The Race to Build a Distributed GPU Runtime
By Mike Beaumont
Mike Beaumont
Author(s):
Published: September 3, 2025
11 min read
For a decade, GPUs have delivered breathtaking data processing speedups. However, data is growing far beyond the capacity of a single GPU server. When your work drifts beyond GPU local memory or VRAM (e.g., HBM and GDDR), hidden costs of inefficiencies show up: spilling to host, shuffling over networks, and idling accelerators. Before jumping straight into the latest distributed computing effort underway at NVIDIA and AMD, let’s quickly level set on what distributed computing is, how it works, and why it's hard.
Distributed computing and runtimes on GPUs
Distributed computing coordinates computational tasks across datacenters and server clusters with GPUs, CPUs, memory tiers, storage, and networks to execute a single job faster or at a larger scale than any one node can handle. When a single server can’t hold or process your data, you split the work across several servers and run pieces in parallel, and if the job requires true distributed algorithms, not just trivially parallelizable independent tasks, then performant data movement is mandatory. Datasets and models have outgrown a single GPU’s memory. Once that happens, speed is limited less by raw compute and more by how fast you can move data between GPUs, CPUs, storage, and the network. In other words, at a datacenter scale, the bottleneck is data movement, not FLOPS.
A distributed runtime is the system software that makes a cluster behave like one computer. It plans the job, decides where each piece of work should run, and moves data so GPUs don’t sit idle. A good runtime places tasks where the data already is (or soon will be), overlaps compute with I/O so kernels keep running while bytes are fetched, chooses efficient paths for those bytes (NVLink, InfiniBand/RDMA, Ethernet; compressed or not), manages multiple memory tiers on purpose (GPU memory, pinned host RAM, NVMe, object storage), and keeps throughput steady even when some workers slow down or fail.
This is hard because real datasets are skewed, so a few partitions can dominate wall-clock time unless the runtime detects and mitigates them. Networks are shared and imperfect, which means congestion control, backpressure, and compression decisions matter as much as kernel choice. Multi-tier memory introduces fragmentation and eviction challenges that simple alloc/free strategies can’t handle. Heterogeneous infrastructure with mixed GPU generations, interconnects, and cloud object stores can hurt static plans and force the runtime to adapt in flight. If the runtime guesses wrong on partition sizes, placement, or prefetching, GPUs stall waiting for inputs. At a datacenter scale, lots of small stalls add up to big delays. And delays are lost revenues and productivity.
NVIDIA is serious about distributed runtimes
NVIDIA has been trying to solve this for over a decade, and AMD is ramping up. NVIDIA initiatives include (but are not limited to) GPU-accelerated Spark with UCX shuffle and explicit spill controls, Dask-powered multi-node RAPIDS, and “drop-in distributed” Python via Legate/Legion, all woven together by Magnum IO’s UCX and GPUDirect Storage. There’s even some mystery around NVIDIA’s latest distributed project called CUDA DTX, mentioned as a roadmap item at NVIDIA GTC 2025. CUDA Distributed eXecution or DTX is a single runtime running across hundreds of thousands of GPUs. While it’s clearly still in development, it again points to how NVIDIA is trying to solve one of the toughest challenges in accelerated computing = moving data at scale.
Examples of NVIDIA’s distributed runtimes
| Distributed Runtime | Description |
|---|---|
| RAPIDS + Dask (multi-GPU / multi-node) | dask-cuDF targets cluster execution so DataFrame and ETL pipelines scale across GPUs and nodes. |
| RAPIDS Accelerator for Apache Spark | Replaces CPU operators with GPU ones and ships an accelerated UCX-based shuffle for GPU-to-GPU and RDMA networking. |
| Legate / Legion (“drop-in distributed”) | Legion is a data-centric runtime; Legate layers familiar Python APIs so NumPy/Pandas-style code scales without changes. |
| Magnum IO (UCX / GPUDirect RDMA & Storage) | End-to-end data-movement stack; UCX for shuffle/transport and GDS to avoid CPU bounce buffers. |
| Dynamo Distributed Runtime | Rust core providing distributed communication/coordination between frontends, routers, and workers for multi-node inference. |
Why is NVIDIA making this investment?
In short, it’s to create a software moat. CUDA-X is NVIDIA’s collection of GPU-accelerated libraries, SDKs, and cloud microservices built on CUDA, covering data processing, AI, and HPC. It’s the middle layer that frameworks call, so code runs fast on NVIDIA’s GPUs. CUDA-X is the heart of the NVIDIA full-stack strategy, and it’s why it’s NVIDIA CEO Jensen Huang’s favorite slide at GTC. But if CUDA-X is the core of NVIDIA’s software, distributed runtimes are the systems that make it successful at datacenter scale. While CUDA-X makes operations fast, distributed runtimes make systems fast.
