Inside Ibis: Contributors Weigh In Ahead of the 4.0 Release
By
V
Voltron DataAuthor(s):
V
Voltron DataPublished: January 6, 2023
4 min read
It is no secret that we’re big supporters of the Ibis project. We believe in the value Ibis brings to the ecosystem and actively support the open source maintainers who are working on the project. Over the past two years, Ibis has significantly grown in popularity. From 2016 - 2022 Ibis had a total of 8,931,985 downloads total. Over 8.2 Million of those downloads happened in the last two years (without including downloads through Conda).
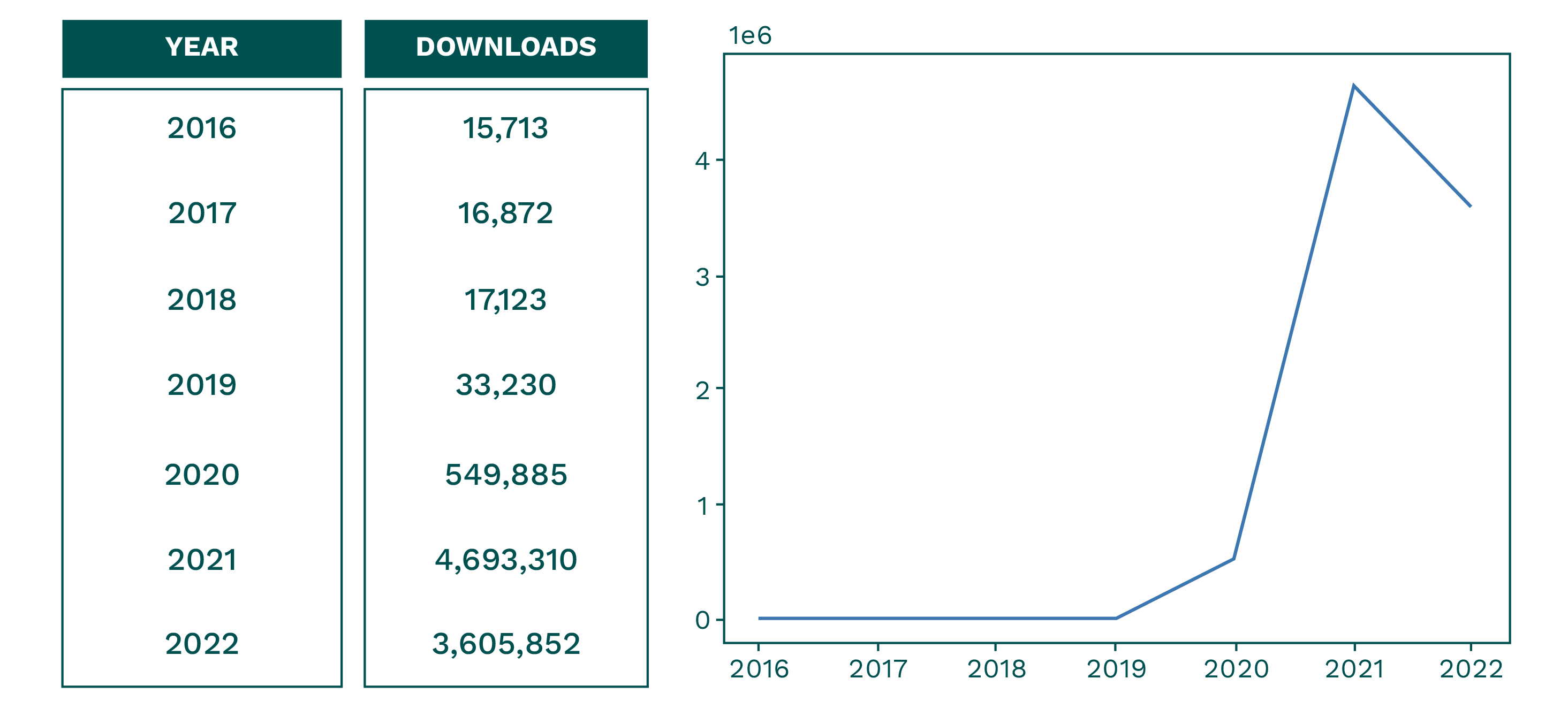
Downloads table 2016-2022 (Datasource: PyPI Big Query Dataset)
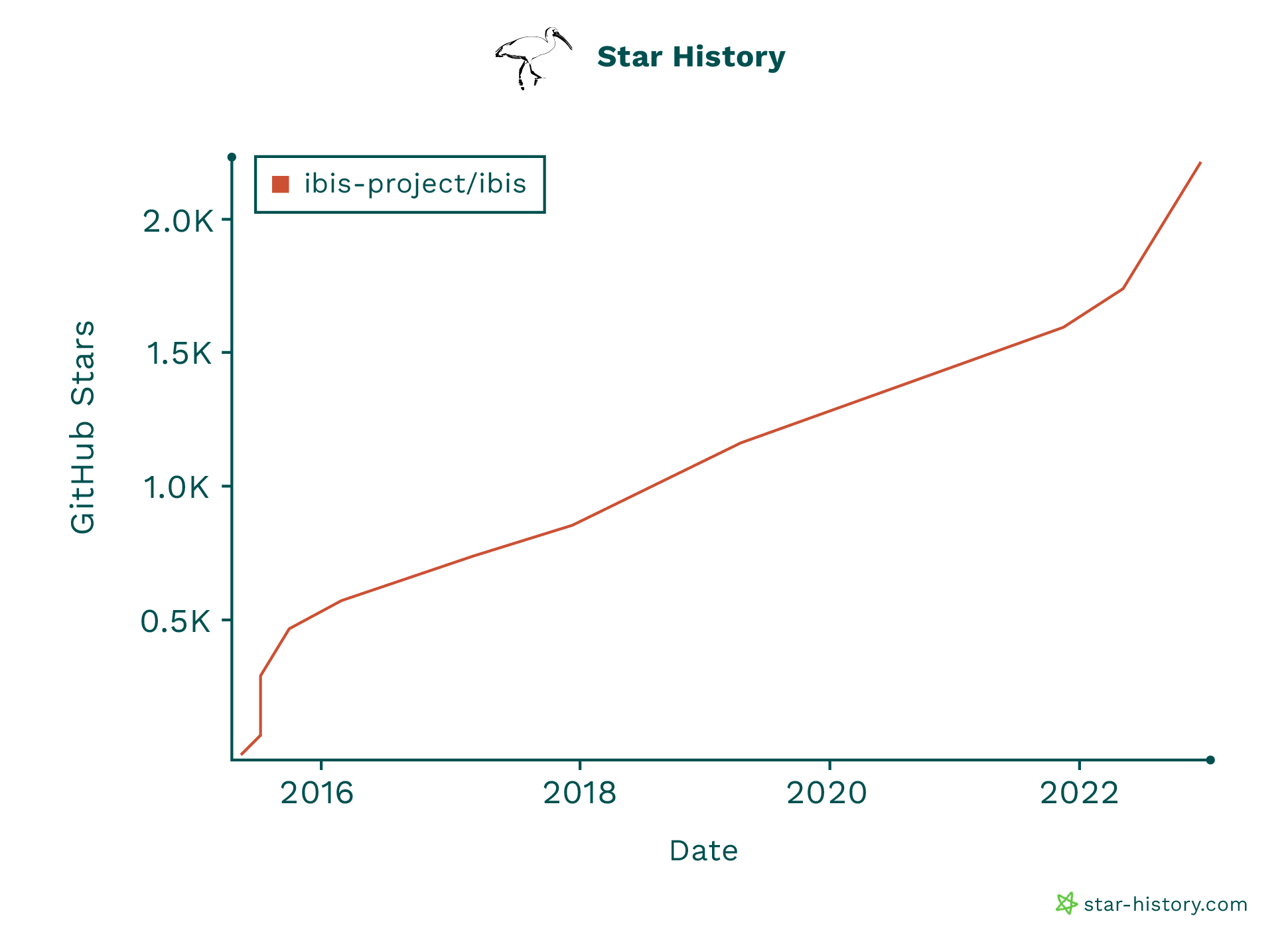
The rise in popularity of Ibis isn’t only displayed by the number of times it’s been downloaded, but also by the project’s support on GitHub. The project has been starred over 2,200 times, with new contributors onboarding regularly.
Dataset
We caught up with key Ibis maintainers and contributors to learn about the progress made last year and what’s in store for the Ibis 4.0 release slated for January 2023. During our conversations, one sentiment was abundantly clear: the team wants to grow the community and see more individual contributions over the next year. Read on to get an inside look at what it’s like to work on Ibis.
First, how would you describe Ibis to someone who hasn’t heard of it?


Tell us about a rewarding contribution you made last year.


Phillip Cloud is the lead maintainer for Ibis and his work is particularly helpful for contributors to Ibis. Automating releases and reducing CI times not only makes contributing easier, but increases support for future technologies and backends. From simple documentation changes to adding a new backend to massive and complicated refactors, an improved CI and helpful feedback from the team makes contributing to Ibis a breeze.
What’s in store for the next Ibis release?


As Ibis’ core continues to be revamped, we are already seeing changes such as the addition of the Polars and Snowflake backends that Phillip and Krisztian mentioned. Additionally, as ibis-substrait matures, it will become easier than ever to utilize Substrait consumers like Acero through Python, creating those free and open source data pipelines that can be immensely valuable to research and development.
Where do you hope Ibis will be a year from today?


Get involved with Ibis
Ibis is implementing open source standards so people can develop and contribute to the advancement of the technology without worrying about learning new APIs. If you’re interested in contributing, check out the “Contribution” docs on the Ibis page and be sure to review the Code of Conduct. We think you’ll discover that this is an exciting project and community with serious growth potential.
Previous Article

Keep up with us


