Building data systems is hard: it is expensive, sucks up resources, and few experts are capable of designing and implementing them. But the tides are shifting. Instead of coding from scratch, the pieces are now in place to build by composing first.
In this chapter, we share some of the history behind the design of composable data systems: how it started, what it took, and where we are today. We define the key layers of a data system, and how they can be composed by reusing open source software components and building on top of open standards.
“Invention, it must be humbly admitted, does not consist in creating out of void, but out of chaos”
Mary Shelley.
Author of FRANKENSTEIN
Contents of Chapter 00
0.0 The path to composable data systems
Back in 2010, a movement started without a name.
You can think of it as the "build your own database" (BYODB) movement. Or the "build your own data system" movement. We've also heard the "build your own data engine", the "build your own execution engine", and even the "build your own data processing system" movement.
These companies have effectively started building their own data systems in-house. What does that look like? A typical data system is a collection of both hardware and software that people in an organization can use to work with data. The layers of the system work together so that people can store, access, transform, and analyze data. Databases, Data Warehouses, and Data Lakes are all flavors of data systems you might be familiar with.
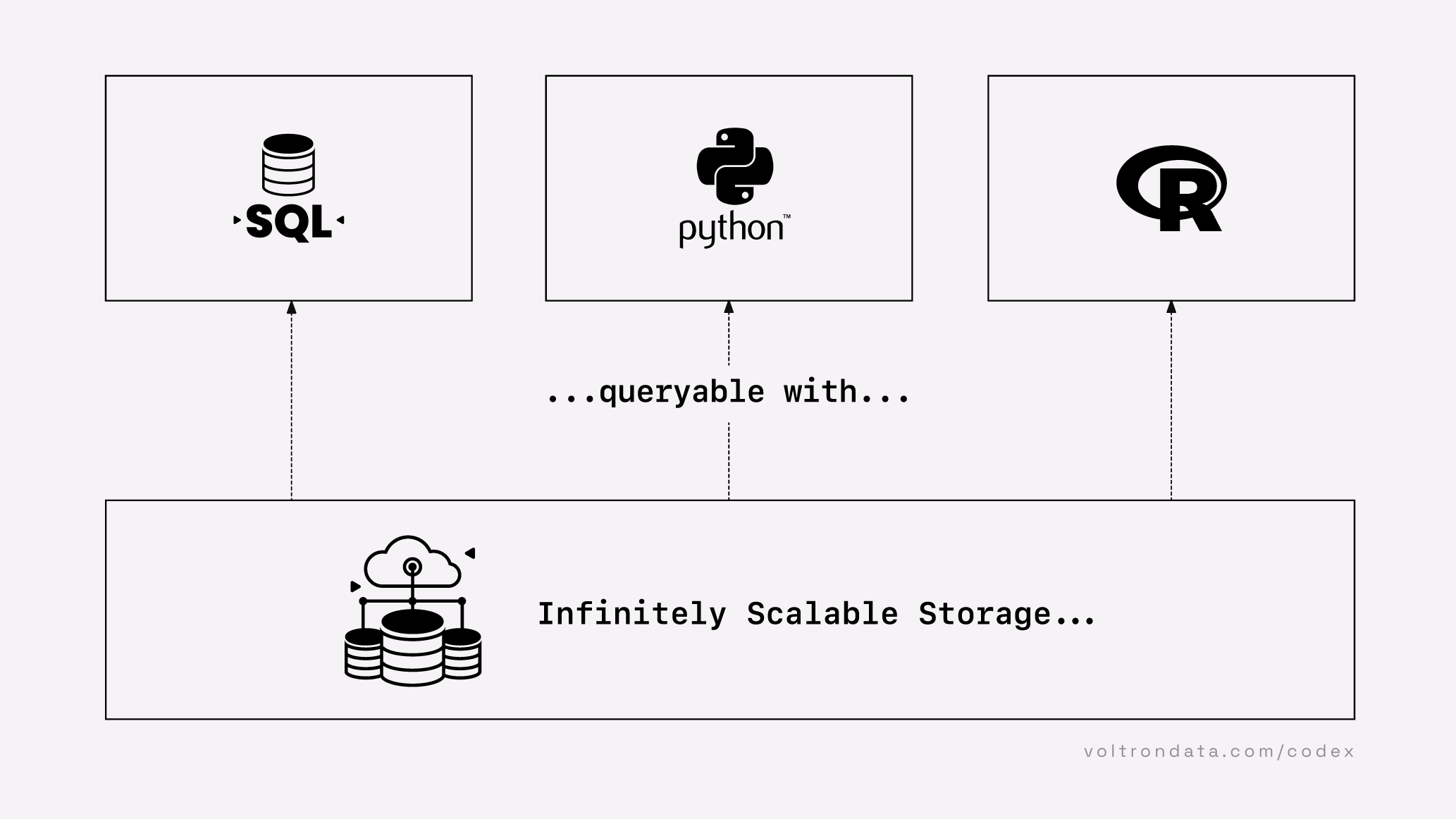
The dream is that the system just works seamlessly: there is infinitely scalable storage, execution is fast, and data can be queried without caveats about which programming languages or APIs are supported. As Benn Stancil put it: "bigger, faster, and polyglot."
Figure 00.01. The dream: a data system that just works. Source: Benn Stancil
In "search of database nirvana", the BYODB movement was born. Companies that could afford it started building all or a significant portion of the software components from scratch - engineering entirely bespoke data systems to serve their niche needs.
Although we cannot know the exact numbers, a fair estimate is that each of these companies has invested upwards of $100 million dollars a year to this cause. And for most companies, building data systems is not their core business. From companies that have raised money to build databases as their core business, we know that it is both hard and expensive to build a new database.
