There is a lot of time wasted fighting about programming languages. Everyone wants a unified user interface, but everyone also wants it in their language, their way. So how can we bridge the divide between programming languages?
Instead of juggling query languages, SQL dialects, and a network of connections between user interfaces and engines, composable data systems offer standards to bridge the divides between programming languages.
What does language interoperability mean in this landscape? Keep reading below.
CHAPTER 02
Read Time
15 minutes
Topics
User Interface
Intermediate Representation (IR)
Tags
Data Access
Language Interoperability
Tools
Ibis
arrow R package
SQL
Substrait
“How can you govern a country which has 246 varieties of cheese?”
Charles de Gaulle.
President of France, 1959-1969
Contents of Chapter 02
2.0 Bridging programming-language divides
Everyone is weary of fighting over programming languages. Who among us hasn't hopped online and seen clickbait-y headlines disguised as healthy debates like:
"Is [ insert programming language ] dead?"
"Why does anyone use [ insert programming language ]?"
"Which programming language is better: [ x ] or [ y ]?"
Good times.
But the "which language wore it best" debates are not confined to social media. They also play out in enterprises over and over again. For modern data teams, fighting over languages feels like it comes with the territory.
In these battle royales, teams of people rally around their language of choice. Depending on whether or not a new tool supports your team's language of choice is a big reason for whether or not you adamantly support the adoption of a new tool, or become a zealot fighting tooth and nail to block a new tool from making its way into the system.
Generally, there are a lot of people who talk about R versus Python like it's a war that either R or Python is going to win. I think that is not helpful because it is not actually a battle. These things exist independently and are both awesome in different ways.
When solving real-world problems, I rely on Python's integration with other languages, like R or Julia. Each language provides helpful strengths. I view Python's flexibility to combine with these languages as a win-win.
For data people like Data Engineers, Data Analysts, Data Scientists, and Analytics Engineers, their programming language of choice is a very conscious decision for very good reasons:
It helps them do what they need to do. Many people are fluent in more than one programming language, but have preferences (some context-dependent), when given the choice.
It gives them access to tools that "fit their hand" (h/t JD Long). Increasingly, dataframe APIs meet that need because they provide the right verbs for expressing operations with tabular data structured as rows and columns. In short, they encourage "thinking while coding."
Figure 02.01. A UI helps users think about what they want to do with data, describe the operations (precisely), so that they can pass the description for the engine to do it. Source: Hadley Wickham
But the choice of a user interface (UI), whether it is an open source programming language or a specialized dataframe API, usually involves more than pure functionality.
Typically when you ask a programmer to explain to a lay person what a programming language is, they will say that it is how you tell a computer what to do. But if that was all, why would they be so passionate about programming languages when they talk among themselves?
In reality, programming languages are how programmers express and communicate ideas - and the audience for those ideas is other programmers, not computers. The reason: the computer can take care of itself, but programmers are always working with other programmers, and poorly communicated ideas can cause expensive flops.
So programming languages are a bridge between programmers. But they are also a bridge for each programmer to a broader community, with many considering themselves community taught (h/t to Caitlin Hudon.)
Python is a community that happens to have a programming language attached to it.
Using a language or other UI that you like, and that gives you a strong sense of identity within a community, can feel pretty magical. For teams, whichever type of UI they prefer, the upside of using the same one is that they can stay in their swimlanes. Using the same UI helps teams swim faster and go further by limiting context switching between tools and systems.
The crux of the problem is when every team chooses different UIs - different teams rely on different tools and infrastructure to access different data to run different workloads. Swimlanes turn into silos, and people start duplicating a lot of work just to keep each team's silo humming. This means that language choices can cause big rifts, particularly between the "data people" who use the system and the "system people" who design and maintain it.
The data science team…makes ridiculous requests of the data engineering team, like they want to do everything in, I don't know, probably Python, using GPUs and all kinds of crazy s*** like that.
And the data scientists go off and they build their own de facto sketchy…data engineering infrastructure so that they can do things the way they want to do them.
Josh Wills, Director of Data Engineering at Slack in 2016
The collateral damage builds across an organization over time: expensive tooling, employee churn, slow system performance, lost productivity, underwhelming results, stacks of denied requests between teams, and systems that feel both fragile and rigid.
So, how can a data system bridge the divides between disparate programming languages, communities of fervent fans, and teams who need their own lanes to swim in? We think the answer is a composable data system that changes the way we look at the user experience. Because the UI is the first and often only touchpoint for the people using a data system, it is the perfect place to find common ground.
Figure 02.03. The UI is the first and often only touchpoint for people using a data system.
2.1 The complexity of finding common ground
All this feuding might make you think that data people are really picky and prickly about their programming languages. You might also think that this all sounds like much ado about nothing. While standards and software can help, the debates can teach us something important about data systems: real people need to use them.
Fighting over programming languages is a symptom of frustrated human beings. While everyone does have their favorite things, most data people are practical: they want to write code to do something useful like analyze data, build and deploy models, make predictions, visualize trends, or run a report.
It is not satisfying to spend hours "putting together jigsaw puzzles with hammers, scissors, and tape, instead of having finely-crafted pieces that are designed to fit together" (rachelbythebay.com).
