Data Transfer at the Speed of Flight
T
Tom Drabas
F
Fernanda Foertter
D
David Li

We’ve talked about how Apache Arrow Flight lets users stream Arrow data between applications quickly and without unnecessary overhead taking time away from your code. Now that we know how to move data, let’s get to work on it.
What if we could start some data engineering work in R, then train a model with your favorite Python ML framework? We could write data out to a CSV, Parquet, or Feather file first, then read it back in. Oftentimes this is a great approach, but Flight gives you better tools for building more complex applications that might span multiple machines or stream data to each other on-the-fly instead of bouncing data through a filesystem.
As a quick example, we’ll walk through how to use Arrow, Flight, and Python to build a key-value cache service – think something like Redis or memcached.
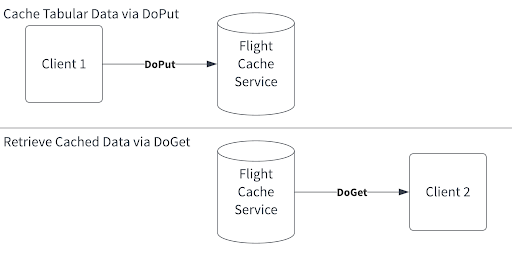
An illustration of what the service we’ll build does.
Building a Key-Value Flight Service
We need to build two things: a server that stores and sends data and a client that can request data. Using Python, we will first build a service that accepts uploaded data and stores it in-memory. The server will be able to stream that data to clients who ask for it using a string key. The functionality shown here is similar if you’re using C++, Java, or whatever language supported by Flight.
Flight is already supported in the Python, C++, R, Java, Rust, Go, C♯, Ruby, and GLib (C) Arrow libraries, with more support coming in other
Create a server
First, as always, some imports:
python
import pyarrow.flight as flightNext, let’s create the server for our example.
python
class TestServer(flight.FlightServerBase): def __init__(self, location): self.tables = {}
self.location = location
super().__init__(location)
We derive a TestServer class from the flight.FlightServerBase. Flight has predefined RPC methods to send and receive data and metadata, but the default implementations just raise an error, so we will need to override these to implement more functionality into our application. (You can find all the RPC methods listed in the documentation for flight.FlightServerBase.)
In this example, we want our TestServer to be able to do 2 things:
- Store tables on the server.
- Stream a table to the client when requested.
Let’s look at these implementations in a greater detail.
A similar, but more featureful, example is available in the Apache Arrow Cookbook.
Storing Data on the Server
The first thing we need to do is to customize the do_put method that comes with the flight.FlightServerBase to allow a client to store the data on the server. When a user calls do_put method on a Flight client, it returns a writer object that the user can write Arrow data to. At the same time, Flight will call our do_put method on the server side, where the reader object will get all the Arrow record batches that the client’s writer object pipes to the server.
python
def do_put(self, context, descriptor, reader, writer):
# stores the table in the dict of tables
self.tables[descriptor.command] = reader.read_all()
Great, now we have something ready to receive data and store it for any client that asks for it.
Retrieving the Data from the Server
Now, let’s create a method that can request the data. We will override the do_get implementation to return a RecordBatchStream that converts a pyarrow.Table in our example. This will create a stream of RecordBatch objects that can be then read by the client (see the get_table method implementation in the Getting the Data Back section).
python
def do_get(self, context, ticket):
# retrieves the table and sends it over the stream
table = self.tables[ticket.ticket]
return flight.RecordBatchStream(table)Create a Client
Now, let’s create a client that connects to the server and interacts with it. First, import the necessary modules.
python
import pyarrow as pa
import pyarrow.flight as flight
import pyarrow.parquet as pqOur client just wraps the FlightClient object created by calling the flight.connect method.
python
class FlightClientTest:
def __init__(self, location):
self.con = flight.connect(location)
self.con.wait_for_available()
Pushing Data to the Server
The do_put client method requires a descriptor of the flight we will ship to the server side as well as the schema of the table. In return, as mentioned earlier, we receive a writer we can write our table to; note, that we do not need to change or serialize the pyarrow.Table object. We simply pass it to the put_write.write method as a parameter.
python
# Send a pyarrow.Table to the server to be cached
def cache_table_in_server(self, name, table):
# create the flight descriptor
desc = flight.FlightDescriptor.for_command(name.encode("utf8"))
# establish the stream to the server
put_writer, put_meta_reader = self.con.do_put(
desc, table.schema
)
# write the data and clean up
put_writer.write(table)
put_writer.close()Once done writing, we just close the stream.