Table 00.01. Money raised to build databases as products. Data from Crunchbase (September 2023)
0.1 Starting from zero
So, why are companies like Netflix building their own data systems in-house? As a group of engineers at Meta, Voltron Data, Databricks, and Sundeck note:
hundreds of database system offerings were developed in the last few decades and are today available in the industry…
The fundamental reason most companies chose to go the BYODB path-even with hundreds of choices and even though the investment was so expensive-is that they thought there was nothing in the market to serve their niche. And at the time, they were right.
The decision to spend millions of dollars and years of development on a moonshot data infrastructure project cannot be easy for any company. What would push a company over the edge to choose to build their own data system? It is likely a combination of two trends happening in the universe:
Micro trends("small world" scale trends that pushed them away from their current system), and
Macro trends("big world" industry-scale trends that pulled them towards making a change).
0.1.1 Micro trends
There are three common micro trends at play, all of which are tough for any off-the-shelf data system to deliver:
Lock-in: Nobody likes feeling locked into their stack. Especially when they know that any change to the system means they will need to:
Migrate all the data into the new system,
Retrain all the data teams to use the new system, and
Rewrite all the existing data workloads in a new user interface.
Scale: Nobody likes running out of resources. Especially when they have to rewrite queries to scale a workload.
Performance: Nobody likes a slow system. Speed matters. Compute time matters. Data transport time matters.
0.1.2 Macro trends
So the micro trends made teams feel like they were stuck with their data systems. Meanwhile, these same teams were looking ahead, and could see the emergence of two macro trends on the horizon:
The AI Arms Race: Even before the rise of LLMs, there was a real need for "faster, more scalable, more cost-effective machine learning." In the early days of the BYODB movement, many companies may not have been able to pinpoint exactly how or why they would need to use AI or ML. But, for sure, no one wanted to be caught flat-footed in the "AI Arms Race." The FOMO (fear of missing out) was real.