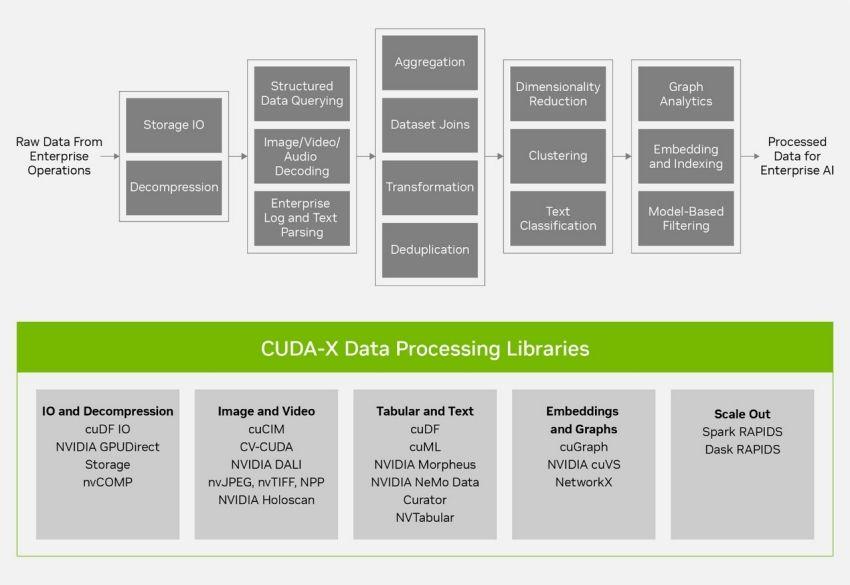
CUDA-X libraries depend on well-tuned CUDA primitives and kernels to generate performance, but at the cluster scale, it’s data movement that matters most. That’s the job of distributed runtimes, the system layer that decides where CUDA-X operations run and how data moves across GPUs, nodes, over the network, and to and from storage. Consider operations like shuffles, joins, KV-cache transfers, and prefetch/spill between HBM, host RAM, NVMe, and object stores, plus congestion on NVLink/InfiniBand/Ethernet. It’s the coordination of work that gets complicated, and as data processing deployments grow to multi-node and multi-rack, runtime decisions increasingly determine end-to-end performance. While this post isn’t going to answer the question “Why GPUs are fast at data processing,” we invite our readers to check out our previous article “Data Analytics are Faster on GPUs - Here’s Why” for a deeper dive.
RAPIDS is the core of CUDA-X Data Processing
There’s a strong argument to be made that RAPIDS cuDF/RAPIDS libcudf drives NVIDIA’s CUDA-X Data Processing stack, from ETL (NVTabular) and SQL (BlazingSQL) to MLOps/security (Morpheus) and Spark acceleration (cuDF-Java). Over the last seven years, libcudf has catalyzed much of NVIDIA’s data-processing software development, letting higher-level libraries reuse the same columnar primitives, networking, and I/O paths.
sql
libcudf (C++ GPU DataFrame core)
├─ cuDF (Python)
│ ├─ dask-cuDF (distributed)
│ ├─ cuML (accepts/returns cuDF)
│ ├─ cuGraph (operates on cuDF)
│ └─ cuSpatial (Python integrates with cuDF)
│ └─ ...many more
└─ cuDF-Java (JNI bindings)
└─ RAPIDS Accelerator for Apache Spark (shNVIDIA leverages the RAPIDS cuDF technology stack broadly throughout its CUDA-X Data Processing libraries and product suites (e.g., NVIDIA Morpheus for cybersecurity, NVIDIA Merlin for recommender systems, and NVIDIA NeMo for AI Agents). These libraries leverage C++ libcuDF primitives to minimize overhead and optimize jobs to run efficiently on GPU hardware.
Examples of CUDA-X data processing libraries that depend on RAPIDS cuDF
| CUDA-X Library | Application Area | Depends on RAPIDS cuDF? | Reference Documentation |
|---|---|---|---|
| cuML | Machine learning | yes | Docs |
| cuGraph | Graph analytics | yes | Docs |
| cuSpatial | Geospatial analytics | yes | Docs |
| cuOpt | Decision optimization | yes | Docs |
| Morpheus | Cybersecurity | yes | Docs |
| Merlin/NVTabular | Recommender systems | yes | Docs |
| NeMo | AI Agents | yes | Docs |
| cuSignal | Signals intelligence | yes | Docs |
AMD is doing the same thing
AMD is recreating the CUDA-X/RAPIDS pattern via HIP and ROCm-DS. HIP provides source-level compatibility with CUDA, and hipDF aims to mirror the RAPIDS cuDF API so distributed runtimes can target AMD GPUs with minimal changes. Today, hipDF is still early with limited operator coverage, no query-plan optimization, or real-world validation. In its current state, AMD’s hipDF doesn’t pose a threat to NVIDIA’s CUDA-X accelerated data processing market share, but if it continues to invest in the ROCm-DS ecosystem and determines a good distributed compute strategy, then it may erode NVIDIA's moat.
