Data Analytics are Faster on GPUs - Here’s Why
By Voltron Data
Voltron Data
Author(s):
Published: June 5, 2025
7 min read
See How Theseus Executes a Join Operation on Multiple GPUs
In a world increasingly driven by data, the computational landscape is at a pivotal juncture. For decades, Moore's Law—the idea that CPU performance doubles every two years — has guided the development of software and hardware. However, as hardware and transistors approach physical limitations, CPUs are no longer keeping pace with the exponential growth of data and computational demands. Enter the accelerated computing revolution, led by GPUs and companies like Voltron Data, which redefines how we process and analyze data at scale. Accelerated computing harnesses the power of GPUs and other specialized hardware to overcome the performance limitations of CPU systems.
Voltron Data is at the forefront of this GPU software revolution, building solutions like Theseus, a GPU-accelerated SQL engine designed to process petabyte-scale datasets in minutes rather than hours or days. By focusing on hardware-aware software, Voltron Data enables businesses to leverage GPUs for tasks traditionally dominated by CPUs, such as:
- GPU-Accelerated Joins at Scale: Handling complex, multidimensional queries with massive joins, sorts, and aggregations without the performance bottlenecks of legacy systems.
- Real-Time Insights from Raw Data: Transforming telemetry, log, and transactional data directly into actionable insights without pre-processing and ingestion overhead.
- AI and ML Pipeline Integration: Seamlessly integrating with AI workflows, Theseus accelerates the processing of data required for model training and inference.
This article will focus on how data analytics is processed on GPUs and help explain why this workload is more efficient and performant. We will use the example of typical join operations to showcase how data moves through the system and how Theseus leverages modern algorithms and fastest-in-class GPU execution.
How a Join Executes Across Multiple GPUs
In this example, a partition hash join begins with scanned data distributed across 3 GPUs (GPU0, GPU1, GPU2). The data is divided into distinct subsets through local hash partitioning, ensuring each GPU processes its own partition. Once partitioned, the data is shuffled between GPUs, enabling each to perform a local join. The join involves building a hash table on one side and probing that hash table with the other side.
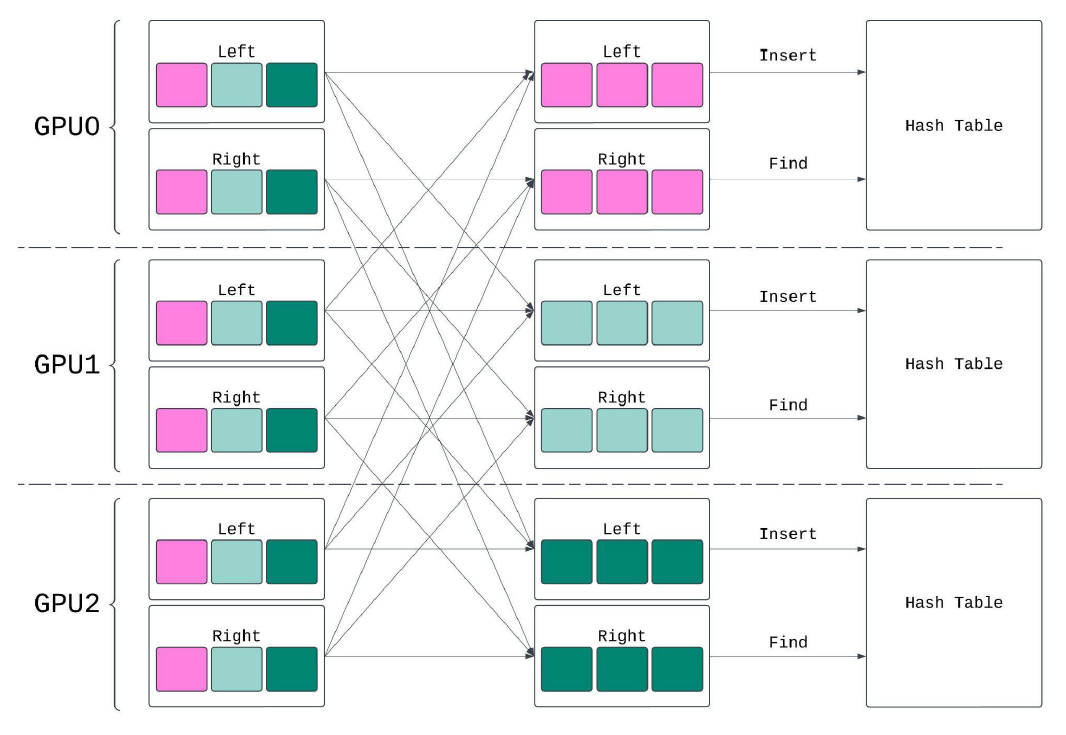
The Anatomy of a Join Operation
A GPU join operation has approximately 5 steps.

