The GPU ↔ CPU crossover: DuckDB and Theseus are better together
By Voltron Data
Voltron Data
Author(s):
Published: June 4, 2025
6 min read
With open standards as the compass, the GPU crossover becomes a budget line item rather than an infrastructure migration.
Crossover points
Two forces shape modern analytics. First came the rise of composable data systems, a movement chronicled in the Composable Codex, which shows how open standards such as Arrow and ADBC turned database design into assembling interchangeable parts rather than commissioning monoliths. The second force was hardware: AI workloads demanded throughput that CPUs alone could not provide, propelling GPUs and other accelerators into everyday data pipelines. Those currents now meet: teams no longer debate whether to adopt new engines but when to swap one for another. That timing defines the “crossover” question.
Where CPUs hit the wall—and where GPUs pay off
Lock-in, scaling, and cost-performance are the three pressures that force data system changes. DuckDB solves the first for many jobs, with many enterprises adopting DuckDB to mitigate the high costs of SaaS-based offerings. Startups like Greybeam.ai have built a business offloading Snowflake jobs to DuckDB. Yet this is all on a small-scale, single-node, CPU-compute architecture. For many queries (1-10TB), DuckDB performs quite well. However, Large-scale analytics with sprawling joins, multi-way aggregations, and deep sorts will collide with memory-bandwidth limits on CPUs. GPU-accelerated engines leap that wall.
TPC-H Results Comparing DuckDB and Theseus
We conducted a benchmarking effort to define a crossover point between DuckDB and Theseus, evaluating cost and performance using TPC-H, an industry standard analytics benchmarking suite, at scale factors 1 to 30,000. Our findings further illustrate our point that there’s a switching point as you scale up and out to larger and more complex queries. In practice, the crossover occurs when data volumes exceed a 10 terabytes and when the business requires results in hours rather than days; above that threshold, GPU hours are more cost-effective and significantly faster than their CPU equivalents.
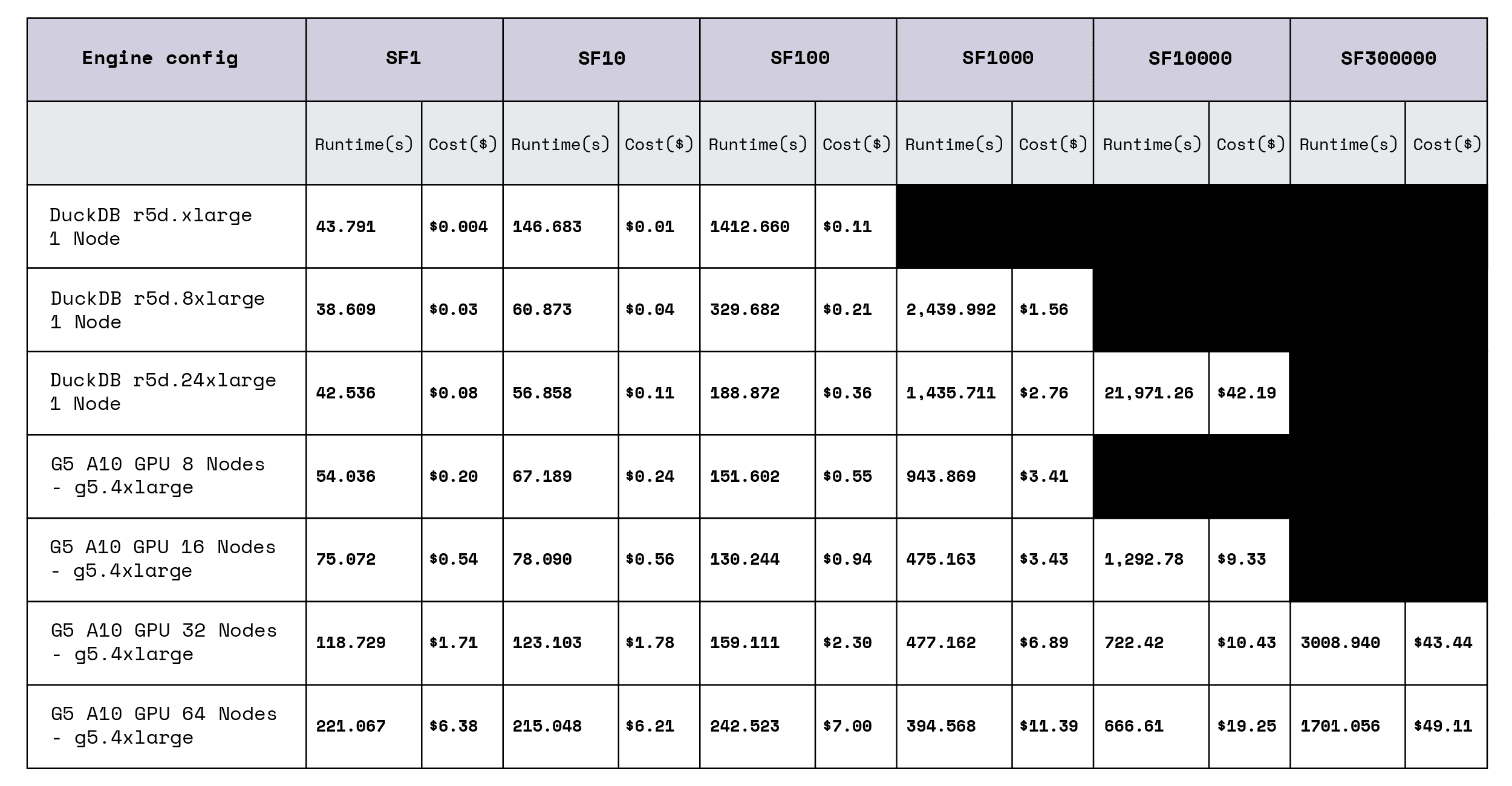
TPC-H Results Comparing DuckDB and Theseus: Performance
Notice the crossover point above SF100 where performance degrades for DuckDB and a switch to Theseus starts to make sense. This is very apparent at SF10000 or 10TBs where Theseus completes the TPC-H benchmarks in just over 11 minutes using 64 NVIDIA A10 GPUs, while DuckDB takes over 6 hours to complete the same test on AWS using a 24 xlarge CPU config.
