Leverage Arrow and Ibis to Streamline Database Connectivity
By
K
Kae SuarezandP
Phillip CloudAuthor(s):
K
Kae SuarezP
Phillip CloudPublished: August 15, 2023
5 min read
There are many powerful database and query systems with a variety of strengths, which are often complementary. However, marrying the outputs, or even just transmitting data between two databases can be burdensome or slow.
Often, the best answer is just to write to a file that the other database can read, and pass it over. At that point, however, you’ve gone out to the filesystem, and are at the mercy of differing types and file parsers. This puts you in a position to balance cost and the strength of your database — like moving data from an OLTP system to OLAP for analysis. You may well end up with extra costs that discourage you from moving forward.
There is a way, however, to augment your data system by using open source components and minimizing costs.
Ibis provides a consistent interface to 18+ backends, and Arrow provides a standard columnar memory format that can make the transfer of data trivial. If these advantages are combined, the challenge of integrating two systems is solved. With a new, experimental technique that leverages Arrow support in Ibis and a given Arrow-supporting database, it’s possible to handle integration in just a couple lines of code and take ownership of your systems.
How Does it Work?
As much as it feels like magic, this process is the outcome of years of software engineering that come together to showcase the power of strong open source standards.
- Arrow is the key — as a well-defined memory format, anything that supports it will be able to transfer data anywhere else that can take it.
- Ibis can turn output from any query from any backend into Arrow data, and thus pass it into anything that accepts Arrow data.
- This, of course, includes any backend that supports Arrow, including DuckDB and DataFusion.
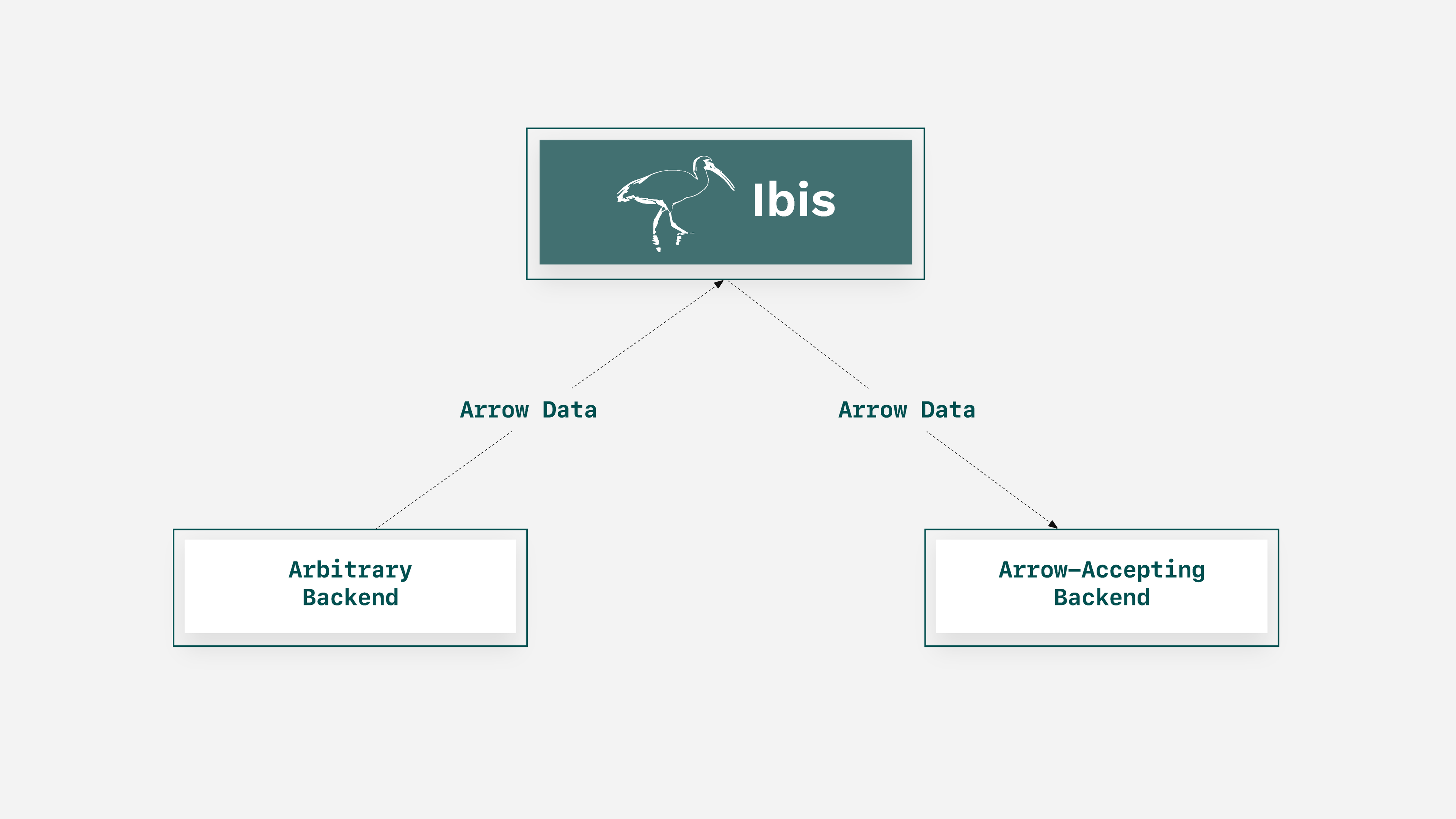
In this post, we’ll explore using Postgres and transfer data from it to DuckDB via Arrow.
