What is Substrait? A High-Level Primer
By
K
Kae SuarezAuthor(s):
K
Kae SuarezPublished: April 5, 2023
6 min read
Substrait is a standardized intermediate representation (IR) for relational algebra.
We love it for what it is, but also realize that this sentence means very little except for when said to the technically inclined. Why do we care about IR? What does IR even mean? Why would we want one for relational algebra, when current methods and careful passing around of SQL works already?
For our purposes, consider relational algebra to be a set of rules that defines how you can transform data based on operations.
To answer these questions, we’re going to start by not talking about Substrait. Instead, we’re going to look at history, and see what lessons we can glean — and how this all motivates the existence of Substrait.
IR in Compilers
Let’s switch gears from data to code.
When a programmer writes code in a language like C or Rust, it can’t run on the machine right away. Instead, tools are called to turn the code from human-readable to machine-readable. These tools make up a compilation toolchain, and when combined are called “compilers”. The reason they tend to be chains of tools is due to the sheer volume of combinations between languages, tools, and hardware.

Originally, compilers would compile code directly for a given hardware — there were so few languages and hardware options, and limited places where these existed, that it was natural to specialize all such efforts. This meant that there was a compiler for each language-to-hardware mapping, which worked due to low volume of work in the field.
However, the field grew. New languages and different hardware were introduced to the market. So, if you had five languages and five [hardware], you needed 5*5 compilers - 25 total. The addition of one language would have necessitated 30 compilers.
Now, fast forward to today. With the abundance of languages and hardware configurations available today, the solution is intermediate representation (IR). Where the original structure is mapped one-to-one, IR creates a middle point. Now, instead of mapping from one language to one architecture, you map first from the language to IR, then from the IR to architecture. When you only have one language and one architecture, this is just additional work. However, if you target the same IR from every language, and map from the same IR to every architecture, the benefit appears.
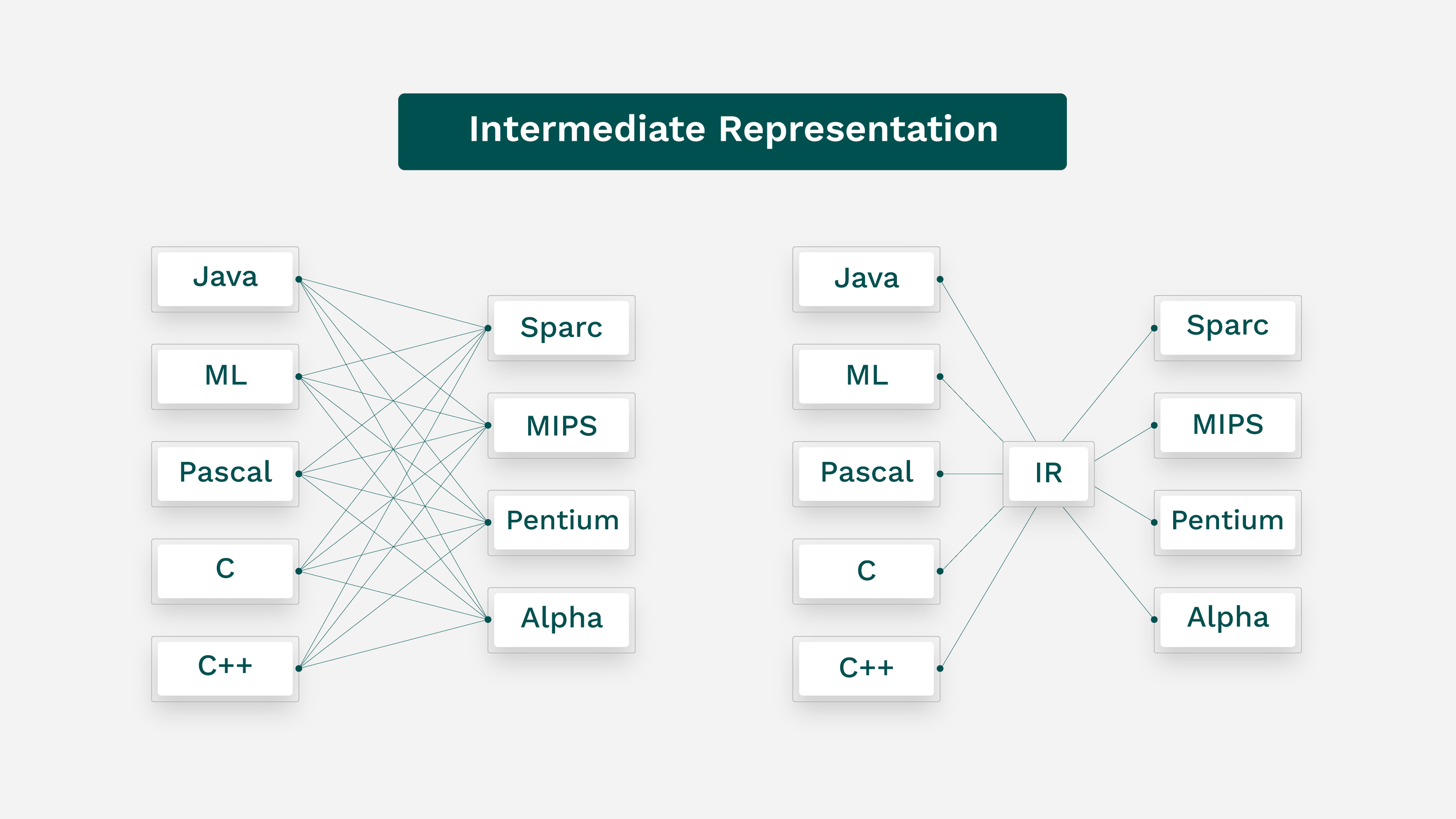
By mapping to a single middle point, you only need tools to move from each language to IR, and from IR to each hardware configuration. That’s one for each item, rather than one for each possible item pair. Thus, when you include a standard IR, supporting five languages and five hardware configurations requires 10 tools — five language-to-IR, five IR-to-hardware.
Now, how does this relate to Substrait? Pretty directly, actually.
IR in Relational Algebra
