Hugging Face Embeddings & Ibis: Create a Custom Search Engine for Your Data
By
M
Marlene MhangamiAuthor(s):
M
Marlene MhangamiPublished: August 31, 2023
8 min read
What Are Embeddings?
An embedding is a numerical representation of a piece of information, for example, text, documents, images, or audio. Through the process of embedding, data is translated into a list of floating point numbers, also known as a vector. One of these vectors is an embedding. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
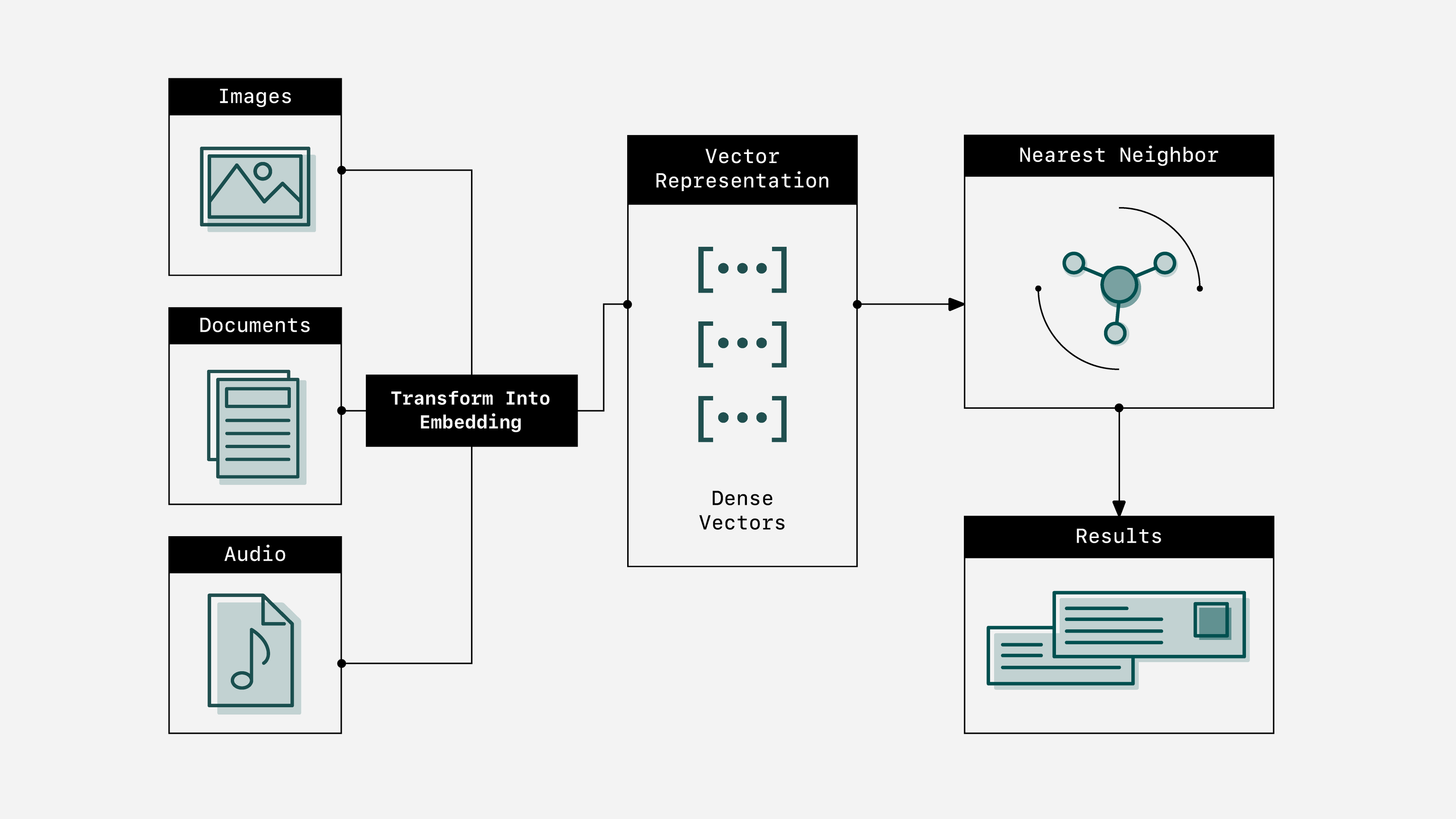
Why Use Embeddings?