TL;DR This is experimental. It can work with any backend that accepts Arrow in DuckDB’s place, but watch out for — and report — any bugs!
Code Example
Setup
For ease of deployment, we’ll use the CI setup for Ibis, which you can set up with the instructions for Ibis contribution. However, if you have your own database and data, you can skip this and try it yourself. Here, we leverage the CI setup to have quick and easy access to a Postgres database, along with the data used for testing in Ibis.
Note that the exact code to follow will use DuckDB — to use something like DataFusion’s support of Arrow stream input, use con.register() instead of con.read_in_memory()
Code
First, imports! Ibis has a special import that gets you set up for an interactive session right away, so we’ll use that for simplicity:
python
from ibis.interactive import *Next, let’s connect the Postgres server included with the Ibis CI, and get our target table:
python
pgcon = ibis.connect("postgres://postgres:postgres@localhost:5432/ibis_testing")
awards_players = pgcon.table("awards_players")For the sake of example, let’s say that our Postgres database just doesn’t have some essential data that we have on disk or an existing DuckDB database. We don’t need to add a new table to the Postgres database, we just want to put the tables together for one query. First, we’ll have to get the extra data on hand:
python
ddb = ibis.duckdb.connect()
batting = ddb.read_parquet("ci/ibis-testing-data/parquet/batting.parquet")Now we have two database connections, each containing one table we need. DuckDB is excellent at analytics, so we choose to do our work there. How do we do it?
python
awards_batches = ddb.read_in_memory(awards_players.to_pyarrow_batches())That’s it. Ibis orchestrates selecting all data from the awards_players, routing it to Arrow batches, and DuckDB can read that easily. From there, we can join with our batting table, because the Postgres table now just has a version in DuckDB — after one line. So the rest comes easily:
python
expr = batting.join(awards_batches, ["playerID", "yearID", "lgID"])
df = ddb.execute(expr)
df
Out:
playerID yearID stint teamID lgID G AB ... HBP SH SF GIDP awardID tie notes
0 bondto01 1877 1 BSN NL 61 259.0 ... NaN NaN NaN NaN Pitching Triple Crown None None
1 hinespa01 1878 1 PRO NL 62 257.0 ... NaN NaN NaN NaN Triple Crown None None
2 heckegu01 1884 1 LS2 AA 78 316.0 ... 2.0 NaN NaN NaN Pitching Triple Crown None None
3 radboch01 1884 1 PRO NL 87 361.0 ... NaN NaN NaN NaN Pitching Triple Crown None None
4 oneilti01 1887 1 SL4 AA 124 517.0 ... 5.0 NaN NaN NaN Triple Crown None None
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
4822 kiermke01 2015 1 TBA AL 151 505.0 ... 2.0 2.0 2.0 7.0 Gold Glove None CF
4823 molinya01 2015 1 SLN NL 136 488.0 ... 0.0 1.0 9.0 16.0 Gold Glove None C
4824 martest01 2015 1 PIT NL 153 579.0 ... 19.0 3.0 5.0 14.0 Gold Glove None LF
4825 troutmi01 2015 1 LAA AL 159 575.0 ... 10.0 0.0 5.0 11.0 Silver Slugger None OF
4826 troutmi01 2015 1 LAA AL 159 575.0 ... 10.0 0.0 5.0 11.0 All-Star Game MVP None None
[4827 rows x 25 columns]Conclusion
Databases are highly optimized for their use cases, from OLTP to OLAP to hybrid systems. As a result, their internals are often incompatible — but with open source standards like Arrow, and standard interfaces like Ibis, it’s possible to leverage these specialized systems to make a modular and composable stack that perfectly fits your needs.
This was all made possible by having backends for Ibis that can ingest Arrow batches. For every system that adopts the Arrow standard, it gets easier and easier to leverage the power of other tools and components, whether you’re an engine developer or an end user.
Voltron Data designs and builds composable data systems using standards like Arrow, Ibis, and more. Visit our Product page to learn more.
Previous Article

Keep up with us


