In today's interconnected world, the ability to seamlessly connect and exchange data between different systems is crucial. This chapter explores the challenges and solutions in achieving true data connectivity.
Data sprawl necessitates solutions that can reach across storage layers and databases. Instead of dealing with costly migrations, lengthy rewrites, and mazes of glue code, composable data systems rely on standards to make the data sprawl feel small.
“Listen: there's a hell of a good universe next door; let's go.”
E.E. Cummings
Contents of Chapter 03
3.0 From data sprawl to data connectivity
There is a certain ceremony that happens on data teams everywhere when new people come on board. It is reminiscent of the cook's tour of an old historic home.
Here is the dumbwaiter that made sense at a certain point in time - one person over there still uses it, but do not try this if Margot is on PTO…
Over there is a door to nowhere - they removed the legacy porch in the last renovation, so now you can technically use this door, but be careful because there is nothing behind it.
That is the main stairwell that we are all supposed to use 'for security reasons.' But shhhh...nobody uses that stairwell because some of the steps are broken. Back here are the secret real stairs our team uses…
This drawer is where we keep all the account keys! We aren't supposed to write them down, but this is quicker and easier than asking for new access permissions…
This ceremony is the passing of the data knowledge - where the data is stored, who has the right permissions to touch it, how to connect to it, what the data actually looks like, and why it is the way it is.
Most data teams carry this knowledge around in various places. If they are lucky, all the knowledge is documented somewhere steadfast. Unfortunately, even if docs exist, they often miss the practical asterisks like "works but only if this happens" or "works-ish depending on the moon phase."
Documentation is often a patch for a process that should be easier to use in the first place.
For that reason, many people just keep the knowledge in their head, or in their own personal data diary so that their current self can save their future self time and agony.
There is rarely a clear or easy answer to "How do I get this data that I need right now?" without an oral history filled with a lot of asterisks and apologies.
Figure 03.01. It depends: The Definitive Guide; a parodic book cover. Source: @ThePracticalDev. @ThePracticalDev
Many of our team members have lived in these homes, and some have even tried to renovate these kinds of homes. But usually the attitude is "if it is not broken, do not fix it." Most teams try to just get by because the foundation is in place, the wiring is good enough, and the plumbing works* (*-ish).
But what happens at scale in an enterprise setting is a different story: now there is a whole neighborhood of homes with (distributed) problems just like these. And these data systems are not just filled with asterisks but also anxiety about making changes to the fragile house of cards that connects the people with the data.
A file in the project's repository…deletes prod using our CI/CD pipelines if it is ever moved into the wrong folder. It comes complete with the key and password required for an admin account. It was produced by the former lead engineer, who has moved on to a new role before his sins catch up with him.
At a systems level, once you have more than one place where data is stored, the complexity and costs of your system can only go one direction: up (for now).
How do these costs rack up?
Many data copies: To get around the system sprawl, the same data gets copied many, many times – some in legit places and some in not-so-legit places. This leads to stale, out-of-date data copies at varying levels of legitness, and analyses that never reach the latest or most complete data (not to mention security and privacy risks).
Costly data copies: When talking about terabyte or petabyte-sized data that gets copied over and over again, the costs for storing the original data plus its offspring can get very expensive.
Costly complexity: More data sources means more maintenance which means more people, time, and resources:
More people are needed to do the same work because the systems are too complex.
More time is needed to get new work done because of the amount of tools and steps involved.
More resources are needed to fix things: to notice when things break, figure out what went wrong, and fix them.
There are human costs, as well. The data people - the people who need to use the system to access and analyze data - inherit much of the complexity of the system. Data sprawl has a way of bubbling up to the surface of any data system.
In fact, ideas expressed in a programming language also often reach the end users of the program - people who will never read or even know about the program, but who nevertheless are affected by it.
Data sprawl creates an onerous data environment to work in. This disproportionately affects the most advanced teams the most because they are performing the most advanced tasks on data, and they have the most to lose from a decrease in visibility and data access.
We are responsible for gluing together hundreds of tiny components and shipping networking logic to build a single app that is dependent on each cloud vendor's implementations of specific technologies. From a historical context, it makes sense. As an engineer who just wants to build and ship substantial products, it makes me miserable.
The costs of this complexity also rack up in the system as one-off solutions accumulate over time. In some instances, teams develop their way out of data connectivity problems. Unfortunately, this development work usually involves band-aid solutions like adding more glue-infra to the system. All gains are short-term, rather than long-term investments. But just as likely, teams can also get stuck in The Bad Data Place when trying to deal with data connectivity problems:
Shadow IT: When groups become so frustrated that they sign up for new data services and plan to ask for forgiveness rather than permission, just to get a data project unstuck.
Leapfrog development work: Teams are stuck or they are doing things they should not be doing, like data analysts creating new databases or data scientists building data engineering workloads.
How do you escape the sprawl? The short answer that many of our team members have learned the hard way is that you do not - you embrace the sprawl, and all the gnarly complexity that comes with it.
