SQL and Semantic Search - Merging Structured and Unstructured Data
By Voltron Data
Voltron Data
Author(s):
Published: July 17, 2025
4 min read
Theseus is not just a SQL engine. It’s a distributed C++ runtime built natively for hardware accelerators. We happen to optimize it around SQL and OLAP use cases, but it can do so much more. Years ago, we set out to enable Theseus UDF (user-defined function) support for two main reasons:
test
- Users of SQL engines expect it.
- A GPU-native distributed runtime could seamlessly blend GPU-accelerated UDFs and merge the worlds of structured and unstructured data.
Today, we’re debuting Theseus support for GPU-accelerated UDFs. This enables us to demonstrate point 2 from our list above (the merger of structured and unstructured data). Theseus brings semantic search directly into your data warehouse by embedding GPU-accelerated vector search inside standard SQL queries. It performs on-demand tokenization and JIT embedding, eliminating costly pre-compute pipelines and external vector stores, so you can query petabyte-scale datasets in seconds. By unifying structured analytics and unstructured retrieval within a single SQL-native engine, Theseus feeds live data as context to LLMs with built-in optimizations for high throughput and low operational overhead. There's no manual tuning or Python orchestration required.
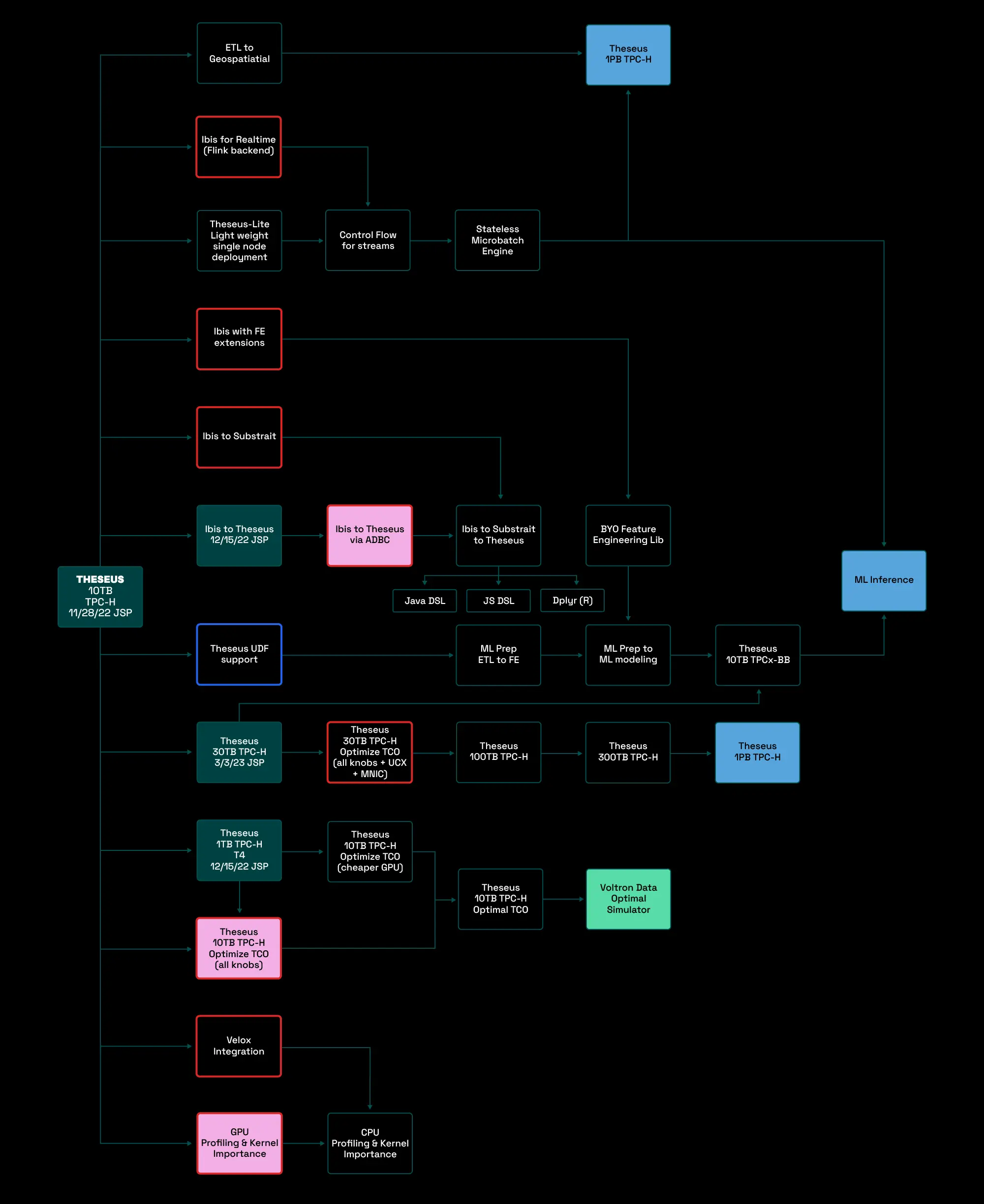
This is a screenshot of our roadmap from three years ago. We’ve accomplished over 70% of what’s on this roadmap.
Example: GPU vector search inside SQL queries
Here, we integrate NVIDIA’s cuVS (CUDA Vector Search) library alongside Hugging Face’s Tokenizer library to create a simple RAG pipeline. Feel free to checkout the gist and walk through the code below. Here’s a quick summary:
Generate the embeddings
python
ibis_con.raw_sql("""CREATE FILESYSTEM "voltrondata-demo-tests" (
TYPE S3,
PROJECT_ID 'voltrondata-demo'
)""").execute()