I/O
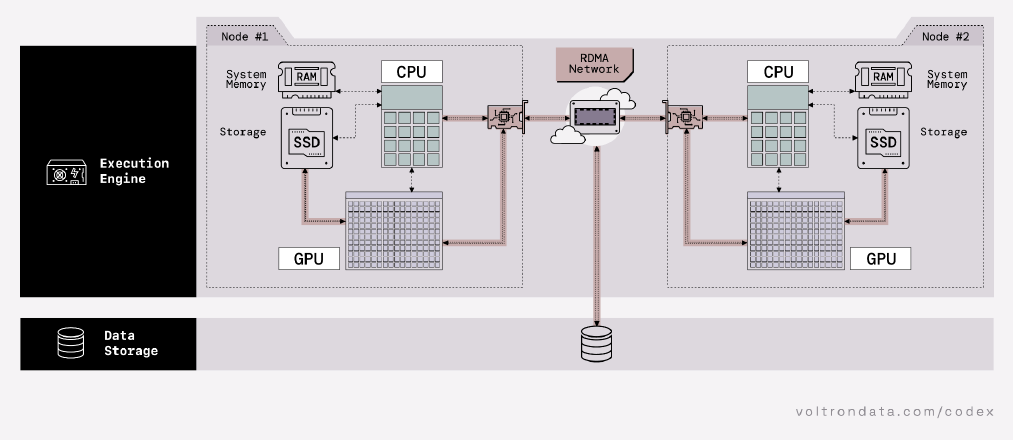
A GPU join begins with data ingestion from storage (I/O). The GPU server is optimized for speed with direct connections to SSDs and the network interface card (NIC), bypassing the CPU and system memory. This is done using GPUDirect Storage (GDS). Leveraging GDS eliminates PCIe bottlenecks and enables efficient data transfers from centralized storage via the NIC. With accelerated storage solutions like WEKA or VAST, data can move directly from SSDs to GPUs, achieving terabytes per second of throughput.