Getting the Data Back
Once the data is transferred to the server and cached, we can retrieve it using the do_get method on the Flight client, passing a flight.Ticket that contains a name of the table to retrieve. As with the do_put method, calling do_get will cause Flight to call the corresponding method on the server for us. The do_get method returns a reader that can read all the RecordBatch objects the do_get method on the server pipes through. All of this is wrapped in the get_table method we will define:
python
# Get a pyarrow.Table by name
def get_table(self, name):
# establish the stream from the server
reader = self.con.do_get(flight.Ticket(name.encode("utf8")))
# return all the data retrieved
return reader.read_all()Start Communicating
Now that we have the server and the client ready, let’s start the server. In this example we will start the server in a thread.
python
if __name__ == "__main__":
import threading
# create location
location = flight.Location.for_grpc_tcp("localhost", 6666)
# create the server object
server = TestServer(location)
# start the server
thread = threading.Thread(target=lambda: server.serve(), daemon=True)
thread.start()
if thread.is_alive():
print(f'Server is running! {location.uri.decode("utf-8")}')
while True:
try:
thread.is_alive()
time.sleep(60)
except KeyboardInterrupt:
print("\nStopping the server...")
thread.join()
print("Server stopped...")
breakLet’s now create a client.
python
if __name__ == "__main__":
location = flight.Location.for_grpc_tcp("localhost", 6666)
client = FlightClientTest(location)Ship Data to the Server
Let’s now store some data on the server: we will read a 2GB Parquet file and then send the data over to the server.
python
# Read data from file and store in the server
sample_table = pq.read_table("../data/large_dataset_snappy.parquet")
print(f"\nSize of the table: {(sample_table.nbytes / (1024**3)):.2}GB")
print("Caching the table...")
time_execution(
'client.cache_table_in_server("large_table", sample_table)',
globals = {'client': client, 'sample_table': sample_table},
repeat = 5,
number = 10
)We use the following helper method to time how long the caching takes.
python
import timeit
def time_execution(method, globals, repeat, number):
timer = timeit.Timer(
method,
globals=globals
)
timings = [timing / number for timing in timer.repeat(repeat, number)]
print(f'Best timing out of {repeat} loops: {min(timings):.4}s, '
f'avg/stdev: {np.mean(timings):.4}s/{np.std(timings):.4}s, '
f'total execution time ({repeat} loops {number} times each): '
f'{sum(timings) * number:.4}s')Thus, the output from running the above code should yield something similar to below.
python
Size of the table: 2.0GB
Caching the table...
Best timing out of 5 loops: 1.826s, avg/stdev: 1.842s/0.01466s, total execution time: 92.1sNote the times might differ for you but should not be substantially different.
If you do not have a parquet file you can quickly generate one using the code below.
python
import pyarrow as pa
import pyarrow.parquet as pq
import numpy as np
def generate_data(dataset_size, cols):
data_type = np.dtype('float64')
rows = dataset_size / cols / data_type.itemsize
print(f'Memory size: {dataset_size / (1024**3)}GB')
print(f'Number of rows: {int(rows):,}')
print(f'Number of columns: {cols}')
return pa.table(
{
f'col_{i}': np.random.randn(int(rows))
for i in range(cols)
}
)
table = generate_data(2 * (1024**3), 64)
pq.write_table(table, "../data/large_dataset_snappy.parquet")So, on my moderate machine with a dated Intel quad-core i5 processor it takes around two seconds to push the data to the server.
For comparison, a traditional way of communicating between processes or over the network would be to convert the data to an intermediary binary format (pickle, or byte representation of a JSON string, for example), send it to the receiving node, and finally unpack from the intermediate representation to a required format.
