Use Apache Arrow and Go for Your Data Workflows
By
M
Matt TopolAuthor(s):
M
Matt TopolPublished: March 27, 2023
9 min read
Voltron Data is building open source standards that support a multi-language programming future (or, polyglot, as we say). Central to this vision is the Apache Arrow project.
To demonstrate Arrow’s cross-language capabilities, Matt Topol, Staff Software Engineer and author of In-Memory Analytics with Apache Arrow, wrote a series of blogs covering the Apache Arrow Golang (Go) module. This series will help users get started with Arrow and Go and learn how both can use both to build effective data science workflows.
Next up in the series:
- Go and Apache Arrow Help Make Data Files Easier to Work With
- Data Transfer Using Apache Arrow and Go
- Zero-Copy Sharing Using Apache Arrow and Go
Go isn’t generally the first language that comes to mind when you think about Data Science and Data Engineering. While it’s true that Go doesn’t have a robust data frame library such as pandas or Polars for Python, there are still significant advantages to using Go for a variety of data use cases. Something that will help you on your journey is the Apache Arrow and Parquet libraries for Go, which is precisely what I plan to discuss and introduce you to in this post.
If you’re not yet familiar with Apache Arrow, it’s a language-independent columnar memory format. There are a variety of implementations in multiple programming languages (including C++, Go, Java, Python, R, Rust, Julia, and more), along with helpful utilities for using Arrow formatted data. By leveraging the benefits of column-oriented processing, vectorized CPU and GPU operations, and a common memory format, Arrow provides high-performance analytics and data-interchange workflows in nearly any space that works with tabular data. I’ll talk more about Arrow itself later, but if you really want to learn more about it right away, I highly recommend checking out the official site at https://arrow.apache.org or my book about Arrow, “In-Memory Analytics with Apache Arrow”.
This brings us to Go.
Why use Golang?

Artwork by: Ashley McNamara under Creative Commons Attribution-NonCommercial-ShareAlike License
Go (or Golang) is an open source programming language that was originally developed at Google and later released to the community in 2009. Go runs very fast since it compiles down to native machine code rather than being run through an interpreter. Some other benefits include:
- Go’s syntax is relatively simple and easy to pick up. Don’t believe me? Try out the Tour of Go!
- Go has a series of built-in concurrency primitives which help developers write code to take advantage of multi-core CPUs, making it significantly easier than in many other languages.
- The resulting binaries built by Go, while large on average, are often statically built, allowing them to be easily deployable.
- Go’s mascot is the adorable Go Gopher, which is, of course, certainly the best reason to use it. Obviously.
Okay, now that we’ve gotten the basics out of the way, let’s jump in.
Gophers and Arrows
The Apache Arrow 11.0.0 release introduced new features and bug fixes for Go users, among other implementations. The Arrow Go modules provide utilities for importing and exporting data via Arrow’s Inter-process Communication (IPC) streams, along with CSV, JSON or Apache Parquet files. This release also brought with it a series of experimental compute functions letting you directly operate on Arrow data without having to write the routines yourself. Let’s dive in, shall we?
Getting Started with Apache Arrow and Go!
First, you can find the documentation for the Go Arrow module right here: pkg.go.dev. It includes the documentation for both the arrow and parquet packages and their sub-packages. As with any other Go module, you can use go get to download it like so:
bash
$ go get -u github.com/apache/arrow/go/v11@latestWe can get started with a simple example: Building a 64-bit integer array.