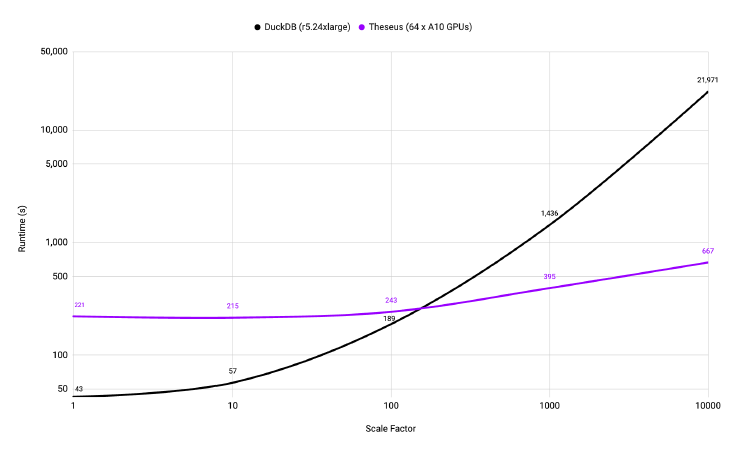
TPC-H Results Comparing DuckDB and Theseus: Cost
A similar crossover point exists on the cost side. Yes, GPUs are more expensive. However, there’s a point around SF10000 or 10TBs where the switch also makes economical sense. At SF10000 Theseus completes the TPC-H benchmarks for a cost of $19.25 using 64 NVIDIA A10 GPUs, while DuckDB costs more than double to complete the same test on AWS using a 24 xlarge CPU config.
The Right Tool for the Job
Composable systems are “MICE”: modular, interoperable, customizable, and extensible. For Spark-alternative query engines, DuckDB is one module. RAPIDS-accelerated Spark is another. Voltron Data’s Theseus adds a third. But not all engines are swappable. Theseus and DuckDB are SQL engine query engines built from the ground up for composability, both speaking Arrow. Because Theseus is accelerator-first, it becomes the next hop when a DuckDB plan grows too large or too complex for CPUs. With Arrow buffers and ADBC connectors in place, the migration is as simple as routing the same query plan to a different endpoint. This presents a compelling argument for a multi-engine approach to data system design.
Our stance on Composability
Our goal is to keep every layer swappable. Our founders and engineers are the creators and maintainers of Arrow, Ibis, ADBC, Calcite, RAPIDS, and now ship Theseus, so that engines and even processors can come and go without rewriting pipelines. DuckDB strengthens that vision by delivering an affordable and very user-friendly CPU-first option, while Theseus anchors the GPU side for distributed work. Together, they sketch a cost-performance curve that practitioners can traverse by configuration rather than re-architecting.
Finding your crossover point
When a query touches less than a hundred terabytes, accepts runtimes of an hour or more, and involves relatively straightforward SQL patterns, DuckDB Distributed on CPUs is usually the economic winner. As data volumes swell, runtime expectations tighten, or SQL grows join-heavy, the equation flips; GPU-driven Theseus delivers double-digit speed-ups at a fraction of the per-query cost. Because these engines honor the same standards, a team can treat that decision as a business case rather than a tech challenge.
Pilot DuckDB Distributed on real, small-scale workloads, then profile the slowest queries and rerun them on Theseus. As new accelerator-native engines emerge, expect them to drop straight into the same fabric—because the standards, not the engines, are the enduring interface. DuckDB and Theseus are complementary points on a continuum that finally lets data engineers choose hardware by workload, without rewiring the stack.
Wrap up
The future of accelerated SQL analytics is here. Stay tuned as we continue to push the boundaries of performance, efficiency, and cost savings.
For more details on our benchmarking process, see our Theseus Benchmarking Report, where we break down the results, methodologies, FAQs, and system specifications.
Remember, it’s all about how fast your queries run and what it costs to run them. Theseus delivers. Join our mission to slash the cost of analytics and give Theseus a try.
Previous Article

Keep up with us