To compare the times between the simple solution and the one using Arrow Flight we devised a simple example that uses Python’s socket library to send and receive the data. On the client side we first need to convert the data to JSON and encode it to a binary representation before sending it to the server.
python
def send_data(s, table):
print('Converting to JSON...')
start = time.monotonic()
msg = table.to_json().encode('utf-8')
end = time.monotonic()
print(f'Completed... It took {(end - start):.0f} seconds to finish...')
s.sendall(len(msg).to_bytes(32, sys.byteorder))
print('Sending data...')
start = time.monotonic()
s.sendall(msg)
end = time.monotonic()
print(f'Data sent... It took {(end - start):.0f} seconds to finish...')The receiving end retrieves the data and converts it back to a pandas Dataframe
python
def read_data(self):
print('Receiving data...')
received = 0
packet = b""
data_size = int.from_bytes(self.conn.recv(32), sys.byteorder)
print(f'Expecting {data_size / (1024**2):.2}MBs')
while received < data_size:
packet = self.conn.recv(PACKET_SIZE)
self.storage['data'].append(packet.decode('utf-8'))
received += len(packet)
print('Data received... Converting to dataframe...')
start = time.monotonic()
self.dataframe = pd.read_json("".join(self.storage['data']))
end = time.monotonic()
print(f'It took {(end - start):.0f} seconds to convert to a dataframe...')After executing the above code one can clearly see the deficiencies of serialization and deserialization.
python
(client) Converting to JSON...
(client) Completed... It took 32 seconds to finish...
(client) Sending data...
(server) Receiving data...
(server) Expecting 5.9e+03MBs
(client) Data sent... It took 4 seconds to finish...
(server) Data received... Converting to dataframe...
(server) It took 207 seconds to convert to a dataframe...
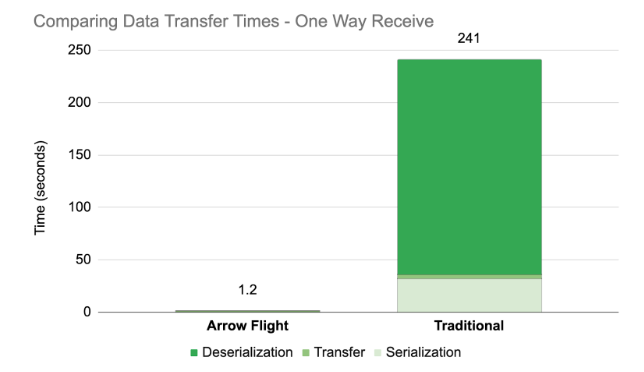
So, a one way data transfer (even if we exclude the conversion back to a dataframe that took almost 4 minutes) took 36 seconds, most of which was spent converting the data to an intermediate representation. What’s more, sending the data also took longer as the JSON binary representation is significantly larger than an Arrow’s table.
Retrieving the Data
Retrieving the data is as simple as calling the .get_table(...) method of our client.
python
print("\nRetrieve the table...")
time_execution(
'client.get_table("large_table")',
globals = {'client': client},
repeat = 5,
number = 10
)Getting the table back results in about the same time as sending it over to the server.
python
Retrieve the table...
Best timing out of 5 loops: 1.205s, avg/stdev: 1.21s/0.007365s, total execution time: 60.49sReceiving the data the traditional way requires similar time as sending it to the server (the code to achieve is pretty much the same as presented earlier just in reverse).
python
(server) Converting to JSON...
(server) Completed... It took 32 seconds to finish...
(server) Sending data...
(client) Receiving data...
(client) Expecting 5.9e+03MBs
(server) Data sent... It took 4 seconds to finish...
(client) Data received... Converting to dataframe...
(client) It took 207 seconds to convert to a dataframe...Summary
Arrow Flight is a convenient and extremely performant protocol for shipping data between processes or over the network. If your data pipeline requires jumping between runtimes or you are sending data between compute nodes, adopting Flight will likely boost your data throughput.
If you want to learn more about Flight and its derivatives (like Flight SQL), we recommend watching this content from The Data Thread:
For more examples, check out the Arrow Cookbook, or to learn more about Flight’s protocol, read the documentation. Voltron Data also offers services designed to accelerate success with the Apache Arrow ecosystem. Explore our enterprise subscription options today.
[Photo credit: Cherenkov radiation glowing in the core of the Advanced Test Reactor by Argonne National Lab. Public Domain]