We spend the majority of our days trying to configure OpenSprocket 2.3.1 to work with NeoGidgetPro5, both of which were developed by two different third-party vendors and available only as proprietary services in FoogleServiceCloud.
It is no wonder that tensions mount when the talk turns to taking away people's favorite tools. On the road from "think it" to "do it," a lot of daily data drudgery happens at the "describe it" stop. The first step in finding common ground is to acknowledge what parts of the system have let us down:
While data people do indeed have lots of UI choices, most choices fall into one of three categories:
SQL (Structured Query Language)
A general purpose programming language
A dataframe API
But this list is misleadingly simple because it hides a lot of complexity and papercuts that data people absorb daily. In fact, even the picture we painted at the top of this chapter is misleading, because it reinforces the idea that a single tool is sufficient for modern data work.
Few data people are able to live a life of monolingual luxury. You often hear "We are a Python shop," or "We are an R shop," but increasingly it is "We are a polyglot shop" (i.e., proficient in more than one language). Or more honestly: we use the tools we need for the task and data at hand.
Figure 02.04. Same work, different tools.
Unfortunately, to do anything useful with data, any single UI choice will not suffice - there is no magic wand. Most tasks require more than one, and every choice has a tradeoff:
API designed for analytics with tabular data that has rows and columns
So many different APIs
Features have not kept up with the needs of analytics workloads
Sparse engine coverage
The point of this table is not to point out how all the tools are flawed. The point is that any changes to the system should start by asking "How might we design our data system to support people to do good work using imperfect tools?"
2.1.2 Language silos & illusions of choice
Because there is no magic UI wand, it is nice to give people choices. But people are often flummoxed by the illusion of choice when it comes to UIs. Sometimes the choice is between two half-baked options. Or maybe one option looks good on paper, but has a fatal design flaw or missing feature that is a dealbreaker. The choice is usually not "Which magical UI do I get to use today?" but rather "What UI do I need to use for reasons beyond my control?" Every choice requires unlearning and relearning things you already know how to do in other systems.
What's worse than data silos? Data silos that invent their own query language.
To be fair, some of these are SQL flavors, or at least pretend to be, but all with their own quirks that forces me to unlearn everything I knew about SQL to the point that it might as well be something completely different.
Figure 02.05. Where standards fall into a composable data system
Working in a data silo means a user cannot reasonably query data in vendor X with a job running in vendor Y. Even if it is somehow possible, they will still pay many penalties (not to mention higher bills) along the way for trying to bridge across silos.
We do not know why we are here. We do not know who built the Silo. We do not know why everything outside the Silo is as it is. We do not know… when it will be safe to go outside.
As if fighting uphill battles against tools and silos is not hard enough, next comes the challenge of having to paste all these disparate pieces together into a working data pipeline. Building data pipelines without standards turns out to be hard. So the pipelines become trapdoors in the system: easy to fall into but hard to climb back out of. Crawling back out often requires more people, more code, more effort, and more tears.
Figure 02.06. The endless implementation loop: May the odds be ever in your favor
...in today's world, you almost need a data engineer for every consumer of data in [your] organization. So for every data scientist or business analyst, you really need a full time data engineer.
We affectionately call this the "endless implementation loop." It is what happens when domain expertise and implementation expertise diverge. It goes something like this:
The data science team writes a specialized workload and hands it off to the data engineering team...
The data engineering team builds and passes it back to the data science team to review it...
The data science team flags any number of errors, fixes those but creates new ones, then hands it back to the data engineering team...
The endless loop begins!
In our experience, optimistically, about 20% of these kinds of projects claw their way back out from the trapdoor and make it into production. It is not for the faint of heart.
Trapdoor data pipelines happen for a few reasons:
Prod is special: Code that works in local/development is not the same as code that works in production
Data is bigger than memory: Code that works with small data does not work the same with "big data"
Scaling is hard: Code that works on a single node does not work the same on a distributed environment
No one wants to enter the endless loop of implementation, but this is a natural consequence of the way our systems are designed. For example, here's a cautionary tale from data scientists at Microsoft:
Data scientists implemented a data cleaning module using pandas. They tested locally using a sample dataset, but later they had to scale it to a large dataset on Cosmos. They ended up rewriting their module using SCOPE, the query engine on Cosmos. The data scientists could have tried alternate engines like Dask to scale their programs, however, operationalizing new engines in a cloud environment is non-trivial and something which data scientists are not expert at.
Jindal et al 2021, Magpie: Python at Speed and Scale using Cloud Backends
Trapdoor data pipelines create a lot of system debris:
Duplicated code because of the need to rewrite pipelines for different systems
Stale data because it is hard to keep current data flowing into the pipeline
Multiple (sometimes large) copies of data spread out across different systems because this is sometimes the easiest way to exchange data between systems that do not interoperate
2.2 Standards for language interoperability
We can all agree on one thing: we are not yet to the point where users feel like data systems were built for the people that need to use them. But faced with this uneven playing field, many organizations try to level the field by embarking on grand unification initiatives. These typically focus on either trying to:
Get everyone in the organization (yes, everyone) to unify around a single UI
Get everyone in the organization (again, everyone) to unify around a single SQL dialect
People look for ways to make complex problems easy rather than make it easy to work on complex problems...
Asking how we can support our teams who NEED the time and space to work through that, it's often a much more tractable lever than trying to change the inherent nature of the work.