Simple Example for Building an Int64 Array
First, the code:
go
package examples_test
import (
"fmt"
"github.com/apache/arrow/go/v11/arrow"
"github.com/apache/arrow/go/v11/arrow/array"
"github.com/apache/arrow/go/v11/arrow/memory"
)
func Example_buildInt64() {
bldr := array.NewInt64Builder(memory.DefaultAllocator)
defer bldr.Release() // <-- Notice This!
bldr.Append(25) // append single value
bldr.AppendNull() // append a null value to the array
// Append a slice of values with a slice of booleans
// defining which ones are valid or not.
bldr.AppendValues([]int64{1, 2}, []bool{true, false})
// Or pass nil to assume all are valid
bldr.AppendValues([]int64{3, 4, 5, 6}, nil)
arr := bldr.NewInt64Array() // can be reused after this
defer arr.Release() // <-- Notice!
fmt.Println(arr)
bldr.AppendValues([]int64{7, 8, 9, 10}, nil)
// get Array interface rather than typed pointer
arr2 := bldr.NewArray()
defer arr2.Release() // <-- Seeing the pattern?
fmt.Println(arr2)
// Output:
// [25 (null) 1 (null) 3 4 5 6]
// [7 8 9 10]
}All array data types have a corresponding Builder type which can be utilized to construct an array. More examples of building arrays of different data types can be found in the documentation. Pay particular attention to the examples for building out nested data types, they can be tricky!
Memory Handling
Did you see the spots in the example with comments telling you to “notice this”? If not, take a second to look at those lines which defer calling the Release methods. If you’re not completely familiar with Go, the defer keyword will ensure a function call happens just before the containing function returns. You’ll often see it used to clean up various resources like closing a file. In this case, we’re ensuring that we call Release on the builder and arrays we’ve created.
Of course, you may wonder “doesn’t Go have a garbage collector? Why are we manually releasing things?” Well, you might also notice the memory.DefaultAllocator which has been passed to create the builder. The Arrow module uses reference counting to track the usage of buffers for managing ownership and trying to eagerly free memory when possible. To facilitate this, there’s the memory.Allocator interface that consists of only three methods:
go
type Allocator interface {
Allocate(size int) []byte
Reallocate(size int, b []byte) []byte
Free(b []byte)
}Ownership and reference counting are all managed by Retain and Release methods on the relevant objects. This is why you repeatedly see the pattern of calling defer <something>.Release() to ensure the reference counting gets cleaned up at the end of the function. It’s also important to do this if you choose to use a custom allocator that uses memory which isn’t managed by Go’s garbage collector. For instance, you can use a custom allocator which utilizes CGO to manage your allocations, in this situation the reference counting is important to prevent memory leaks. The README for the Arrow module has more information and documentation on the Retain and Release methods and how the reference counting works. For the vast majority of users however, the DefaultAllocator, which just uses Go’s built-in allocation via make([]byte, …), will be more than sufficient.
The Arrow library also provides even more control over its memory usage for building array structures, but that’s a topic for another, more in-depth post.
Working with Nested Arrays

Artwork by: Ashley McNamara under Creative Commons Attribution-NonCommercial-ShareAlike License
Aside from primitive arrays of integers, strings, or variable length binary values, Arrow also supports complex types for nested arrays. These are only slightly different to build, as you need to append to both the underlying value builders and the nested array builder itself. Let’s dive in.
List Array
The first example we’ll cover is a basic list array where each element is a list of values. Let’s construct an array that is equivalent to: [ [0 1 2] (null) [3] [4 5] [6 7 8] (null) [9] ]
go
package examples
import (
// ...
)
func Example_listArray() {
pool := memory.NewGoAllocator()
lb := array.NewListBuilder(pool, arrow.PrimitiveTypes.Int64)
defer lb.Release()
// A list array is a list of offsets and a child array
// of the list element type.
vb := lb.ValueBuilder().(*array.Int64Builder)
// don't need to explicitly release this
// releasing the list builder will release its
// value builder.
vb.Reserve(10)
lb.Append(true) // start new list
vb.Append(0)
vb.Append(1)
vb.Append(2)
lb.AppendNull()
lb.Append(true)
vb.Append(3)
lb.Append(true)
vb.Append(4)
vb.Append(5)
lb.Append(true)
vb.AppendValues([]int64{6, 7, 8}, nil)
lb.Append(false) // == lb.AppendNull()
lb.Append(true)
vb.Append(9)
arr := lb.NewListArray()
defer arr.Release()
fmt.Println(arr)
// Output:
// [[0 1 2] (null) [3] [4 5] [6 7 8] (null) [9]]
}As mentioned in the comments, you can see we don’t manually call or defer a call to release the ValueBuilder we get from the ListBuilder. This is because releasing the ListBuilder will automatically release its child builder, which holds true for all of the nested builder types.