When embedded data is represented as numerical vectors, semantically similar inputs are placed close together. This means that embeddings can be used as a powerful tool for various natural language processing tasks such as recommendation systems, anomaly detection, text classification, and more. So how can we turn data into embeddings? Several pre-trained models are available to do the job. In this blog post, we’ll use an embedding model from Hugging Face. Hugging Face is a community and data science platform that provides tools that enable users to build, train and deploy machine learning models based on open source (OS) code and technologies. An advantage of using Hugging Face models is that users don’t have to pay to use their APIs, which can save teams a significant amount of money.
In order to access and clean our data as efficiently as possible we’ll use Ibis — an open source dataframe library that is excellent for pre-processing large datasets and working with machine learning models. When Python data frames are mentioned, pandas usually comes to mind. Although pandas continues to be popular, when working with datasets larger than memory, it struggles and can slow down your workflows or break completely. Choosing Ibis allows you to work with data of any size and makes teams more productive since they don’t need to change their code when scaling up or down. We’ll also use LangChain to connect to the Hugging Face embedding model and I’ll show a quick example of completing the same workflow with an embedding model from OpenAI at the end. Ibis and LangChain work seamlessly together, particularly when composing systems that pull in data from multiple sources and utilize multiple different LLMs. To learn more read my article on this topic here.
Example: Semantic Similarity Search On Amazon Food Reviews
Embeddings preserve the semantic relationships between words which enable algorithms to understand that words like “dog” and “puppy” are closely related, even though they may not be exact matches. We’ll leverage this capability to create a custom search engine for a table containing Amazon food reviews. To get started, we’ll install some key dependencies.
bash
pip install ibis-framework, langchain, tiktoken, spatialNext, let’s jump into a Jupyter Notebook and import Ibis and LangChain and configure the environment.
python
import ibis
import langchain
import os
from ibis import _
# configure ibis
ibis.options.interactive = TrueNow we need to read in the data and clean it so that the reviews can be embedded. You can find the dataset here. The CSV file contains 568,454 food reviews from Amazon users up to October 2012. For demonstration purposes, we’ll grab the first 500 of them. To give the model more context we’ll combine the review summary and review text into one column called combined
python
reviews = ibis.read_csv('Reviews.csv')
#only use the first 500 reviews since this is just an example
reviews = reviews.head(500)
#get the data we need and drop any nulls
reviews = reviews[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]
reviews = reviews.dropna()
#create a column that combines the review summary and its text for better content to embed
reviews = reviews.mutate(combined=("Title: " + _.Summary + "; Content: " + _.Text))
#here's what the table should look like
reviews.head()
Time ┃ ProductId ┃ UserId ┃ Score ┃ Summary ┃ Text ┃ combined ┃
┡━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ int64 │ string │ string │ int64 │ string │ string │ string │
├────────────┼────────────┼────────────────┼───────┼───────────────────────┼──────────────────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────────────────┤
│ 1303862400 │ B001E4KFG0 │ A3SGXH7AUHU8GW │ 5 │ Good Quality Dog Food │ I have bought several of the Vitality canned dog food products and have found t… │ Title: Good Quality Dog Food; Content: I have bought several of the Vitality ca… │
│ 1346976000 │ B00813GRG4 │ A1D87F6ZCVE5NK │ 1 │ Not as Advertised │ Product arrived labeled as Jumbo Salted Peanuts...the peanuts were actually sma… │ Title: Not as Advertised; Content: Product arrived labeled as Jumbo Salted Pean… │
│ 1219017600 │ B000LQOCH0 │ ABXLMWJIXXAIN │ 4 │ "Delight" says it all │ This is a confection that has been around a few centuries. It is a light, pill… │ Title: "Delight" says it all; Content: This is a confection that has been aroun… │
│ 1307923200 │ B000UA0QIQ │ A395BORC6FGVXV │ 2 │ Cough Medicine │ If you are looking for the secret ingredient in Robitussin I believe I have fou… │ Title: Cough Medicine; Content: If you are looking for the secret ingredient in… │