These are lofty initiatives, but they share the same fundamental design flaw: they both ask the system's users to make the inputs simpler for the system to handle, rather than tasking the system with making it simpler for users. There is a third way.
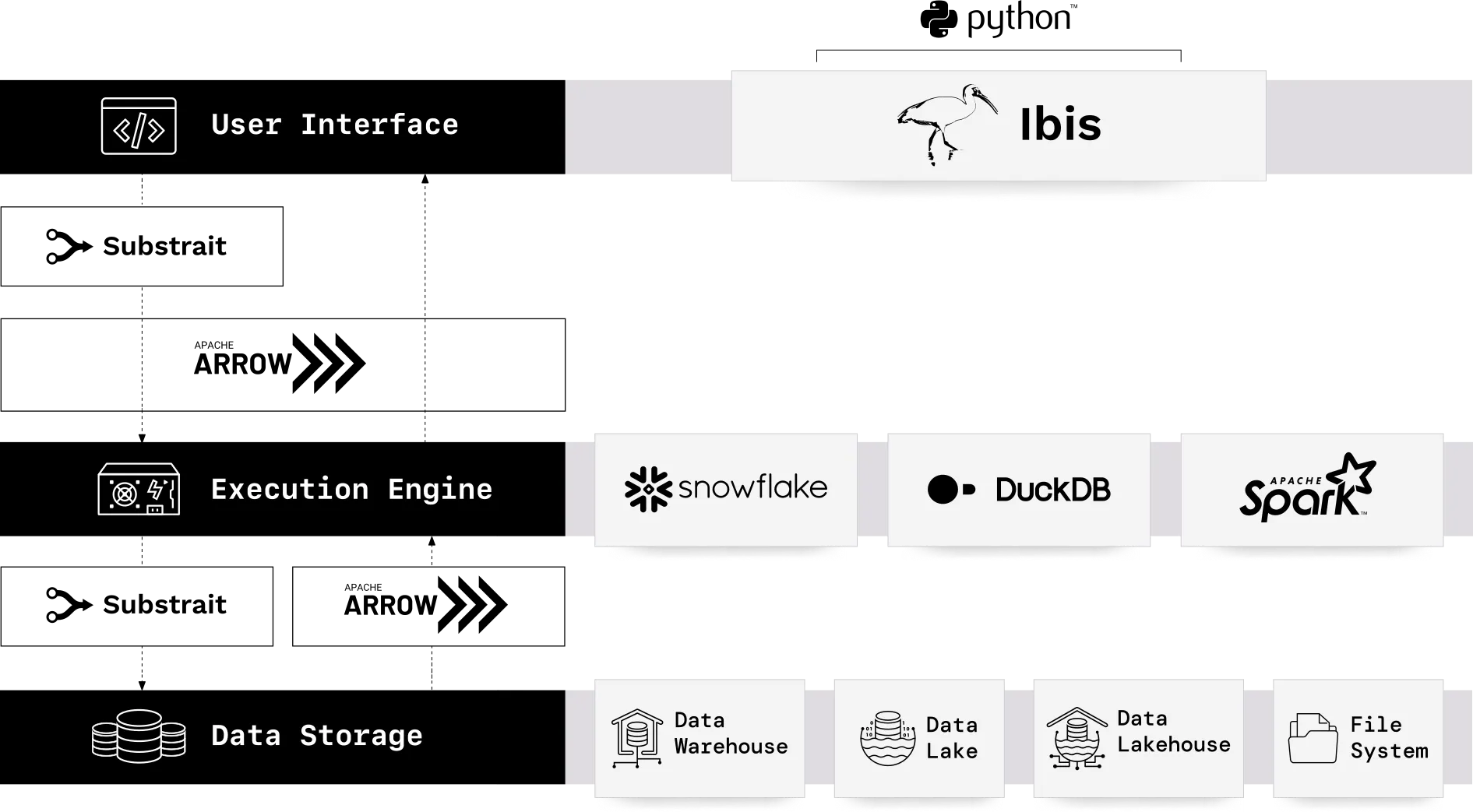
The third way sidesteps programming language preferences, UI favorites, and SQL dialect restrictions altogether by adding a new intermediate language - one that is a special "machines only" language (meaning users do not learn it, use it, or touch it) sandwiched between the UI layer and the execution engine layer.