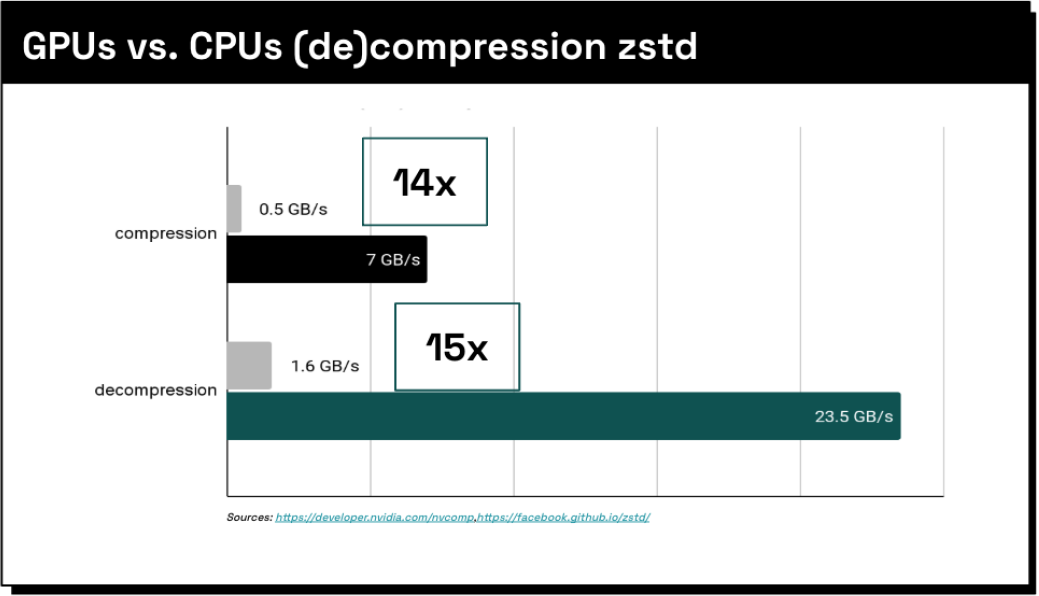
Decompression and Decoding
Files like Parquet or ORC are often compressed to save space and must be decompressed and decoded before the join operation. GPUs excel at decompression, outperforming CPUs by 15x for formats like Zstandard, according to NVIDIA’s NVComp benchmarks. This allows compressed data to be transferred efficiently and decompressed directly on the GPU, minimizing data movement overhead. The speedup is even greater for compression formats like Snappy, Run Length Encoding (RLE), or Bit Packing. This combined with faster decoding directly on the GPU provided by the RAPIDS cuDF library means that you aren't compute-bound when reading files into in-memory data frames.
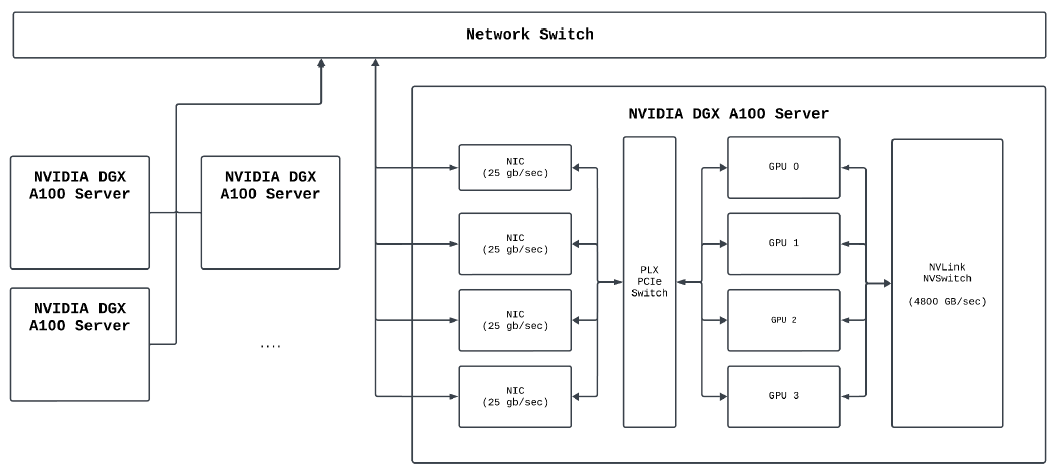
Hash Partition and Shuffle
The next step is the hash partition phase, followed by the shuffle. The hash partitioning happens on the GPU, then data is sent over OpenUCX. With OpenUCX we can leverage fast paths and RDMA between the memory of devices (GPUs) and hosts (RAM). We can move data from GPU0 to GPU1 over NVLink at 600 gigabytes per second and send data using NVSwitch between GPU0 and a GPU on another DGX server at 25 gigabytes per second per GPU. The way that we have things configured, one GPU can take advantage of two of these NICs simultaneously so it can burst up to 50 gigabytes per second per GPU. This is made possible by UCX, which automatically handles data routing. Whether transferring data between GPUs on the same node or across different servers, the communication protocol remains consistent, allowing seamless integration across various topologies.
