Explore a New Way to Deploy Data Storage and Analytics with Arrow Flight SQL and Apache Superset
By
K
Kae SuarezAuthor(s):
K
Kae SuarezPublished: April 27, 2023
8 min read
TL;DR This proof-of-concept stack showcasing a test deployment of an SQLAlchemy driver for Arrow FlightSQL demonstrates how you can have a fully open-source, Arrow-native stack for data storage, analytics, and visualization.
Opening the Stack
Imagine a fully modular open source stack, all the way from database to visualization and analytics. In the past, to be truly robust when serving large amounts of data through user-friendly dashboards, large parts of the stack would be locked in place, increasing technical debt and opportunity cost by the year. Not to mention that, if you have some proprietary closed-source components in these stacks, you wouldn’t be able to customize or grow it for your use case.
However, open source and modular software have only grown stronger, especially with the arrival of Apache Superset as a lightweight and powerful open source dashboard. With that, and with recent advancements in standardization and portability, entire stacks can be built and customized for your needs — and often, you can start out with free or low-cost software.
In order to enable another stack configuration, we’ve created an SQLAlchemy driver for Arrow FlightSQL, which enables easy deployment of an open source data storage and analytics stack that leverages the power of Arrow via FlightSQL, and deploys Apache Superset as the interface! We’re eager to demonstrate it today.
Just to set the scene, here’s a teaser:

Data
We’ll use the Public Use Microdata Sample (PUMS) dataset. It is a census dataset that emphasizes information on a sample of the population, including demographic, housing, and economic characteristics. It is collected by the U.S. Census Bureau as part of the decennial census and is made available to the public for research and analysis. Previously, we’ve explored converting the data to Parquet, and using various open source tools to analyze it easily and efficiently. Today, we’ll use the outcome of the former work as the underlying data that will be loaded into this analytics stack.
So, without further ado!
Stack Overview
In this demonstration, we’ll host both a Flight SQL-based DuckDB database server and Superset client locally with Docker. The client will present Superset over a website to the user, and send queries via SQLAlchemy, with our custom-made driver into the Arrow Database Connectivity (ADBC) FlightSQL driver (yes, there are two drivers — this is necessary because Superset must use SQLAlchemy). These queries will be sent to the server container as defined by FlightSQL, and DuckDB will process queries and store data. Once a query reaches DuckDB, it will process and send back through each step up to Superset to be displayed in browser.

The tools in this stack are open source with the exception of Docker which we used for the convenience of demonstration. Docker isn’t necessary for this stack, users can deploy by hand for their given use case.
Demonstration
Wrangle the Data
First, you need a DuckDB database file version of the data, made for version 0.7.1. In this case, we’ll make the database out of a Parquet version of the person-focused PUMS data for 2016-2020 — you can learn how to make that version in this blog, or just download the DuckDB database here and skip this section!
With Parquet in hand, you can make the database with DuckDB directly, or via Ibis, an open source Python interface for databases. Here, we’ll use Ibis — just make sure your DuckDB is version 0.7.1.
python
import ibis
# In the absence of an existing database, this will make one,
# which is what we want.
con = ibis.connect("duckdb:///<target_path>/person_pums.duckdb")
t = con.create_table("pums", con.read_parquet("part-0.parquet"))In the current version of Ibis, this creates a table and a view in the database — if desired, you can clean out the view, but it is unnecessary to do so for our purposes.
Wait until the code finishes running, then just close out Python. You have a DuckDB file!
Set up the Containers
Now, as previously stated, we’ll use Docker to handle the heavy lifting of setting the stack up. We’ll use the setup provided at the repository that hosts the proof of concept stack, but with a modification to the server startup to take our arbitrary data.
First, make sure you have Docker running. You’ll need it installed and turned on to run any containers — but it’ll make sure you don’t have to install any other software. You can install Docker here.
The code to start the server with our data is as follows:
bash
docker run --name flight-sql \
--detach \
--rm \
--tty \
--init \
--publish 31337:31337 \
--env FLIGHT_PASSWORD="flight_password" \
--pull missing \
--mount type=bind,source=$(pwd),target=/opt/flight_sql/data \
--env DATABASE_FILE_NAME="person_pums.duckdb" \
voltrondata/flight-sql:latestThe command to start the Superset frontend is unchanged from the repository, but we provide it here for convenience:
bash
docker run --name superset-sqlalchemy-adbc-flight-sql \
--detach \
--rm \
--tty \
--init \
--publish 8088:8088 \
--env SUPERSET_ADMIN_PASSWORD="admin" \
--pull missing \
voltrondata/superset-sqlalchemy-adbc-flight-sql:latestSetting up Superset
Now that the containers are running, you need to connect to Superset — if you used the commands above, it’ll be at localhost:8088.
💡 It may not be at localhost:8088 immediately, as it can take a minute or two to spin up.
When you launch, you’ll be greeted with something like the following:

Just enter admin as username and password — it’s already set up that way in this testing environment. You can, of course, set other values when setting up more manually.
From there, we need to actually get our database pulled in. While compatible, it’s not one of the official use cases, so it takes some minor effort. First, you need to go to the top right, to settings, and get the “Database Connections” option.