embedded_df = ibis_con.sql(f"""
SELECT
rag.embed_text_series(url, text, '{embeddings_path}', '{model_name}') as result,
url AS url
FROM wikipedia where
text <> ''
""").to_pandas()
ibis_con.read_parquet(embeddings_path,table_name='wikipedia_embed')Build an index using NVIDIA
python
import os
import pandas as pd
import numpy as np
ibis_con.read_parquet(embeddings_path,table_name='wikipedia_embed')
index_dir = "/data/index"
output_dir = "s3://voltrondata-demo-tests/ln-udf-rag/index"
#Returns the path to where the indeces were written
index_df = ibis_con.sql(f"""
SELECT
rag.build_vector_index(embedding, texts, source_url, '{output_dir}', '{index_dir}')
FROM wikipedia_embed
""").to_pandas()Use NVIDIA cuVS to run a CAGRA search for a text string
python
k = 32
query = "tell me about babylonian writing system"
index_dir = "s3://voltrondata-demo-tests/ln-udf-rag/index"
ibis_con.read_csv(index_dir,table_name='index_files',header=False)
results_dir = "s3://voltrondata-demo-tests/ln-udf-rag/results"
vector_index_dir = "s3://voltrondata-demo-tests/ln-udf-rag/index/vector"
result_files = ibis_con.sql(f"""
SELECT
*
FROM index_files
""").to_pandas()
print(result_files)
result_files = ibis_con.sql(f"""
SELECT
rag.search_vector_index(index_files."0", '{query}' , '{vector_index_dir}', '{results_dir}' , {k}, '{model_name}')
FROM index_files
""").to_pandas()
#Gather and print results
results_table = ibis_con.read_parquet(results_dir,table_name='results')
results = con.sql(f"""
SELECT
* FROM results
order by distance asc
limit 128
""").to_pandas()
resultsHand those results to an LLM alongside the original question for inference
python
from build_rag_helper import VodaAgent
import pyarrow
agent = VodaAgent()
question = 'Tell me about Babylonian writing system'
context = pyarrow.array(results['text'].tolist())
answer = agent.ask(question, context)
print(answer.to_pylist()[0])The UDF
Above was the workflow. This is how we created one of the called UDFs.