│ 1350777600 │ B006K2ZZ7K │ A1UQRSCLF8GW1T │ 5 │ Great taffy │ Great taffy at a great price. There was a wide assortment of yummy taffy. Del… │ Title: Great taffy; Content: Great taffy at a great price. There was a wide as… │
└────────────┴────────────┴────────────────┴───────┴───────────────────────┴──────────────────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────────────────┘python
┏━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Time ┃ ProductId ┃ UserId ┃ Score ┃ Summary ┃ Text ┃ combined ┃
┡━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ int64 │ string │ string │ int64 │ string │ string │ string │
├────────────┼────────────┼────────────────┼───────┼───────────────────────┼──────────────────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────────────────┤
│ 1303862400 │ B001E4KFG0 │ A3SGXH7AUHU8GW │ 5 │ Good Quality Dog Food │ I have bought several of the Vitality canned dog food products and have found t… │ Title: Good Quality Dog Food; Content: I have bought several of the Vitality ca… │
│ 1346976000 │ B00813GRG4 │ A1D87F6ZCVE5NK │ 1 │ Not as Advertised │ Product arrived labeled as Jumbo Salted Peanuts...the peanuts were actually sma… │ Title: Not as Advertised; Content: Product arrived labeled as Jumbo Salted Pean… │
│ 1219017600 │ B000LQOCH0 │ ABXLMWJIXXAIN │ 4 │ "Delight" says it all │ This is a confection that has been around a few centuries. It is a light, pill… │ Title: "Delight" says it all; Content: This is a confection that has been aroun… │
│ 1307923200 │ B000UA0QIQ │ A395BORC6FGVXV │ 2 │ Cough Medicine │ If you are looking for the secret ingredient in Robitussin I believe I have fou… │ Title: Cough Medicine; Content: If you are looking for the secret ingredient in… │
│ 1350777600 │ B006K2ZZ7K │ A1UQRSCLF8GW1T │ 5 │ Great taffy │ Great taffy at a great price. There was a wide assortment of yummy taffy. Del… │ Title: Great taffy; Content: Great taffy at a great price. There was a wide as… │
└────────────┴────────────┴────────────────┴───────┴───────────────────────┴──────────────────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────────────────┘It’s important to note that when working with model APIs you’re usually given a limit for the number of tokens (words or phrases) the model can take in. To ensure the code runs without errors we will measure how many tokens each review makes and then filter out reviews that surpass the max token length.
python
#remove any reviews that exceed token number these won't be able to be embedded
import tiktoken
# this is the encoding for an example model that we will use.
#It turns the reviews into tokens
embedding_encoding = "cl100k_base"
encoding = tiktoken.get_encoding(embedding_encoding)
# lets set the max tokens to 8000
max_tokens = 8000
## use an Ibis/DuckDB UDF to get the number of tokens each review comes up to
@udf.scalar.python
def num_tokens(s: str) -> int:
phrase = encoding.encode(s)
num_tokens = len(phrase)
return num_tokens
# omit reviews that are too long to embed
reviews = reviews.mutate(n_tokens = lambda x: num_tokens(x.combined))
reviews = reviews.filter(_.n_tokens <= max_tokens)The data is now clean and in good shape to start the embedding process. We can now use LangChain to import and instantiate the embedding model from Hugging Face with this line of code.
python
#using huggingface embeddings
hf_embedding_model = HuggingFaceEmbeddings()We can now create a User Defined Function (UDF) that takes in one of the food reviews and turns it into an embedding using the model we just instantiated. Ibis UDFs enable vectorized computation, which leads to improved performance compared to Python UDFs.
python
#Create an Ibis UDF that allows us to pass the reviews to Hugging Face TO be embedded
@udf.scalar.python
def hf_reviews_to_embeddings(s:str) -> dt.Array('float32'):
embedding = hf_embedding_model.embed_query(s)
return embeddingNext, to run the function on the individual reviews we will use the mutate function to pass each element of the combined column to the function above. This code will create a new column named embeddings that will contain a vector representation of the review returned from the model.
python
hf_embedded_reviews = reviews.mutate(embeddings=lambda t: hf_reviews_to_embeddings(t.combined))Hugging Face generates embeddings from the text that have a length of 768. Here’s what the embedded reviews look like.
python
#hf embeddings
#each row contains an embedded review.
