Turns Out Compression Matters and It Delivers Huge Gains
By Joost Hoozemans,
Joost Hoozemans,  William Malpicaand
William Malpicaand Mike Beaumont
Mike Beaumont
Author(s):
Published: September 12, 2025
5 min read
This post shares new Theseus performance results, building on benchmarks from June 2025. In the latest Theseus release, we eliminated a global synchronization bottleneck in the compression path, introduced a safer memory strategy, and standardized on BITCOMP. Across TPC-H, we’re seeing 1.3X end-to-end speedup, with some queries over 3X faster.
We found a flaw
In a recently published paper on Theseus, we treated compression as a second-order knob, mainly useful when network bandwidth is the bottleneck and often worth disabling once links get fast enough. We framed it as a tradeoff that can add latency and consume compute. (see our Networking Executor discussion and the configuration study). Over the past few months, our engineers revisited our assumptions and discovered an implementation flaw. By moving work off the implicit default stream, isolating memory with skip-safe policies, and standardizing on BITCOMP, we turned compression into a consistent source of performance gains. But before we amend our paper, here’s a quick blog post to explain the new compression features and show new results.
A New Approach to Compression
Compression kernels no longer stack up on CUDA’s default stream. Previously, work from multiple Theseus threads, all hitting the same default stream, acted like a global synchronization point. However, decoupling this removes that chokepoint and unlocks concurrency. We implemented a single-mempool reservation approach, in which compression allocates from the global pool but automatically skips compression while the Out of Memory (OOM) handler resolves pressure. This avoids thrashing. For the algorithm, we left room for per-datatype, compression type selection, but are defaulting to BITCOMP as it performed well across data types with a modest footprint. Finally, the compression manager’s lifecycle was tuned: keeping the pool but instructing managers to deallocate between calls to reduce the memory consumption overhead, since not all managers would be used all the time. This resulted in increased stability and performance.
Updated Cloud Performance Results
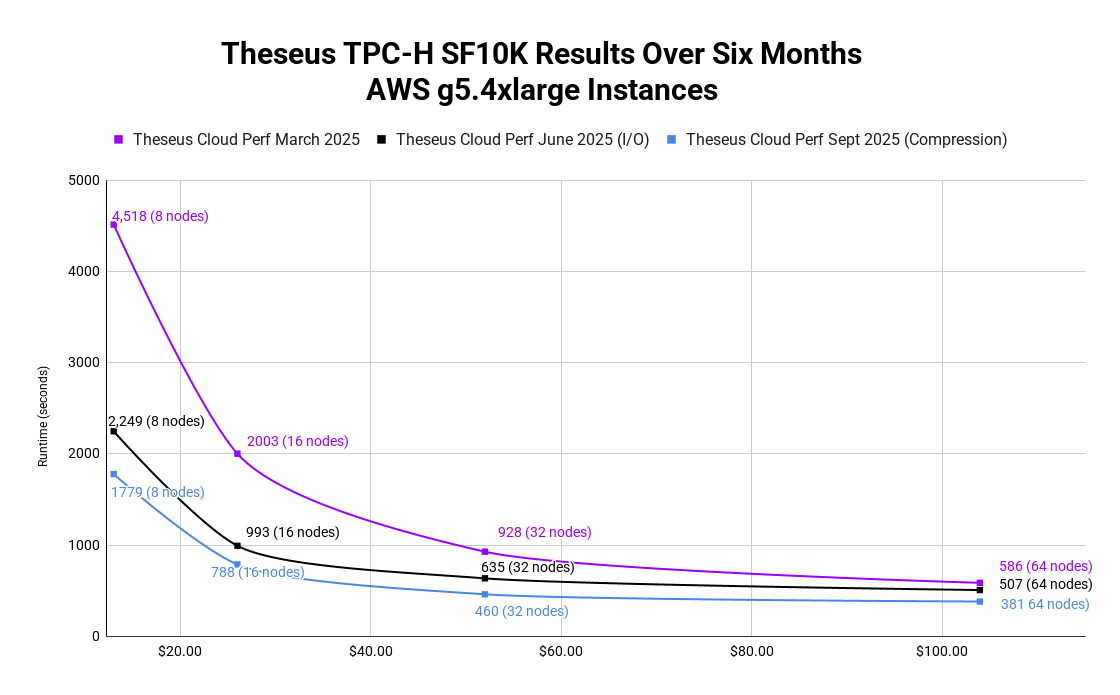
In June, we released AWS performance benchmarks, adding metadata caching, pre-fetching, and the new RESTful datasource to accelerate I/O. Refer to the Theseus Cloud Perf 6/25 (I/O) results in the chart below. This improved our TPC-H performance on the same infrastructure from 4518 seconds to 2249 seconds, a 2X improvement on the same cloud environment.