Local Join
The last step of this join is where we perform the local join. Here we leverage libraries RAPIDS cuDF and NVIDIA cuCollections, which enable an insert into the map at 88 gigabytes per second and a probe of it at 135 gigabytes per second, This is per GPU. On an 8-node cluster, you can insert at 640 gigabytes per second and probe at over a terabyte per second on a single server.
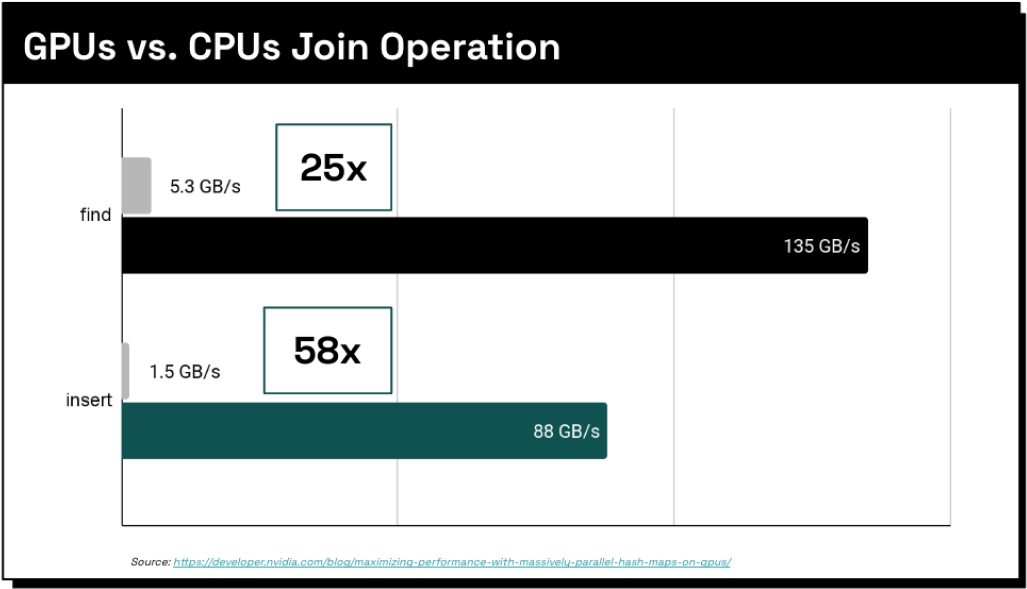
Theseus seamlessly handles larger-than-memory joins capable of spilling to host memory or even disk when joins have outputs measured in Terabytes. We leverage core NVIDIA libraries, OpenUCX, and GPUDirect Storage to keep all operations with the GPU, distributing work elegantly to many nodes for parallel task execution.
Enterprises are leveraging GPUs for Analytics Today
Enterprises are leveraging these advancements for significant performance gains over CPU-based systems. A top U.S. bank accelerated its credit risk model pipeline, from raw data to ETL and feature engineering in XGBoost, reducing analytics costs by over 98%. The bank scaled from a 40GB data sample to the full 1.15TB dataset, achieving a 72x faster pipeline with improved model accuracy.