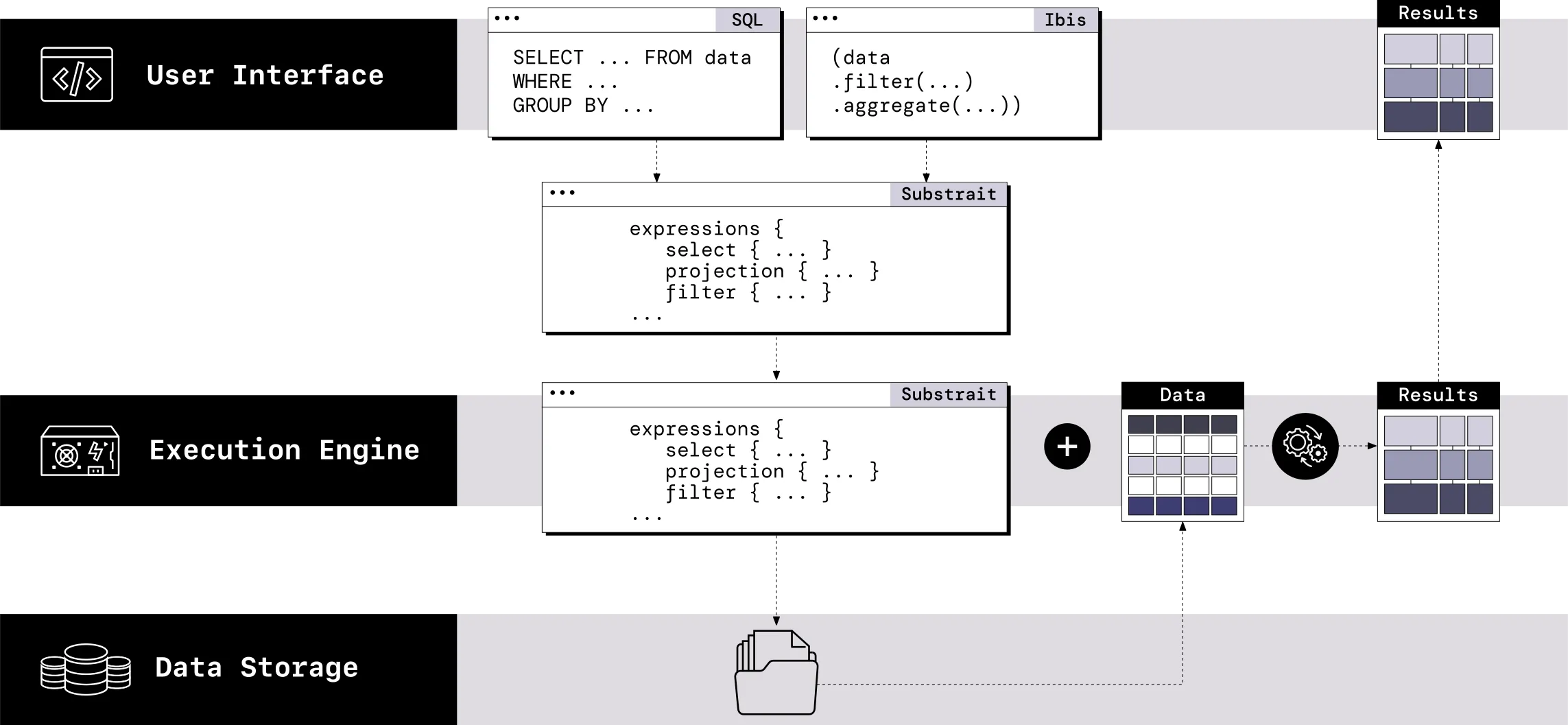
The intermediate language is a standard that acts as a translator between the UIs and the engines. This kind of standard is called an intermediate representation, or IR. To make it a true language, one layer of the system needs to speak or produce it, and another layer needs to hear or receive it. Here is how that works in a composable data system:
A UI turns a user's query into IR.
An execution engine turns this IR into the specific kind of code that it can execute.
In this way, the third way obviates the need to pick language winners (and losers), and opens up the possibility of doing data engineering differently.
This is a brave new world…a different way of doing data engineering.
A way of doing data engineering where analysts can define pipelines, and make modifications to them...
A world in which everyone can interactively load data up into memory, try out scripts, try out new ideas, play with the results, see if they are a fit, and if they are, quickly move them into production pipelines.
And a world where data engineers…are allowed to work on maybe one of the most truly interesting resource management data engineering problems of our time, which is basically taking this arbitrary DAG of queries and jobs…and finding a way to optimize it and finding a way to process it all very very efficiently.
The third way uses standards to build a bridge to this brave new world.
2.2.1 Intermediate representation
While IR is a relatively recent idea in data analytics, it has been around for a while in other software engineering domains like compilers and machine learning.
For example, LLVM and more recently the MLIR project defined a common IR to unify the infrastructure to run machine learning models across frameworks like TensorFlow and PyTorch.
LLVM includes an 'intermediate representation' (IR), a special language designed for machines to read and write (instead of for people), which has enabled a huge community of software to work together to provide better programming language functionality across a wider range of hardware.
The rationale for an IR in those domains was pretty similar to the situation in the data analytics space now:
Developing any new front-end framework meant writing loads of glue code to target every back-end framework
Developing any new back-end framework meant writing loads of glue code to target every front-end framework
Developing any holistic system meant writing loads of glue code to add or swap any front-end or back-end frameworks
Instead of targeting new compilers and libraries for every new hardware type and device, what if we create a middle man to bridge frameworks and platforms? Framework developers will no longer have to support every type of hardware, only need to translate their framework code into this middle man. Hardware vendors can then support one intermediate framework instead of supporting many?
In a data system, any components that produce and consume the same IR are interoperable. This means they can readily exchange information about what the user wants to actually do with the data, without writing bespoke connector code by the user or the engine developers.