We’ve rerun these same benchmarks using the current Theseus release, which includes the latest compression work, delivering yet another 1.3X improvement from 2249 seconds to 1779 seconds, with a few queries showing over 3X gains. Refer to the Theseus Cloud Perf 9/25 (Compression) results in the chart below.
Updated On-Premises Performance Results
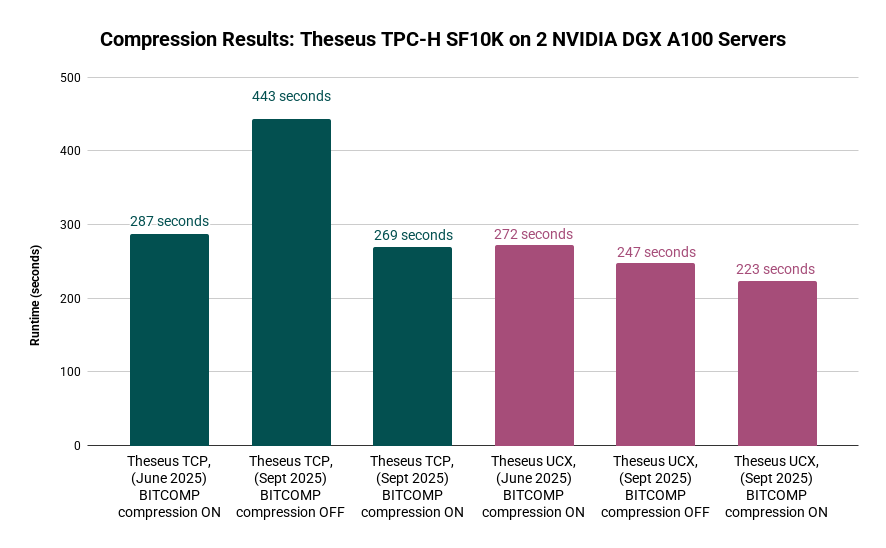
On our on-premises NVIDIA DGX A100 cluster, we can either use standard TCP connections between servers or take advantage of a high-speed RDMA over InfiniBand connection. On the slower TCP network, compression makes a significant difference. Back in June, enabling compression over TCP delivered a 1.5X performance improvement; with our new enhanced compression architecture, that gain has increased to 1.6X. On the high-speed RDMA InfiniBand network via UCX, the story was different. In June, compression actually slowed performance by about 10%, since the compression overhead was not offset by the time savings in moving those bytes over the fast Infiniband network. With the new system, however, compression overhead is much lower, and we now see a 1.1X improvement over RDMA. The chart below shows TPC-H SF10K results on our cluster.
Wrap-up
By eliminating a global synchronization bottleneck in the compression path, introducing a safer memory strategy, and standardizing on BITCOMP, Theseus continues to advance cloud-based analytics performance, resulting in a 1.3X performance improvement. These enhancements empower data engineers to run GPU-accelerated queries at scale with minimal bottlenecks across any major cloud provider. We look forward to sharing additional benchmarks as more PRs are pushed and features land. Learn More

Keep up with us