With the above in mind, let’s consider relational algebra.
For every tool or language that exists for query submission, there is a mapping to the tools to execute that query. Of course, the mapping doesn’t exist 100% of the time, support isn’t perfect…
But doesn’t that situation sound familiar? This kind of mapping gets you situations like the set of connectors that have to exist for Trino to work, which is a long list. Though, this isn’t a slight against Trino — this is just the reality and what is necessary for Trino to function in the current ecosystem.
This sounds exactly like what happened in compilers — it was reasonable to do one-to-one at first, but now it’s ballooning to impossible-to-manage extents.
So, why not just do the same thing? Make a format in the middle, halfway between human-readable and machine-readable. Every front-end maps to it, and every back-end reads from it.
That’s Substrait, the IR for relational algebra.
Closing Statement
Substrait makes it so that anywhere you have to talk about queries, you map them to and from Substrait, so every front and backend only has to know Substrait. Users still write in SQL, Ibis, etc., but the middle transformation makes things easier for the people maintaining the software.
Consider how much effort is spent on compatibility alone. If all such efforts could be produced against Substrait, instead of against every supported front and backend, that provides the opportunity for more time spent innovating, not to mention that it allows for supporting more diverse stacks. Less work, more support, more innovation — it just requires the adoption of Substrait, and its development as an IR.
You may ask: what about SQL? That’s already used almost everywhere anyways, right? Well, to be more accurate, dialects of SQL are widespread. From a code standpoint, those are effectively different languages. It’s not truly standardized. Furthermore, SQL is, at its core, meant to be human-legible and human-writeable. It lacks details in how execution needs to happen and does not define the format of query and execution plans. Substrait does, which ensures stability and standardization across platforms. It’s not another SQL dialect — it’s an IR for query engines, to be used in concert with the query language of your choice.
Substrait is young, and adoption is just starting to get rolling! However, much like IR in compilers, we see this as a path forward, which enables all of us to keep innovating without having to think about all the time we’ll spend on compatibility work. Learn more about Substrait through the project’s website or our previous blog, “Introducing Substrait an Interoperable Engine Connector”. If you want help getting started or optimizing your efforts with Substrait, check out our enterprise support options.
Photo by James Clark
Intermediate Representation Graphic from:
Computer Science 302, Prof. David Walker - Princeton University

Keep up with us