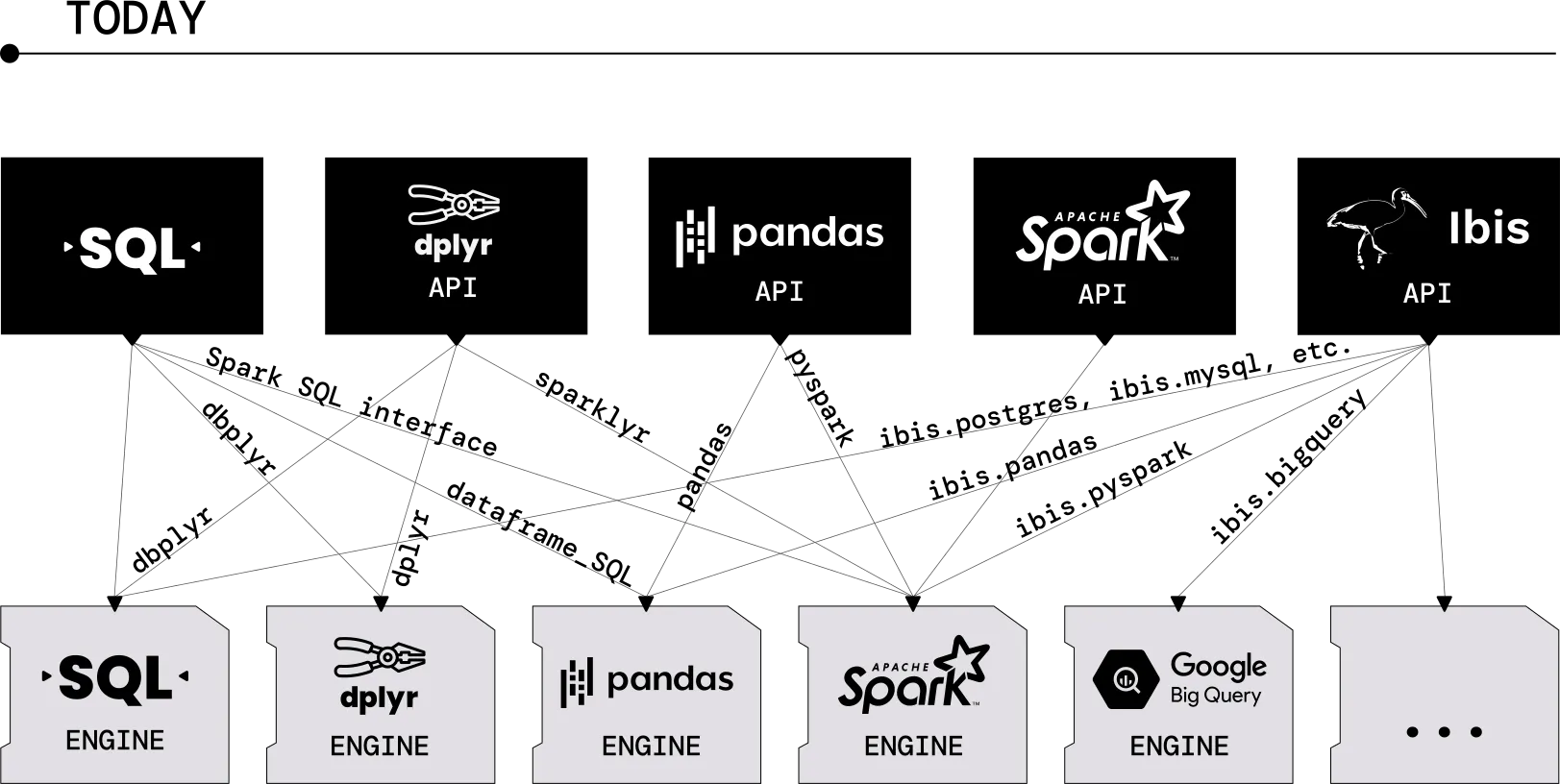
Figure 02.08. Today, without an IR, every UI has to use custom connectors to talk to every engine. In the future, everybody can just talk to the IR.
You'll find yourself duplicating a lot of things… It's very hard to DRY (don't repeat yourself) up your code.
If you do the IR, then you end up having all those syntactical constructs take the same path, which is easier to maintain…
Finally, if you want to do any kind of optimization…I think that is what they have programmers doing in hell: trying to do optimization on an AST (abstract syntax tree) rather than on an intermediate representation.
But, what happens with IR? We improve the quality of life for different developers in a composable data system: those who develop UIs, those who develop execution engines, and those who design and develop data systems.
Figure 02.09. IR for Different Developers
Again, IR is not code that anyone should write. Ideally, data people never have to touch IR. IR is a specific kind of code that is passed from one machine to another. But this is exactly why IR is the bridge between the language divide: if languages can communicate to a translator (the IR), the translator talks to all engines, then all languages are on a level playing field within the data system.
2.2.3 Composing data systems with Substrait
Substrait is an open IR standard for UIs and engines to represent analytical plans. Substrait is a cross-language specification for data compute operations, also known as an IR for relational algebra. Substrait plans are focused on defining and standardizing data manipulation operations.
To me, this is the right way to go, this is the clear direction, this is sort of what's coming next. In the same way as Parquet and ORC, you would have a system that supports Substrait and it would allow you to integrate into a big data ecosystem in a way that existing systems don't do right now... You'll see a lot more of this in the future.