The rise of GPUs and other accelerated hardware: Hardware has changed both in predictable and unpredictable ways since the start of the BYODB movement. What was once a field where CPUs reigned is now "a wild west of hardware", where chips like GPUs, FPGAs, ASICs, TPUs, and other specialized hardware have been rapidly evolving. But, as noted at JupyterCon in 2018, "the tools we use have not scaled so gracefully to take advantage of modern hardware." Developers leading the BYODB movement realized that while software was a gatekeeper to accelerated hardware, this was just temporary. In the future, software would provide a gateway to accelerated hardware, but only for those whose systems were positioned to win the hardware lottery. Just as with AI, no one wanted to hear the question "GPUs are here - are we ready?" and answer "no." The FUD (fear, uncertainty, and doubt) was real.
Figure 00.02. Trends in hardware.
Storage + networking becoming much faster
Hardware accelerators delivering better compute
Single-core CPU performance topping out
For all these reasons and probably more, we now have a nice little cohort of companies who have been building their own data systems and lived to tell us about it.
0.2 Building a new composable frontier
What does this new frontier of data systems look like? It actually looks a lot like your traditional data system.
While modern specialized data systems may seem distinct at first, at the core, they are all composed of a similar set of logical components.
A minimal viable data system can be broken down into three main layers:
Figure 00.03. The three main layers in a data system.
There is a lot of room for innovation within and between these layers. Each layer is an onion with its own layers. As just one example, optimizers often exist as a layer within execution engines. In a bespoke data system, one or more of these layers will be developed as custom software. But that does not mean that the whole layer needs to be engineered from scratch. One thing the BYODB movement made painfully clear is that building most of these layers from the ground up is not the optimal use of everyone's time and money.
Many talented engineers are developing the same thing over and over again, building systems that are essentially minor incremental improvements over the status quo.
We have companies that have a lot of money writing the same database system software over and over.
Luckily, once they started building their own data systems, teams inside those pioneering companies started realizing the power of two complementary forces:
Open source gives you more choices
Standards help you make better choices
Understanding how to balance these two forces has laid the groundwork for a paradigm shift in how we think about modern data system design.
0.2.1 Open source gives you more choices
Early on in the BYODB movement, teams realized that you do not have to work on the entirety of the problem. Instead, you can work on slivers of the problem.
This realization enabled a number of open source projects to crop up and start gaining traction. Many of these open source projects took the Unix philosophy to heart: make each project do one thing well.
Open source means each problem only has to be solved once.
You are starting to see various projects, in the open source community or organizations, to break out portions of a modern OLAP system into standalone components that are open source that other people can build on, other people can take advantage of, and other people could reuse for their own new OLAP systems. The idea here is that instead of everyone building the same thing, let's everyone work together on one thing, and have that be really really good and everyone gets to reap the rewards.
One example of this kind of open source project is Apache Calcite, a query parser and optimizer that can be embedded in an execution engine. Their website headline says it best: "The foundation for your next high-performance database." This means a team could lean on Calcite instead of having to build their own query optimizer from scratch, one of the hardest pieces of a data system to implement well.
There is probably no single person in the world who fully understands all subtleties of the complex interplay of rewrite rules, approximate cost models, and search-space traversal heuristics that underlie the optimization of complex queries.
Open source projects like Calcite started cropping up and gaining momentum as everyone in the trenches of the BYODB movement came to the same realization around the same time. Here are just some examples:
For data systems developers, open source was a lightbulb moment. First, it meant that engineering teams were not spread so thin trying to innovate across the entire surface area of the data system. Instead, they could focus on innovating in targeted, high-impact areas. Second, it expanded their choices. For example, when building an engine, they could leverage Calcite or Orca as the query optimizer.
If you have an apple and I have an apple and we exchange apples then you and I will still each have one apple. But if you have an idea and I have an idea and we exchange these ideas, then each of us will have two ideas.
George Bernard Shaw
The downside of having more choices is that ultimately you do have to make choices. An evergreen problem with open source is: how do you choose? How do you choose which user interface, query optimizer, or database connector to build with and depend on? That is where standards come in.