hf_embedded_reviews[['combined','embeddings']]python
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ combined ┃ embeddings ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ string │ array<float32> │
├──────────────────────────────────────────────────────────────────────────────────┼─────────────────────────────────────────────────────────┤
│ Title: Good Quality Dog Food; Content: I have bought several of the Vitality ca… │ [0.07233631610870361, 0.07917483150959015, ... +766] │
│ Title: Not as Advertised; Content: Product arrived labeled as Jumbo Salted Pean… │ [0.09642462432384491, 0.00853139627724886, ... +766] │
│ Title: "Delight" says it all; Content: This is a confection that has been aroun… │ [0.04878354072570801, 0.021106256172060966, ... +766] │
│ Title: Cough Medicine; Content: If you are looking for the secret ingredient in… │ [0.06679658591747284, 0.038995273411273956, ... +766] │
│ Title: Great taffy; Content: Great taffy at a great price. There was a wide as… │ [0.04276638850569725, 0.023525429889559746, ... +766] │
│ Title: Nice Taffy; Content: I got a wild hair for taffy and ordered this five p… │ [0.07608062773942947, -0.0033953222446143627, ... +766] │
│ Title: Great! Just as good as the expensive brands!; Content: This saltwater t… │ [0.031033676117658615, -0.0636257752776146, ... +766] │
│ Title: Wonderful, tasty taffy; Content: This taffy is so good. It is very soft… │ [0.06077864393591881, 0.007744158152490854, ... +766] │
│ Title: Yay Barley; Content: Right now I'm mostly just sprouting this so my cats… │ [0.031362198293209076, 0.020399324595928192, ... +766] │
│ Title: Healthy Dog Food; Content: This is a very healthy dog food. Good for the… │ [0.05561477690935135, 0.05685048922896385, ... +766] │
│ … │ … │
└──────────────────────────────────────────────────────────────────────────────────┴─────────────────────────────────────────────────────────┘Now that we have the embeddings, we will create a function that measures the similarity between a search term and the embedded review. The function will take in the embedded search term and the embedded review and use cosine similarity to figure out how similar the two are semantically. A float will be returned with values between 0 and 1. The higher the number, the more related the two embeddings are. Here’s the code to do this.
python
from scipy import spatial
#create a udf that takes in the search term embedding and the embedding from the table and
#calculates the cosine similarity. The higher this value the more similar
@udf.scalar.python
def similarity_embs(emb1:dt.Array('float32'), emb2:dt.Array('float32')) -> dt.float:
# compute cosine similarity
# cosine = np.dot(emb1,emb2)/(norm(emb1)*norm(emb2))
cosine = 1 - spatial.distance.cosine(emb1,emb2)
return cosineThe final piece of code will incorporate the above function, and allow a user to put in a word or phrase and search for related reviews. Along with their search term, they can also specify the number of similar results they want to return.
python
#create a function that takes in a users search term and how many results they want and returns
#the most semantically similar results
def hf_similarity_search(search_term, num_results):
#huggingface embedding model, make sure to switch this out for other models
search_term_embedding = hf_reviews_to_embeddings(search_term)
similarity_to_reviews = hf_embedded_reviews.mutate(similarity=lambda t: similarity_embs(t.embeddings, search_term_embedding))
#arrange the reviews by similarity and resturn the number of results requested
similarity_to_reviews = similarity_to_reviews[['combined','similarity']]
results = similarity_to_reviews.order_by(ibis.desc('similarity')).head(num_results)
results = results['combined'].to_pandas()
print(f'Results of your search:{search_term}')
for x in results:
print(x)
print(' ')We first turned the search term into an embedding, then used a Lambda function with mutate to pass each row of the embedding column to the similarity function we made above. We can then order the reviews by the resulting similarity function so the most similar reviews are on top. We return the top n results specified by the users and print them out.
The Results
To see how our search performs, we can experiment with searching. Below are some example searches I tried.
Search 1
python
#using hf embeddings
hf_similarity_search('bad delivery', 3)text
Results of your search:bad delivery
Title: disappointing; Content: not what I was expecting in terms of the company's reputation for excellent home delivery products
Title: AWFUL; Content: I received the items in a timely manner. Upon receipt, I removed a pack to consume. The pop-tart was STALE and left an awful taste in my mouth.
Title: Never Arrived; Content: So we cancelled the order. It was cancelled without any problem. That is a positive note...Search 2
python
#using hf embeddings
hf_similarity_search('spoiled food', 3)text
Results of your search:spoilt food
Title: stale product.; Content: Arrived in 6 days and were so stale i could not eat any of the 6 bags!!
Title: tastes very fresh; Content: <span class="tiny"> Length:: 0:26 Mins<br /><br /></span>The expiration date is 21 months from the day I bought this product. The tuna, tomato combination is delicious. This is one of the many items I re-order on Amazon every month or so.<br />edit: added a short video, so you see what this combination looks like.<br /><br />I was wearing one of those headlamps, but I didn't do a good job focusing on the tuna.<br />I should film it over, but it doesn't look like many people view this product anyway.
Title: AWFUL; Content: I received the items in a timely manner. Upon receipt, I removed a pack to consume. The pop-tart was STALE and left an awful taste in my mouth.Search 3
python
#using hf embeddings
hf_similarity_search('really good pet food', 5)text
Results of your search: really good pet food
Title: Great Dog Food!; Content: My golden retriever is one of the most picky dogs I've ever met. After experimenting with various types of food, I have found she loves natural balance. What I really like about natural balance is the fact that it has multiple flavors in dry and wet varieties. I mix her dry food with a little wet food and my golden loves it. Furthermore, I do like mixing up the flavors each time as I think the same meal day over day might get a little boring, so I figured why not. I tend to stay away from the fish type though as it smells...<br /><br />Additionally, I started purchasing off Amazon because Petco didn't have the wet food box and only had a couple of cans. I came home and to my surprise realized that I could save $20 each time I bought dog food if I just buy it off Amazon.<br /><br />All in all, I definitely recommend and give my stamp of approval to natural balance dog food. While I have never eaten it, my dog seems to love it.