Instead of managing a network of connections between interfaces and engines, a composable data system need only specify that:
UIs ultimately produce a Substrait plan
Engines can operate by accepting a Substrait plan
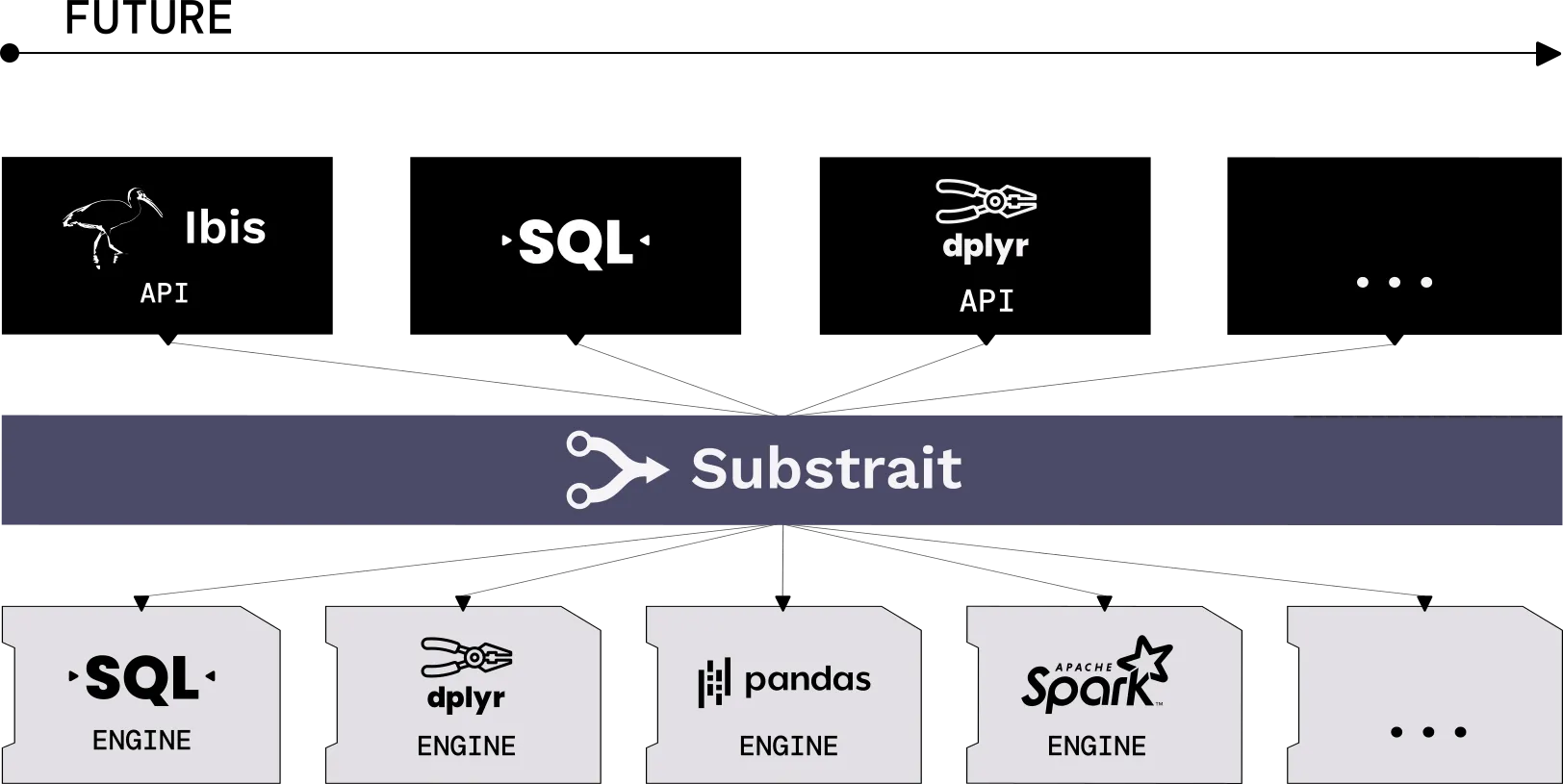
Figure 02.10. Substrait as a common IR standards layer that glues the UI and the engine.
It might seem counterintuitive to add yet another layer to your system. However, in reality, all systems already have an IR layer that acts as the glue between the UI and the engine. In the world of data systems, there are two flavors of IR:
A closed IR: In proprietary systems, the IR layer is internal. It can only be understood by the bundled engine. It is not documented or reusable by engine developers outside that system. Often, it only offers one UI choice for users.