Time to get a little more complicated…
Struct Array
A struct array in the Apache Arrow columnar format is a simple structure: it’s a group of arrays with a null bitmap and a schema describing the field names (and optionally metadata). A sample table of data that could be represented as a struct array is:
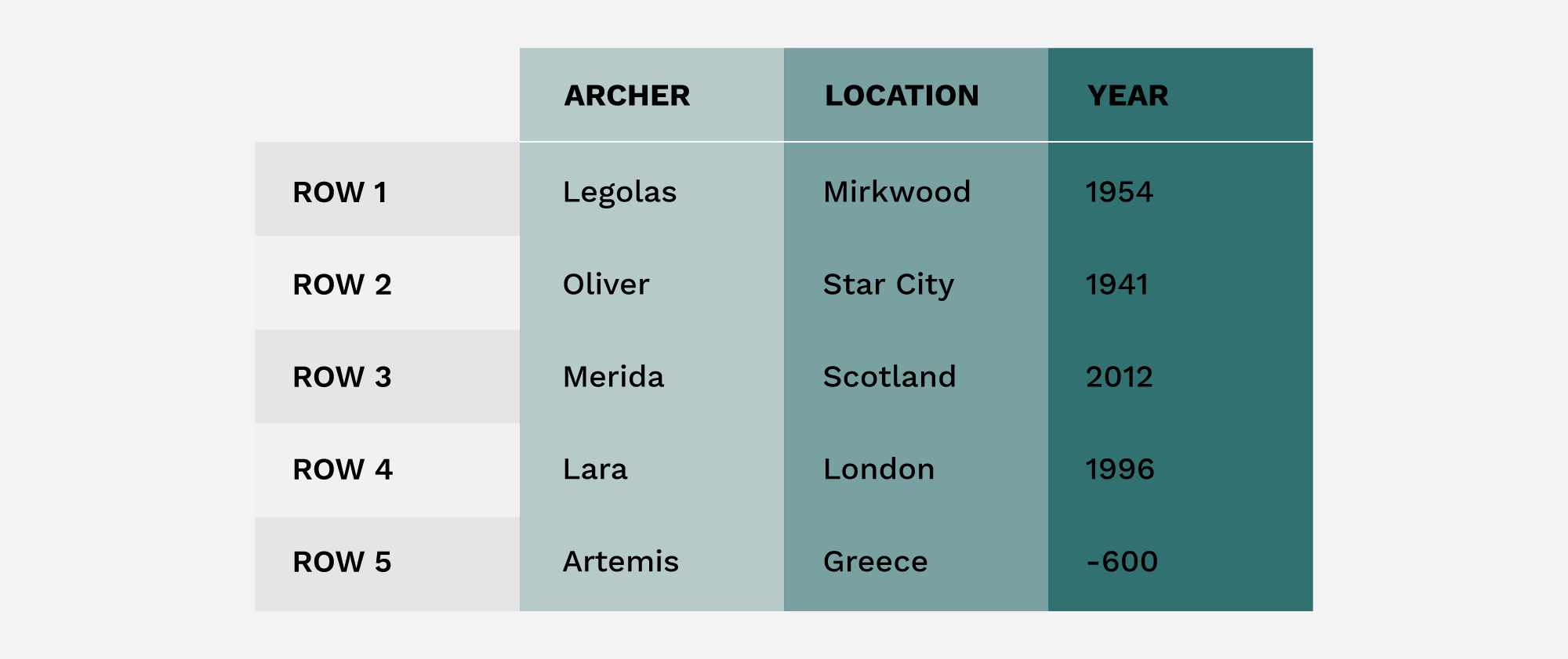
If you were to create a traditional struct to hold this data, it might look like this:
go
type Archer struct {
Archer string
Location string
Year int16
}To create the equivalent struct type for an Arrow Struct Array, you can use the convenience StructOf function:
go
archerType := arrow.StructOf(
arrow.Field{Name: "archer", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "location", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "year", Type: arrow.PrimitiveTypes.Int16},
)Putting this together, we can construct a StructBuilder and build our struct array:
go
func Example_structBuilder() {
archerList := []struct{
archer string
location string
year int16
}{
{"Legolas", "Murkwood", 1954},
{"Oliver", "Star City", 1941},
{"Merida", "Scotland", 2012},
{"Lara", "London", 1996},
{"Artemis", "Greece", -600},
}
archerType := arrow.StructOf(
arrow.Field{Name: "archer", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "location", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "year", Type: arrow.PrimitiveTypes.Int16})
bldr := array.NewStructBuilder(memory.DefaultAllocator, archerType)
defer bldr.Release()
f1b := bldr.FieldBuilder(0).(*array.StringBuilder)
f2b := bldr.FieldBuilder(1).(*array.StringBuilder)
f3b := bldr.FieldBuilder(2).(*array.Int16Builder)
for _, ar := range archerList {
bldr.Append(true)
f1b.Append(ar.archer)
f2b.Append(ar.location)
f3b.Append(ar.year)
}
archers := bldr.NewStructArray()
defer archers.Release()
fmt.Println(archers)
// Output:
// {["Legolas" "Oliver" "Merida" "Lara" "Artemis"] ["Murkwood" "Star City" "Scotland" "London" "Greece"] [1954 1941 2012 1996 -600]}
}