0.2.2 Standards help you make better choices
Open source and standards go together like milk and cookies. You may not realize it, but standards keep all of us sane every day. These are just a few classic examples that you might not even realize are standards:
ISO 8601 - (International Organization for Standardization for date and formats)
HTTP - (Hypertext Transfer Protocol for web browsing)
SMTP - (Simple Mail Transfer Protocol for email transmission)
RSS - (Really Simple Syndication for syndicated content)
Standards are documented, reusable agreements that solve a specific set of problems or meet clearly defined needs.
Standards are used when it's important to be consistent, be able to repeat processes, make comparisons, or reach a shared understanding.
In technical domains, standards ease interoperability struggles. As the IEEE (Institute of Electrical and Electronics Engineers) defines it, interoperability is the "ability of a system or a product to work with other systems or products without special effort on the part of the customer. Interoperability is made possible by the implementation of standards."
Technical standards are awesome. Standards help teams save time and money by giving them a common language for how their products can interact with other products.
In data systems, interoperability is an umbrella of problems that all boil down to how information moves through the different layers:
Data interoperability This requires common data structures to represent datasets in-memory while they are being processed.
Query interoperability This requires a common format for representing query plans that are portable across engines, and not dependent on a specific storage engine, database, o SQL dialect.
It turns out that developing and maintaining data systems without standards is very difficult. While it is true that developing with standards means that you have less choices, you have to hitch your design decisions to something. Otherwise, you are writing the glue code yourself, which means every change you make in the future will be expensive.
Data interoperability will always be a pain absent fast, efficient standards.
The alternative is to let standards limit choices now, with the knowledge that every change in the future will require minimal engineering effort and be less expensive because of it.
For these reasons, standards are the secret sauce for many developers who build data systems because most problems they need to solve are (a) common to the majority of data systems and (b) have an already agreed upon "best solution."
0.3 Composing the next frontier
Where are we now? Should anyone BYODB today? Probably not.
It is too expensive / time-consuming to build a DBMS from scratch.
But what about the companies who have already taken the BYODB plunge - would they do it all over again, knowing what they know now? Also probably not.
While many of the early BYODB pioneers continue to reap the benefits of their bespoke data systems, they are also now keenly aware of the downsides. Here are just some of the challenges that teams at these companies now face:
Maintenance is forever Now, each company owns the infrastructure that, in the best-case scenario, many internal business units depend on. Those who have built bespoke solutions from the ground up have made their systems that much more expensive as a result.
Performance is unpredictable Optimizing system performance can feel like a game of whack-a-mole. The second you push forward on one performance area, another one becomes the bottleneck.
Change is constant Every architecture decision has an expiration date. A healthy data system has an evolutionary architecture that supports constant change across every layer: user interfaces, engines, and data storage.
In search of data system nirvana, teams building their own data systems are closer, but not there yet. They are realizing that maybe the real data system nirvana was the open source projects and standards they met along the way.
0.3.1 What is a composable system?
Many lead developers at companies that have built their own systems are now advocating for a paradigm shift in data system design. The paradigm shift would benefit not just the companies that can afford to build their own systems, but also any organization that wants to modernize any existing data system. The shift is to move away from building systems by coding first and to instead start building by composing first.
Composability is a pretty powerful concept.
Because composability allows anyone in a network to take existing programs and adapt or build on top of them, it unlocks completely new use cases that don't exist in our world. In other words: composability is innovation.
A composable data system is one that is designed by reusing available components. But one does not simply build a data system from components that are just sitting around. Taking the lessons learned from the BYODB movement, a healthy composable data system balances the complementary forces of:
Open source components to support innovation
Standards for data interoperability
Considering the recent popularity of open source projects aimed at standardizing different aspects of the data stack, we advocate for a paradigm shift in how data management systems are designed.