An open IR standard like Substrait: This is more common in a composable data system. This would mean that:
Any UI could take a query and produce a Substrait plan
Any engine can compute by accepting a Substrait plan
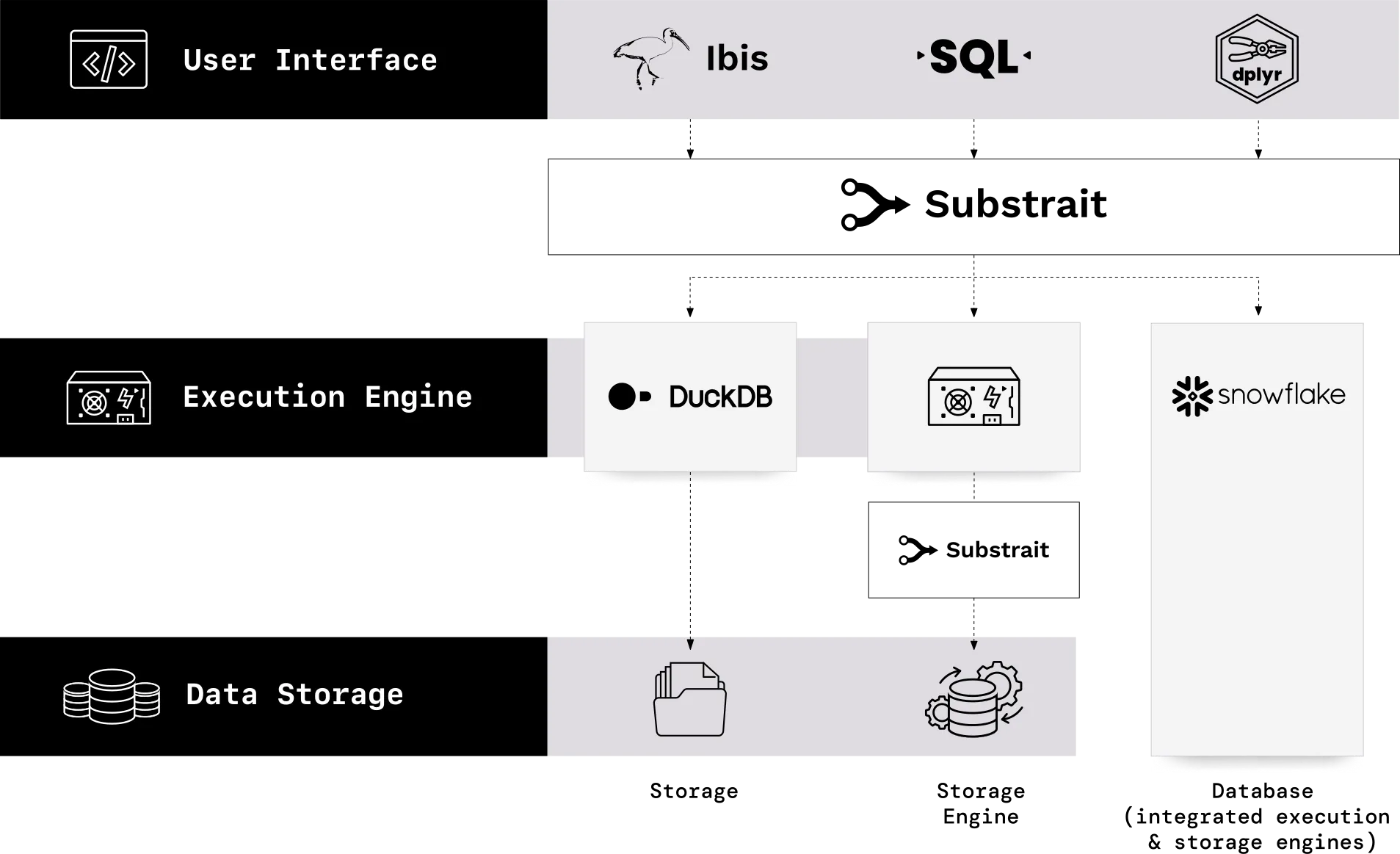
Figure 02.11. Code flows from the user through the UI, which then passes the IR plan to the engine for execution.
2.3 Composable user interfaces
While adopting an IR standard helps to bridge language divides for system developers, people will still need to actually use the data system. To do that, they will need functional UIs available in multiple programming languages.
Any UI needs to check a lot of boxes to actually win friends and influence people. Functionality, features, and usability are usually top of mind when choosing UIs, but in a composable system, users are able to make those choices themselves. For those designing the system, the UI is a critical component that can help climb the data system hierarchy of needs.
Not so much 'don't make me think' but 'don't make me think about the wrong things.'
UIs can be added, removed, or replaced without affecting the rest of the system.
Changing the UI (migrating to or away from it) has no or minimal impact on other components, and choosing a UI means you can only change the UI and not the engine or storage layers.
Interoperable
UIs can communicate with other components to exchange and make use of information, using well-defined interfaces.
Connecting the UI to other system components does not require additional development work.
Customizable
UIs can be combined with other components in unique patterns to satisfy specific needs.
Using the UI helps you compose and customize your data system.
Extensible
UIs can be easily modified to add new features or functionality.
Extending the UI makes it easier to build a tailored system that meets your needs.
We will use Ibis, a Python-based UI, as a case study in composable UIs to climb the data systems hierarchy of needs.
Figure 02.12. Ibis is a composable UI that can interoperate with multiple execution engines and data storage layers.
2.3.1 Modular
Figure 02.13. A modular UI is swappable: you can easily choose to use it or leave it.
Here's the world I want to live in:
· The value of choosing one tool over another doesn't affect the end result. Rather, it's a structure used to facilitate the describing of instructions, much like tabs and spaces.
· Moving between data transformation APIs is as easy as possible.
· New interfaces can spring up, gain adoption, evolve, and influence other [data transformation] APIs.
We want to live in this composable world, too. The first level in our data system hierarchy of needs is modularity. How does a UI snap into a modular system?
First, it should "do no harm": choosing one UI should not change the end result, should not require changes in other layers of the system like the engine or storage layers, and should not limit your future choices.