Of course, you don’t necessarily need a StructBuilder. Because a struct array is just a group of arrays with some metadata, you can easily construct a struct array from existing arrays instead. This example has the same output as the previous one.
go
func Example_structArray2() {
// same data as archerList
// same type as archerType
nameBldr := array.NewStringBuilder(memory.DefaultAllocator)
defer nameBldr.Release()
locBldr := array.NewStringBuilder(memory.DefaultAllocator)
defer locBldr.Release()
yearBldr := array.NewInt16Builder(memory.DefaultAllocator)
defer yearBldr.Release()
for _, ar := range archerList {
nameBldr.Append(ar.archer)
locBldr.Append(ar.location)
yearBldr.Append(ar.year)
}
names, locs := nameBldr.NewArray(), locBldr.NewArray()
years := yearBldr.NewArray()
defer names.Release()
defer locs.Release()
defer years.Release()
structData := array.NewData(archerType, names.Len(),
[]*memory.Buffer{nil /* no null bitmap */},
[]arrow.ArrayData{names.Data(), locs.Data(), years.Data()},
0 /* # nulls */, 0 /* offset */}
defer structData.Release()
arr := array.NewStructData(structData)
defer arr.Release()
fmt.Println(arr)
}Got the basics down? Understand how to build arrays and work with them? Awesome!
Implementing Common Use Cases with Go Arrow

Source: GitHub User Content
Several of the most common use cases for Arrow can broadly be described as:
- Reading and writing storage formats
- Efficient movement of data across the network
- Zero-copy sharing of local memory
You can achieve all of these performantly with the Arrow Go module and in the upcoming posts, I will walk you through examples of how to do so, In the meantime, explore the documentation to learn more about the library and its various features.
If you’re working in the Apache Arrow ecosystem and want to accelerate your success with Go or other languages, check out our Enterprise Support offerings or contact us.
Stay tuned for the next installment in the Arrow and Go series. Over the coming weeks, you can expect articles covering these topics:
- Go and Apache Arrow Help Make Data Files Easier to Work With
- Data Transfer Using Apache Arrow and Go
- Zero-Copy Sharing Using Apache Arrow and Go

Keep up with us


