Speeds and Feeds: Hardware and Software Matter
By
K
Keith BrittAuthor(s):
K
Keith BrittPublished: March 30, 2023
5 min read
Accelerated Hardware Analytics is Here
Proper use of hardware will lead to working smarter, moving faster, and spending fewer resources. We design and build composable data systems based on deep hardware expertise that leads businesses to maximize the use of CPUs, GPUs, networking, and storage solutions with accelerated data engines.
Mimoune Djoulallah recently tested how long it would take to sort a parquet file using different engines. They generated a 60 million row file that took up ~17GB of space. The goal was to test how long it takes to return the data in the parquet file in sorted order and then write that sorted data back as a parquet file.
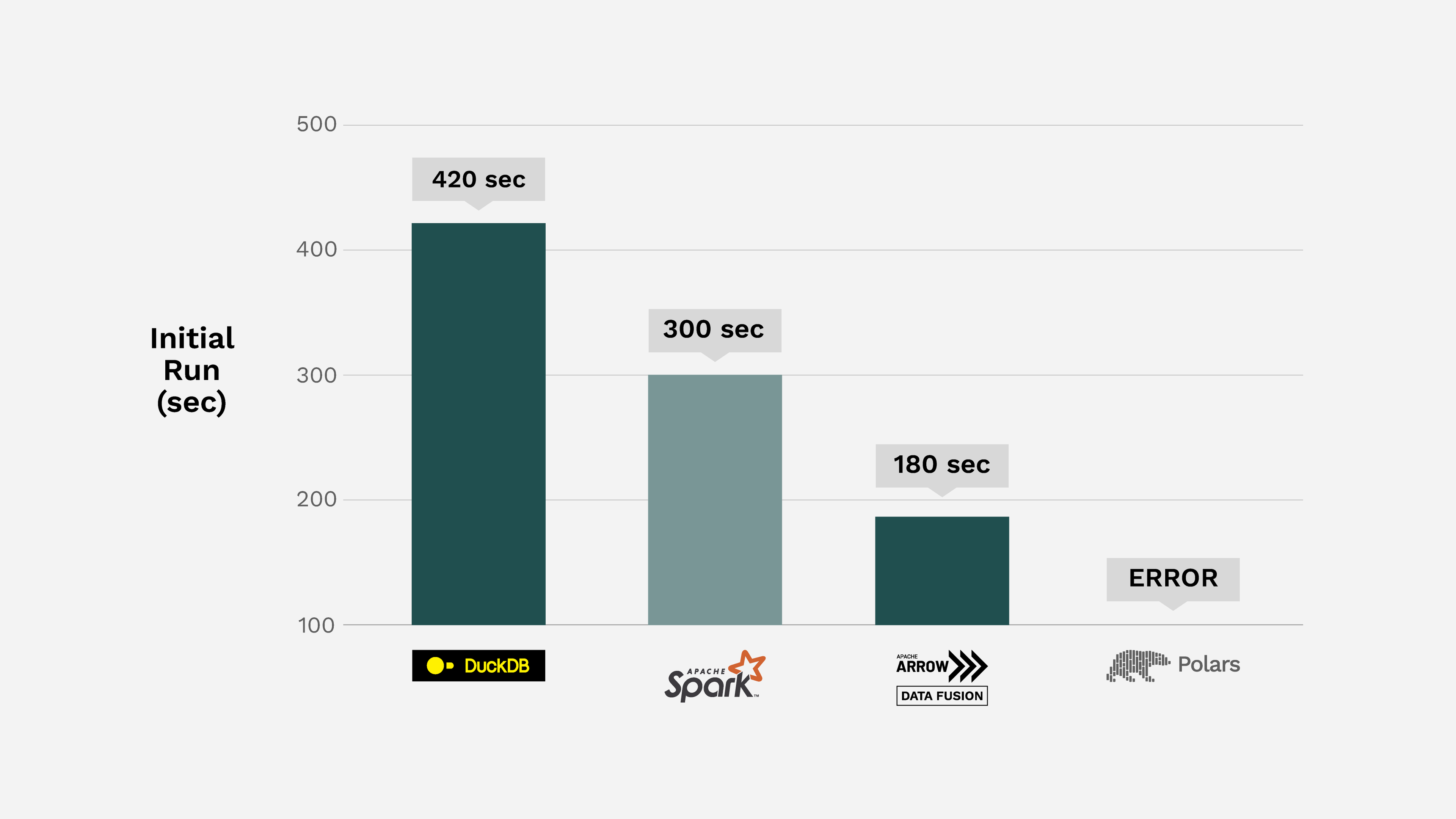
Figure 1. Reading, sorting, and writing 60 million rows to and from Apache Parquet using Google Colab instance with 2 cores of Xeon E5-2699 v4 @ 2.2GHz and 12.7 GB of RAM.
This is very similar to the preprocessing step that many organizations may need to use for a search algorithm or to prepare data for visualization such as a dashboard. For example compliance with General Data Protection Regulation (GDPR) requires search with a fine tooth comb, and in large data stores, this can be a heavy burden as seen by these benchmarks specific to GDPR.
