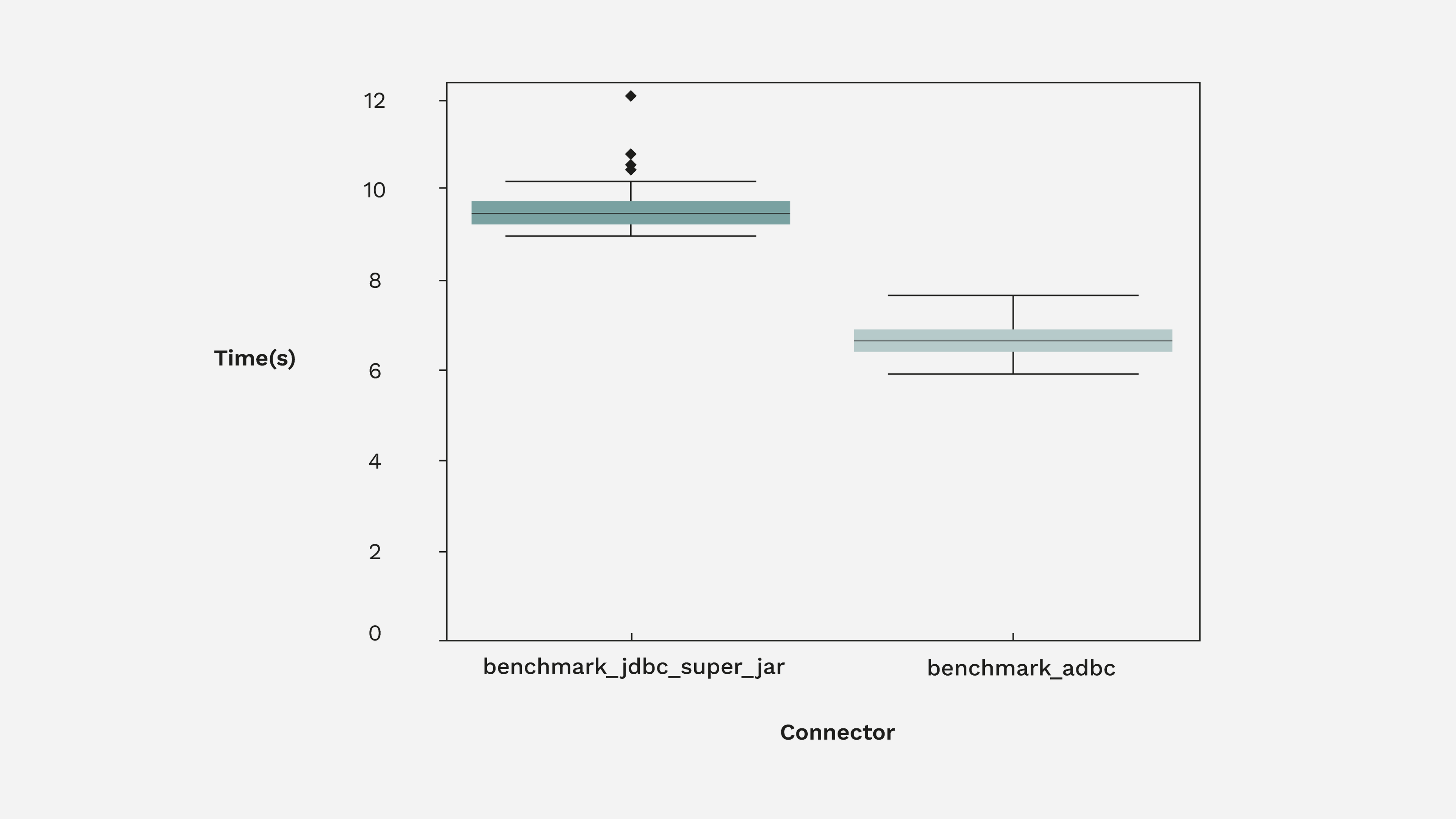
TL;DR It is important to note that both the Flight SQL JDBC and ADBC drivers use the Arrow Flight SQL transport protocol. The JDBC driver, however, must perform the additional steps of transposing the data as well as copying it from the JVM to Python. The fastest way to do something is to not do it, so ADBC performs better in Python as expected.
Summary
ADBC is simpler to use from Python, and performs noticeably better than JDBC. Pulling in the entirety of Java as a dependency demands engineer hours and performance costs. These vital resources can be better spent gathering important insights. Python’s usability and rich ecosystem enable a variety of workflows, and the ADBC driver enables you to use it with your databases without sacrificing performance or usability.
Voltron Data helps enterprises accelerate success with the Arrow Ecosystem using standards like ADBC, Arrow Flight, Ibis, Substrait, and more. See what our Enterprise Support offering can do for you.
Photo by Danist Soh
Previous Article

Keep up with us