From there, you’ll be on a new window. On the top right, click the +DATABASE button.

This opens a new window, where you’ll be presented with database options. Select other.

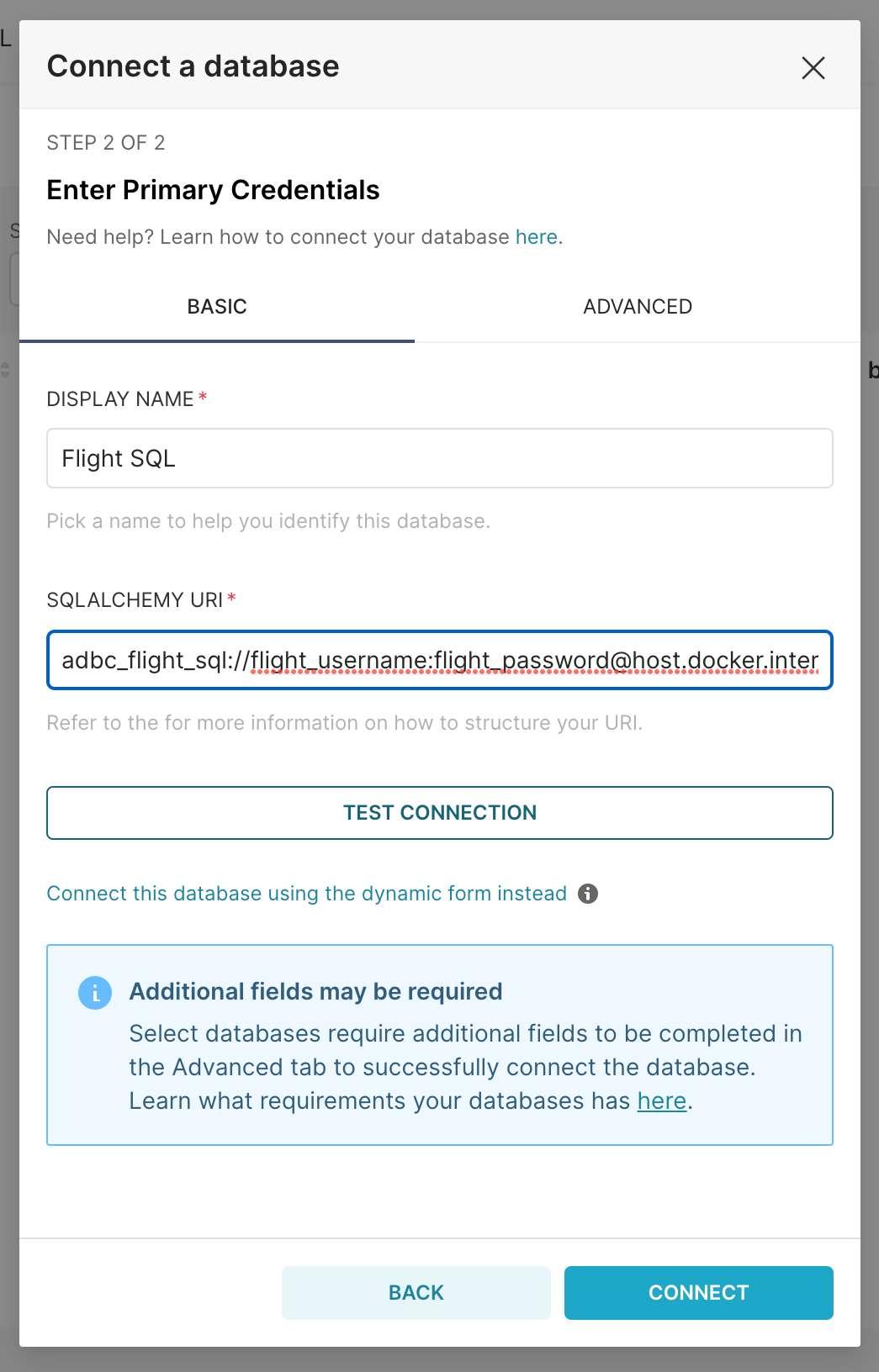
In the new boxes, fill in Flight SQL for name, and adbc_flight_sql://flight_username:flight_password@host.docker.internal:31337?disableCertificateVerification=True&useEncryption=True for the SQLAlchemy URI.
After that, you can test the connection, if so desired, or just go ahead and connect.
Now, at the top navigation bar, select SQL Lab.