Second, it should be "plug and play": the hurdles to entry and exit should be minimal. A UI needs to support two system changes:
Adopting the UI
Migrating away from the UI
Here are some features of Ibis that enable modularity and pave the way for a composable world you will want to live in:
Benefit
Ibis feature
Minimize changes required in other layers
Separates data transformation code from the compute operations within the execution engine.
Avoids data duplication by connecting to and running in your execution engine.
Minimize switching costs
Keeps users in the Python programming language.
Data transformation API is consistent, so that what you already know from using other dataframe libraries like pandas can help you learn.
Generate SQL as an escape hatch.
Minimize gaps in functionality
Offers comparable feature coverage with similar libraries, allowing you to migrate an existing codebase.
2.3.2 Interoperable
Figure 02.14. A UI needs to interoperate on two levels:
Query plans: Produce a standard query plan to pass to a compatible engine
Data: Return results as a standard in-memory data format
Following our mouse up the hierarchy of needs, a UI needs to lean on standards for system interoperability. This means that users will not get saddled with extra development work like converting data formats or query code into what the other parts of the system need. A UI needs to support:
A standard plan to pass to the engine. A UI needs to pass the user's instructions to an engine. Without an IR, the way to do this is through a SQL query. Without a true SQL standard, the engine has to understand any number of SQL dialects. With a standard IR, the UI simply translates user input into an IR. Any engine that can consume the IR plan will be able to execute it.
A standard data format to return from the engine. Without standards, different engines will use different in-memory formats for processing, and this translation between engines can be costly. But, if for example, the engine operates on Arrow data, the UI should keep it in the Arrow format. This simplifies passing data from the engine to downstream tools, like a machine learning or visualization library. If the downstream tool accepts Arrow-formatted data, passing the data between processes is simpler and faster with a shared, standard in-memory data format.
Think about having a pipeline of data that's Arrow in, Arrow out all through the pipeline. If one day you want to remove a system and replace it with a new system - if that system also can generate Arrow - you don't have to change that ETL process between those two points.
Josh Patterson, CEO @ Voltron Data, on the Imply podcast
Benefit
Ibis feature
Produce standard query plans that are portable across standardized engines
Producing Substrait plans means that Ibis can interoperate with any engine that is a Substrait consumer. This feature has an asterisk - it is on the Ibis roadmap.
Use a standard data format to interoperate throughout your data pipeline
Returns Arrow-formatted data so results can interoperate with other components that can process Arrow data, without special work. For instance, results can be passed to scikitlearn, written to disk in Parquet, or transmitted to other processes with Arrow Flight.
Read and write from other dataframe libraries so that, for example, users can write pandas, switch to Polars (both engines and APIs), using the dataframe interchange protocol.
2.3.3 Customizable
Figure 02.15. A UI does not get in the way if a system needs to flex and adapt to changes, and can even make changes safer and smoother.
In Standards Over Silos, we said that developing with standards is a lot like using anchors while rock climbing: they help you chart a course to your final destination, and offer protection when changes need to happen in the future.
A UI can help you do just that with features that allow you to shop for and swap out other system components. Being able to switch system components easily means that you can test how your queries perform without rewrites, or switch engines without changing queries. This flexibility gives you better visibility into your holistic system: what is working, what you can change, what would break, and what options might best suit your needs.
Benefit
Ibis feature
Change system components without rewriting code or query logic
Changing the engine or storage is possible with a one-line change in the configuration code.
Prototype locally and deploy to production faster
Changing from local/development environment to distributed is possible with a one-line change in the configuration code.
Supports testing of queries in case of migration
Uses deferred evaluation and type checking to ensure that your queries fail early if they contain errors.
Supports connections to data across disparate sources
Connects to multiple sources at once to combine data in a single analysis.
2.3.4 Extensible
Figure 02.16. The UI can be easily modified to add new features or functionality.
An extensible UI enables downstream development work, but the good kind: the kind that is well-scoped, builds on top of standards, and keeps users in the flow of coding with an API that is consistent with the built-in library functions. In Chapter 01, we introduced piggybacked and greenfield extensions. A composable UI provides two important ways to extend its functionality, should you have specific needs and resources for extra development work:
Piggybacked extensions
When the UI library uses a license that allows developers to reuse the code, especially if the codebase is designed for extensibility, it opens the door for others to build support for specialized backends, or to add features that might be specific to a backend. Standards make the development of these extensions possible and keep the development of the library active.
As an example, several companies have piggybacked on Ibis:
User-defined functions (UDFs) are important because they allow users to go beyond the existing functions of the user interface to support niche workflows. Without UDFs, these niche workflows would need to run outside of the execution engine where the rest of the data analysis takes place, slowing down the materialization of the results.
Without UDFs, you'd need to do something like:
dump your data from Redshift into S3
download it into your server or your local machine
You've officially made it halfway through The Composable Codex. If you landed on the Bridging Divides chapter first, we encourage you to go back and read Chapter 00: A New Frontier and Chapter 01: Open Standards Over Silos. These chapters cover the foundation and fundamentals of composable data systems.
You can keep up with all things Voltron Data by following us on LinkedIn and X (formerly Twitter). If you want to receive alerts for future content like The Composable Codex, sign up for our email list (we won't send you product promotions).
The Codex is written by engineers, data scientists, and leaders at Voltron Data. You can find out more about what we do at Voltron Data here: https://voltrondata.com/how-it-works








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}