Theseus treats data movement as a first-class citizen
Voltron Data’s Theseus is designed “data-movement first,” so performance does not degrade significantly beyond GPU memory like other systems. The engineers who helped stand up RAPIDS and BlazingSQL, responsible for the columnar/cuDF work, the CI/CD and packaging that made RAPIDS usable, and the early distributed SQL engine experience, are the same people who founded Voltron Data and built Theseus. We know exactly where NVIDIA’s single-node strengths end and where distributed runtimes begin to struggle. The recent Theseus paper ”Theseus: A Distributed and Scalable GPU-Accelerated Query Processing Platform Optimized for Efficient Data Movement,” states the core challenge: at OLAP scale, most of the hard problems are when, where, and how to move data among GPU, host memory, storage, and the network. If those operations run sequentially, the cost of data motion cancels out the benefit of GPUs. Theseus is designed specifically to hide those latencies while keeping accelerators busy.
Theseus is architected for data movement. Theseus workers run four specialized, asynchronous executors: Compute, Memory, Pre-Load, and Network. This architecture allows I/O, spill/prefetch, and shuffle to happen in parallel with GPU compute. This is not an add-on to an existing CPU runtime; rather, it’s a control plane that treats data movement as a first-class concern. (read the paper)
- Theseus guarantees places for data to live. The Batch Holder abstraction sits on every edge of the DAG, ensuring inputs always have somewhere to reside (GPU→host→storage). Crucially, it enables explicit, proactive movement back to the GPU ahead of kernel launch—an intentional alternative to reactive UVM paging.
- Theseus prefetches the exact bytes. The Pre-Load executor can pull precise Parquet byte ranges and/or pre-materialize inputs in GPU memory so compute never stalls on I/O, separating storage progress from compute progress.
- Theseus makes host memory a fast transit lane. Instead of ad-hoc host allocations, Theseus uses a pool of fixed-size, page-locked buffers that speed device↔host transfers, avoid fragmentation, and double as bounce buffers for network and scan prefetch.
- The Network executor supports TCP and UCX/GPUDirect RDMA, with optional compression because the right answer depends on the interconnect.
Theseus has solved the data movement problem
Theseus is proven at large scale (see benchmarks). On cloud clusters normalized for cost, Theseus beats Databricks Photon at every scale, growing to 4X faster at the largest scale. It also completes TPC-H/DS at 100 TB with as few as two DGX A100 640 GB nodes, i.e., 80X beyond available GPU memory, further evidence that spill and movement are handled deliberately and efficiently. On premises delivered roughly a 2X speedup over baseline by implementing page-locked buffers with the right network settings. In the cloud, a custom object-store datasource plus byte-range preloading slashed runtimes versus a stock S3 reader (read the blog).
Theseus is intentionally built on open columnar standards (Apache Arrow) using a composable runtime philosophy so it can plug into modern planners and APIs without re-engineering the core. While it serves SQL today, it also extends to AI/ML pipelines via UDFs (read The Composable Codex).
Theseus Query Profiler delivers operational visibility. Theseus ships its own profiler/observability so teams can see compute, file I/O, memory tier occupancy, and network usage per stage, with low overhead, making it practical to tune data motion instead of guessing. (webpage, blog series part 1, part 2)
Theseus runs across both NVIDIA and AMD ecosystems. The same movement-first runtime that squeezes NVIDIA clusters is now running on AMD via ROCm-DS/hipDF, with early results and ongoing work to HIP-ify remaining dependencies. That gives customers optionality and gives AMD a ready-made runtime to accelerate its ecosystem, backed by the same team that built much of the NVIDIA stack. (read the blog)
Wrap Up
NVIDIA and AMD are both racing to solve data movement at the cluster scale. Theseus is the first distributed runtime to put movement at the center of scheduling, memory, and I/O, and then prove the payoff with benchmarking results. If you need a distributed runtime for datacenter-scale analytics and AI, one that’s open, composable, and already running on CUDA and ROCm, Theseus is it.

Keep up with us