python
@signature([na.string(), na.string(), na.string(), na.string(), na.int32(), na.string()], na.string())
@udf("rag", "search_vector_index")
def search_vector_index(index_paths: cudf.Series, query: cudf.Scalar, vector_index_dir: cudf.Scalar, results_path: cudf.Scalar, k: cudf.Scalar, model_name: cudf.Scalar) -> cudf.Series:
"""
Searches through pre-built vector index files using a query and returns distances.
Args:
index_paths: Series of paths to index files
query: Query text to search for
results_path: Path to save the results
k: Number of nearest neighbors to retrieve (default: 32)
Returns:
Series of distances for each query result
"""
if len(index_paths) == 0:
return cudf.Series([], dtype="float32")
# Process k parameter
if isinstance(k, cudf.Series):
k_value = k.to_arrow().tolist()[0]
else:
k_value = k.value
if isinstance(results_path, cudf.Series):
results_path = results_path.to_arrow().tolist()[0]
else:
results_path = results_path.value
if isinstance(model_name, cudf.Series):
model_name = model_name.to_arrow().tolist()[0]
else:
model_name = model_name.value
if isinstance(vector_index_dir, cudf.Series):
vector_index_dir_str = vector_index_dir.to_arrow().tolist()[0]
else:
vector_index_dir_str = vector_index_dir.value
# Process query
query_str = cudf.Scalar(query.to_arrow().tolist()[0]) if isinstance(query, cudf.Series) else cudf.Scalar(query)
query_embedding, _, _ = split_and_embed_texts(cudf.Series([query_str.value]), model_name)
query_vector = cp.asarray(query_embedding)
results_paths = []
index_paths = index_paths.to_arrow().tolist()
# Search through each index
for index_path in index_paths:
filename = os.path.basename(index_path).replace(".index", ".parquet")
data_path = f"{vector_index_dir_str}/{filename}"
# Load the vector index from the file
ann_index = load_vs_index(index_path)
# Search the index
distances, result_indices = search_embeddings(ann_index, query_vector, k=k_value)
df = cudf.read_parquet(data_path,
columns=["text","url"])
k_value = 32
result_indices = result_indices.get().tolist()[0]
if(len(result_indices) != k_value):
raise RuntimeError(f"Error processing index {index_path}: expected {k} results, got {len(result_indices)} with {result_indices}")
df = df.take(result_indices).reset_index(drop=True)
dist_series = cudf.Series(distances.get().tolist()[0], dtype="float32")
df['distance'] = dist_series
try:
result_path = f"{results_path}/search_results_{index_path.split('/')[-1].replace('.index', '.parquet')}"
df.to_parquet(result_path, index=False)
results_paths.append(result_path)
except Exception as e:
raise RuntimeError(f"Failed to save results for index {result_path}: {str(e)}")
return cudf.Series(results_paths, dtype="string")This UDF calls a very simple CAGRA search function from cuVS.
python
def search_embeddings(index, query: cp.ndarray, k: int = SEARCH_K) -> tuple:
params = cagra.SearchParams()
distances, neighbors = cagra.search(params, index, query, k=32)
return cp.asarray(distances), cp.asarray(neighbors)Conclusion
This is just the start. We have deployed Geospatial UDFs, Tokenizers, and more to our customers, but we thought it was high time we showed this off. To be clear, we’re demonstrating this functionality inside a column projection, but it can also work inside WHERE clauses, JOINs, and GROUPBYs.
We’re also looking into how to integrate components of this pipeline with the recently announced AWS S3 Vector and how we can export our embeddings to S3 Vectors and build cuVS-powered indexes on that data.
Reach out if you want to see this in action for yourself on your workload.
Previous Article

Keep up with us