You’ll now have a SQL interface to play with!
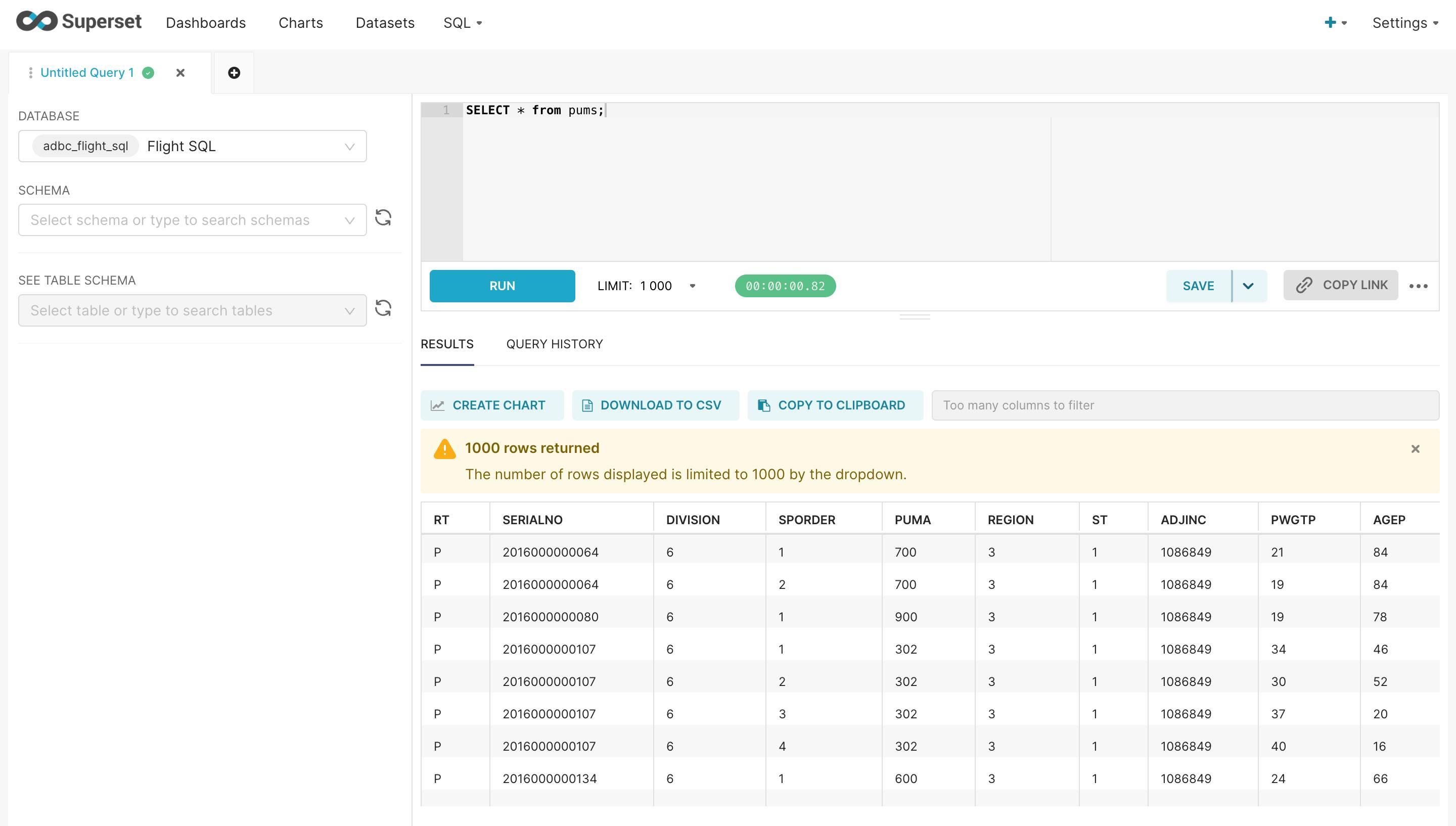
From here, you can use Superset to make charts and dashboards based on the outcomes of your SQL queries. We leave the specifics of that process to the Superset documentation proper: https://superset.apache.org/docs/intro/
Closing Statement
Together, these tools use Arrow data and open source software to create a modular and powerful stack that fully leverages the OSS ecosystem. The access to the code and community of these tools offers notable benefits. Transparency enables understanding, and, if necessary, extension of the code underlying your solution. Furthermore, you can reduce your costs, or focus on hardware, because you aren’t having to allocate all your spending on licensing and subscriptions. Instead, you can spend more time interacting with your data and extracting vital insights instead of paying for or making ways to do it.
As for the flexibility of the stack, the use of communication standards means you can switch out various parts. For example, here, we used a subset of the PUMS dataset, which can be used on a laptop, so DuckDB was an obvious choice. Due to the flexibility of Arrow FlightSQL and ADBC, you could put a database system of any scale at the bottom of this stack, just as long as it can speak through Arrow FlightSQL, and serve data from KB to TB scale.
While this proof of concept doesn’t include database security, it’s possible with the present software — which means you can safely use this stack to serve data internally and externally. At no point do you have to sacrifice flexibility and security for the benefits of open source.
Voltron Data assists in the development of Arrow FlightSQL, ADBC, and produced the SQLAlchemy driver that enabled this proof of concept. To explore these and accelerate your success with the Arrow ecosystem, learn about Voltron Data’s Enterprise Support options.
Photo by TruShotz
Previous Article

Keep up with us