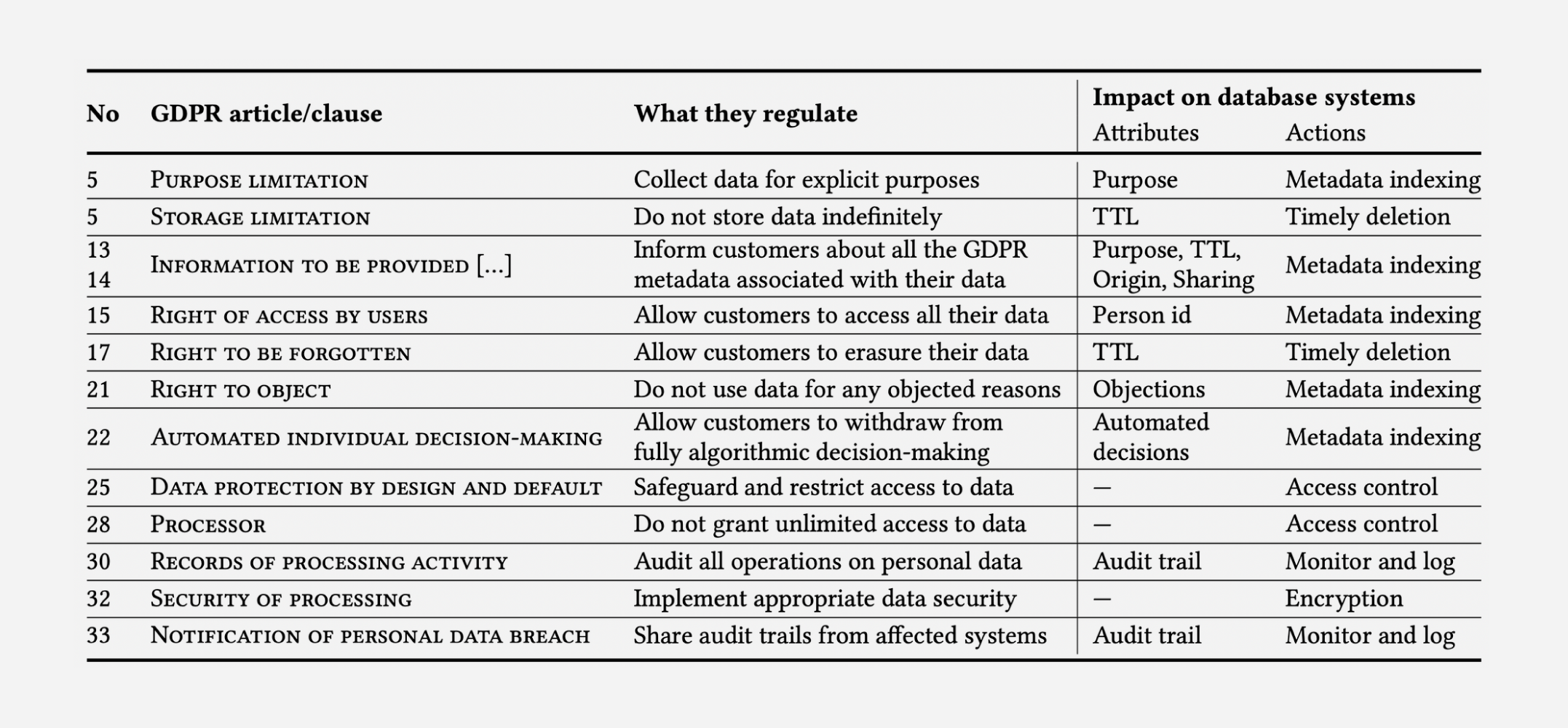
Figure 2. Shows how GDPR compliance causes impact database systems
This exercise is applicable to situations were developers are seeking practical feedback on theoretical performance improvements in differing software stacks. When data is sensitive and measures must be implemented to protect personal information, in the case of GDPR, it’s important to use optimal software as regulatory compliance spending is expected to reach 8 Billion if technology doesn’t improve.
Accelerating Parquet with Software & Hardware
Mimoune’s work caught the attention of John Murray. John replicated Mimoune’s code on Fusion Data Science’s Sorites cluster, a moderately powerful Dell & NVIDIA system (2 Intel Xeon processors at 44 threads each with a max frequency of 3.6 GHz paired with 2 NVIDIA V100 Tensor Core GPUs all serviced by 1 terabyte of RAM) and found the hardware alone had dramatically improved the results.
On John’s system (specification in chart), most backends were able to process the parquet file in under a minute. As expected the performance is hardware dependent and non-SQL solutions like Apache Arrow, and RAPIDS cuDF (tested using an NVIDIA GPU) saw considerable improvement.