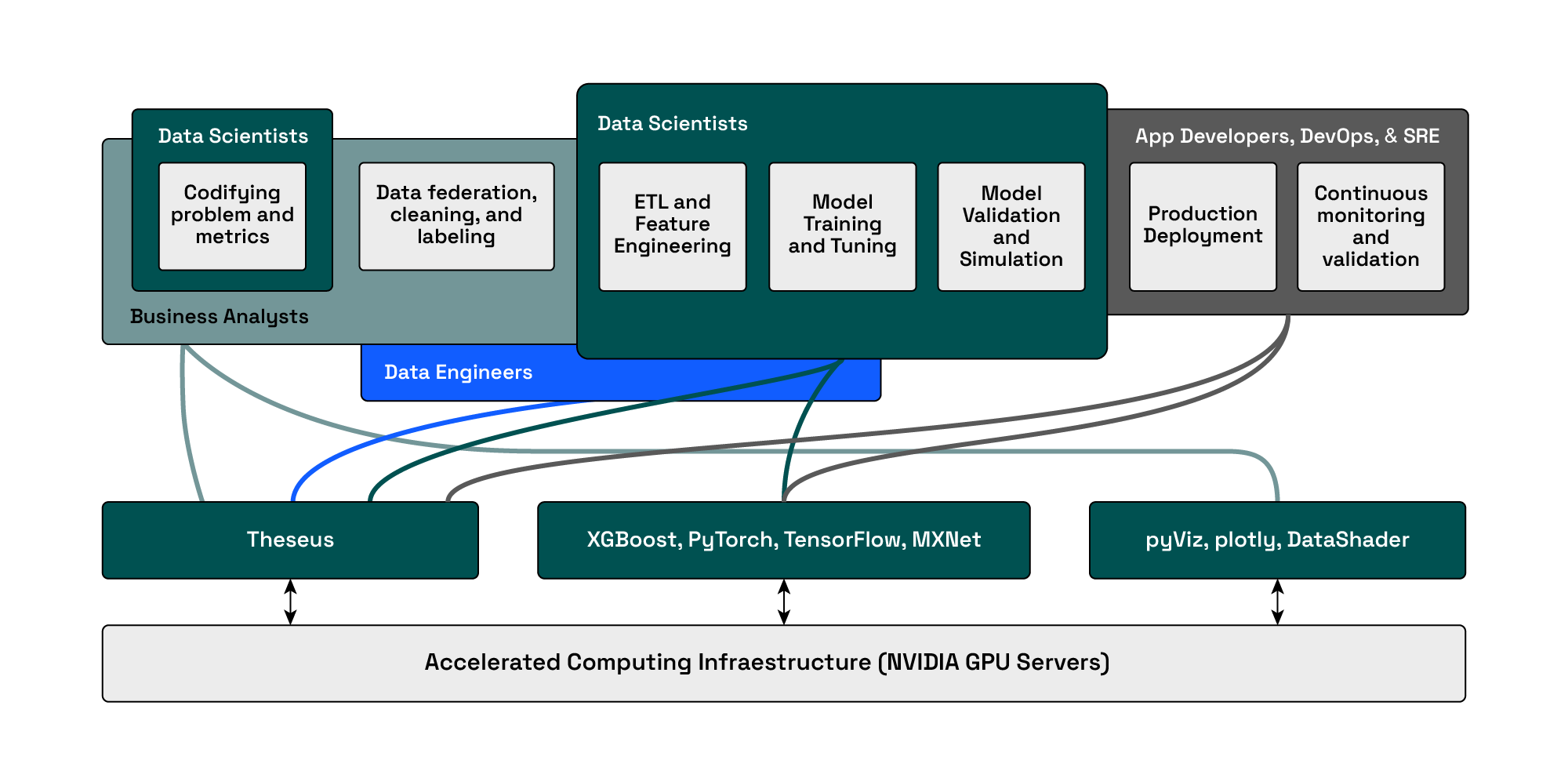
A range of technologies spanning ETL, data analytics, machine learning, and data visualization tools impact workflows for data scientists, business analysts, and data engineers. We encourage you to explore our work and NVIDIA's RAPIDS ecosystem, which underpins many of these advancements. Consider the possibilities: reducing 20-hour Spark jobs to 20 minutes, running larger datasets, or replacing hundreds of CPU servers with a handful of GPUs. This lowers cloud and data center costs for enterprises and also addresses energy constraints, enabling significant energy savings and unlocking new capabilities.
Wrap up
The future of accelerated SQL analytics is here. Stay tuned as we continue to push the boundaries of performance, efficiency, and cost savings.
For more details on our benchmarking process, see our Theseus Benchmarking Report, where we break down the results, methodologies, FAQs, and system specifications.
Remember, it’s all about how fast your queries run and what it costs to run them. Theseus delivers. Join our mission to slash the cost of analytics and give Theseus a try.
Previous Article

Keep up with us