We believe that by decomposing these into a modular stack of reusable components, development can be streamlined while creating a more consistent experience for users.
A composable data system has the same three core layers as a traditional data system:
A user interface
An execution engine
Data storage
You can think of these layers as the "do-ers" of a system. These are the tools we know and love, the logos you recognize, and the documentation that people spend hours reviewing.
But in a composable system, the "gluers" are just as or even more important. The gluers are the core standards that glue the layers together:
Figure 00.05. A composable data system, composed of layers plus standards.
This glue is not new. These glue pieces have to exist in some capacity in every data system, but the difference is that, without standards, they all work slightly differently. And those small differences add up to big troubles at the systems level. Composable data systems are not just possible but also practical today due to the emergence of open standards in this space. Standards serve as the strips of glue that are needed to bridge the gaps between the user interface, execution engine, and data storage layers in a way that is:
Documented
Consistent
Reusable
In later chapters in this Codex, we will cover each of these standards in depth.
Up until now, composable data systems were only accessible to a handful of elite organizations. Few experts are capable of designing and implementing composable systems, and much of the software created has been squirreled away inside closed-source commercial products.
We foresee that composability is soon to cause another major disruption to how data management systems are designed.
What is new now is that mere mortals can build composable data systems. Because of the BYODB movement, we now have the pieces in place for everybody else to compose with:
A reliable ecosystem of open source projects that paves the way for everyone else to "stand on the shoulders of giants."
Standards to ensure interoperability between those open source components.
Because of the BYODB movement, people can now spin up better, faster, more powerful data systems that would have taken years to build in the past. Because of the BYODB movement, composable systems are now what scientist Stuart Kauffman coined "the adjacent possible."
Innovative environments are better at helping their inhabitants explore the adjacent possible, because they expose a wide and diverse sample of spare parts, and they encourage novel ways of recombining those parts.
Over the course of the next four chapters, our goal is to share what it takes to design, build, and maintain composable data systems. Along the way, we highlight existing open source projects and standards that we build with and trust.
Switching to a composable system framework is a process. In our experience, you cannot completely move to a composable data system easily or quickly. What you can do is minimize the friction involved in switching by:
Arming yourself with knowledge about every layer of the system. This involves doing a bunch of research for each and every component, and asking the important interoperability questions.
Discouraging developing in the dark. Teams need to be very cautious about letting engineers in a vacuum just implement the version of each component aspect the best they could at the time. A lot of the time, this development work is filling in interoperability gaps that standards could bridge better.
Designing for deviance in the system. You will have to work to retain enough extensibility to avoid lock-in or any single point of failure for a given layer in the system. Anytime you have only one component in a layer, you risk lock-in.
A composable approach to data system design aims to make composing the least annoying part of the process. We wrote The Composable Codex to help teams minimize the friction of moving to a composable data system design.
Start where you are, use what you have, do what you can.
You can keep up with all things Voltron Data by following us on LinkedIn and X (formerly Twitter). If you want to receive alerts for future content like The Composable Codex, sign up for our email list (we won't send you product promotions).
The Codex is written for data systems designers, developers, and decision-makers who are composable-curious. Based on our experience working at and with different organizations, we assume the following:
No one wants to build from scratch: while the BYODB movement leaves a legacy, most organizations do not want to build their own data system, or build any part of their data system from scratch.
No system is a blank slate: most organizations start with one or all layers of a data system already in place. So the question becomes: how do we start augmenting what we have and build towards composable as a future state?
No one has unlimited resources: most organizations are resource-constrained, and need to carefully manage time, budgets, people, and expectations.
0.4.3 Who wrote The Composable Codex?
The Codex is written by engineers, data scientists, and leaders at Voltron Data. You can find out more about what we do at Voltron Data here: https://voltrondata.com/how-it-works





{kind=link}
{kind=link}
{kind=link}
{kind=link}