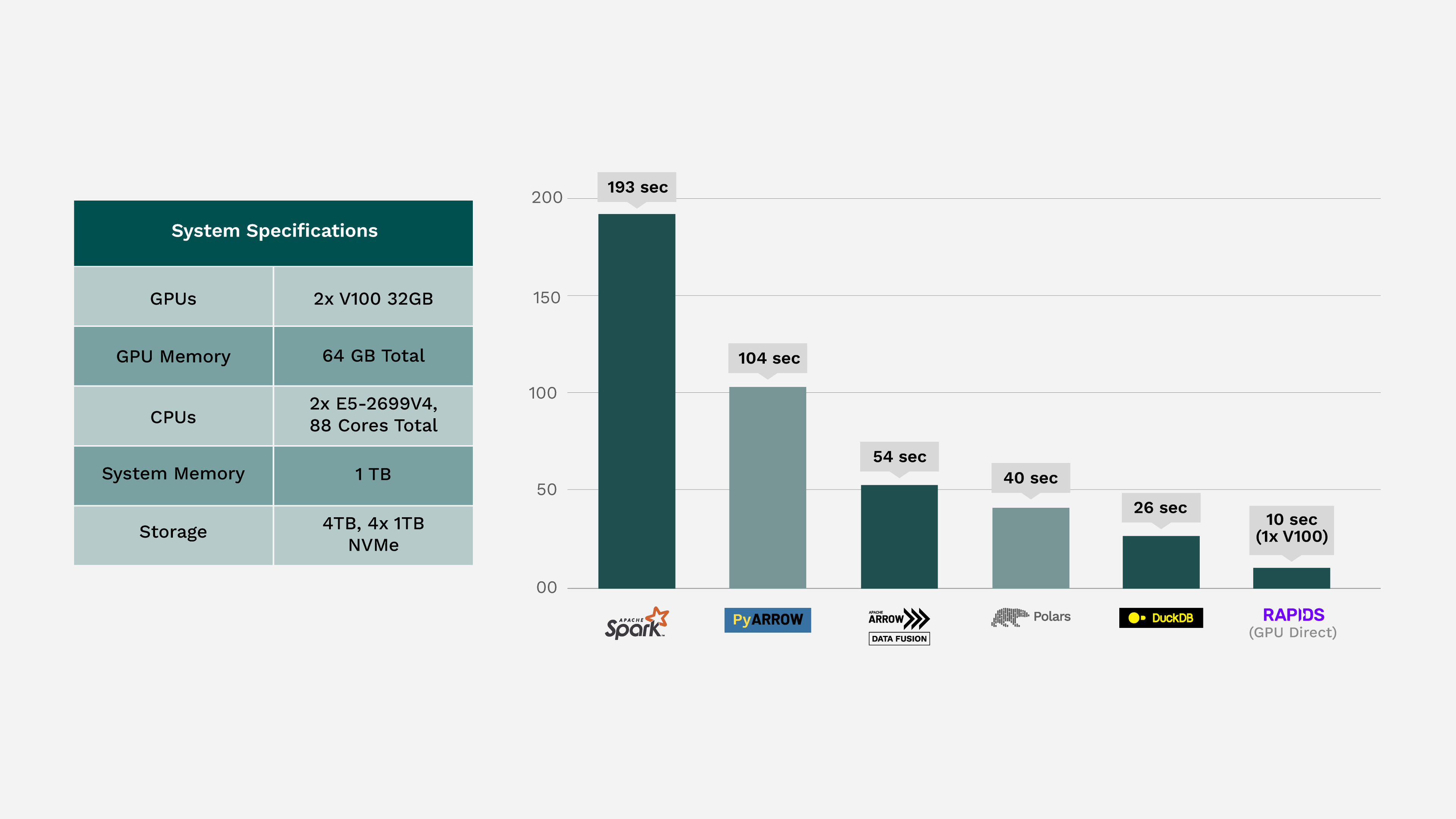
Figure 3. Reading, sorting, and writing 60 million rows to and from Apache Parquet running on a modern compute node with NVIDIA GPUs
Both tests showed that Apache Spark was the worst performing backend regardless of hardware. Using GPU accelerated hardware, a single NVIDIA GPU is able to outperform 88 x86 CPU cores by at least ~2.5 times using a single NVIDIA V100. That means a single GPU outperforms Spark on an 88 core cluster by 20x. Most servers would have four to eight GPUs like these, so you can imagine the speedups as data increases.
In conclusion, it’s not just the type of backend that matters. When picking a backend, it matters how the data is structured and what hardware you’re running on. A columnar, compressed format is a perfect data structure for CPU and GPU alike, and it also turns out to be a perfect data structure for data science.
We’d love for you to carry on the thread and post your own results in the comments. You can find Mimoune’s original code here. If you’d like to learn how you can achieve this kind of performance at your organization, come talk to us.
Voltron Data helps people store, process, and analyze their data more efficiently. In addition to accelerating system performance - we’re here to talk about Parquet, Ibis, Arrow, or any other open source product we support, check out our subscription page or shoot us an email.
Special thanks to: Mimoune Djoulallah, Business Intelligence Analyst based in Australia and John Murray, Director of Fusion Data Science based in the UK - for sharing their findings with the community and consulting with Voltron Data on this article.
Photo source: Jakob Braun
Previous Article

Keep up with us