Title: Bad; Content: I fed this to my Golden Retriever and he hated it. He wouldn't eat it, and when he did, it gave him terrible diarrhea. We will not be buying this again. It's also super expensive.
Title: Healthy & They LOVE It!; Content: My holistic vet recommended this, along with a few other brands. We tried them all, but my cats prefer this (especially the sardine version). The best part is their coats are so soft and clean and their eyes are so clear. AND (and I don't want to be rude, so I'll say this as delicately as I can) their waste is far less odorous than cats who eat the McDonalds junk found in most stores, which is a definite plus for me! The health benefits are so obvious - I highly recommend Holistic Select!
Title: Great Food; Content: Great food! I love the idea of one food for all ages & breeds. Ît's a real convenience as well as a really good product. My 3 dogs eat less, have almost no gas, their poop is regular and a perfect consistency, what else can a mom ask for!!
Title: Healthy Dog Food; Content: This is a very healthy dog food. Good for their digestion. Also good for small puppies. My dog eats her required amount at every feeding.As we can see the results are quite impressive. Traditional tabular data filters are very reliable, but only return exact matches. Semantic search extends this capability and allows us to draw more nuanced insights. I will note that in the final search, the second result was incorrect as it returned a negative dog food review instead of a positive one. This means that the model did not correctly capture all of the semantic meaning.
Comparison With OpenAI Embeddings
Models that take into consideration more aspects of data can be used to get more accurate results. One example of this would be OpenAI’s embedding model. The "text-embedding-ada-002" embedding model produces embeddings that have a length of 1536, almost triple the size of the Hugging Face one. The larger embeddings mean semantic relationships will probably be more precise. However, a side effect of larger embeddings is that running the embedding function with the OpenAI model took substantially longer than using the Hugging Face model. The OpenAI model is also closed source and users pay for access to the API based on usage.
To test how the OpenAI model performs comparatively, we only need to change the model instantiated and replace it wherever it is used. You’ll also need to provide an OpenAI API key. I only need to make the following changes to the code we created earlier. The rest of the workflow is pretty much the same, with the exception of changing variable names.
python
import os
os.environ['OPENAI_API_KEY'] = 'openai-api-key'
#using huggingface embeddings
open_embedding_model = OpenAIEmbeddings()
#using Ibis UDF
@udf.scalar.python
def hf_reviews_to_embeddings(s:str) -> dt.Array('float32'):
embedding = open_embedding_model.embed_query(s)
return embeddingNow, let’s compare the result of the last search which was a bit tricky with Hugging Face.
python
# using openai embeddings
openai_similarity_search("really good pet food", 5)text
Results of your search:really good pet food
Title: Great dog food; Content: This is great dog food, my dog has severs allergies and this brand is the only one that we can feed him.
Title: Great Food; Content: Great food! I love the idea of one food for all ages & breeds. Ît's a real convenience as well as a really good product. My 3 dogs eat less, have almost no gas, their poop is regular and a perfect consistency, what else can a mom ask for!!
Title: Great food!; Content: We have three dogs and all of them love this food! We bought it specifically for one of our dogs who has food allergies and it works great for him, no more hot spots or tummy problems.<br />I LOVE that it ships right to our door with free shipping.
Title: Good Quality Dog Food; Content: I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most.
Title: Mmmmm Mmmmm good.; Content: This food is great - all ages dogs. I have a 3 year old and a puppy. They are both so soft and hardly ever get sick. The food is good especially when you have Amazon Prime shippingAll of these results are positive and are what we were expecting!
Conclusion
Embeddings are becoming more powerful and are more accessible than ever. Utilizing tools like Ibis and LangChain empowers teams to switch out data sources and LLM flavors without having to change much of their code and therefore have more flexibility to work with embeddings. Ibis and LangChain provide a way to augment your tabular data systems to leverage the power of semantic search. This will make your analysis work is more context-aware, connected and insightful, all without having to overhaul your existing code base.
Voltron Data helps enterprises design and build composable data systems using open source tools like Ibis. To learn more about our approach, check out our Product page.
Photo by Valentin Gautier
Previous Article

Keep up with us