Embracing data sprawl means that you leave the data alone: you do not have to move your data, you do not have to get your whole organization to try yet another large-scale data migration to a new system, and you definitely do not have to pull off a "grand centralization" initiative to unify around a single data system that includes access to all of the most important data for the company.
So, how do you embrace sprawl yet still keep the trains all running on time so that data people can connect to the data they need when they need it? We think the answer is a composable data system built on top of three essential connectivity standards:
Data formats: Standard data formats can remove a lot of the asterisks around data connectivity in a system for end users and for the data systems people that support those users.
Data access: Connectivity standards can create a smoother and more consistent data access layer for people in all corners of the organization who use the data system, regardless of the underlying database(s) in use.
Data transport: Standard wire protocols, and a standard way to represent data on the wire, create a smoother and more predictable developer experience when designing data systems that can scale.
On their own or together, these connectivity standards make the sprawl feel smaller to end users, and provide pathways (if the spirit moves you) for eventually taking steps to tame data sprawl in a composable system.
3.1 The complexities of data connectivity
Why is it so hard to embrace data sprawl?
Because trying to manage multiple "client → wire protocol → database server" stacks running multiple data pipelines across multiple but interrelated data sources is like trying to understand a Rube Goldberg machine.
Complex systems are based off of multiple simple processes that interact, which means that it is very very hard to determine what is going to happen next.
All of data connectivity boils down to processes that are relatively simple in isolation. The complexity snowballs as more data sources are added to the system, and the processes and number of people who use them multiply. Many organizations have a high number of data platforms currently in use, often accumulated over years of incomplete system migrations. When it comes to sprawling data sources in such a system, it is difficult to know the difference between the essential and accidental complexities:
Essential complexity is the complexity inherent in the problem itself and the "state of the art" for how it needs to be solved. Essential complexity happens when you cannot simplify something without removing value.
Accidental complexity is everything else - complexity that would not exist in an ideal world (e.g. complexity arising from tools that do not interoperate as well as they could, tools that require what feels like unnecessarily convoluted configuration settings, etc.).
While data sprawl has a way of rising to the surface to complicate the end user experience, the really sneaky thing about data sprawl is that it also has a way of seeping way down deep into the bits and bytes of the data system. To embrace the complexity, we have to make sense of what is essential about it. To make sense of it, we have to head down to the basement of the data system and peek at the circuit breakers and the plumbing.
3.1.1 Defining data connectivity in systems
Data connectivity refers to the layer in a data system that allows people in an organization to productively interact with data stored in databases: to submit queries and get useful results back from a database.
Figure 03.03. A composable data system, with three key standards.
What does connectivity have to do with embracing data sprawl? Everything. Teams around the world are continually asked to move their data on the promise that the migration will remove every asterisk about data connectivity in their system. Want a faster, cheaper, simpler system? Want a better life? First, just move all your data from over there to over here.
Why does everyone try to start there to try to make things better? Part of the reason may be because, historically, transporting large data files has never been easy nor fast. Moving data from one system to another may be the highest level of system complexity at scale. Compared to the actual logistics of physically moving data files or literally shipping them (a very high bandwidth operation!), strengthening system connectivity with standards sounds like a better construction bid than "tear it all down and rebuild."
If you want to transfer a few hundred gigabytes of data, it's generally faster to FedEx a hard drive than to send the files over the internet.
Data sprawl will continue to exist but the fragile house of cards need not be so fragile. The tools connecting everything are like rebar in concrete: it will make a brittle material stronger. When designing data connectivity for any data system, there are three essential complexities:
Data formats – this is the format of the results that the data people receive in return. While what ultimately matters is the format of the end result, there are a lot of intermediate data formats that happen along the journey from storage to end user. This is because several layers in the connectivity stack have a say in the results format at various stages in the data transport process:
The database itself has a (usually proprietary) binary format for serving to clients
The database uses a wire protocol with its own "on the wire" format
The client API wants to deliver the results to the user in a specific format
Data access – connectors are how data people connect their query to the data that they want to run it on. It is how people submit queries to a database server, and how those queries are then sent over the wire to the database according to a database-specific wire protocol (also called a server API). Connectors might be proprietary (specific to a single database) or generic (usable across >1 database). A connector has two elements: an API and a driver.
⇢ Either way, data people end up accruing a collection of connectors, with a preferred one for almost every database occasion.
Data transport – most people do not dive this deep into the server-side of the system, but data engineers and systems developers wade into this layer often. The data transport layer is full of protocols that define how messages and data get sent over the wire, and tools that power and support those protocols.
⇢ When you go from one data system to another, one of the most difficult parts of switching is that they use different protocols, so adding one more thing is an expensive operation.
Data is the lynchpin in any data system: the data needs to flow where it needs to go when people need it, and the people who need it do not want to dwell on data connectivity at all – it needs to be as quick and painless as possible.
3.1.3 Database connectivity with asterisks
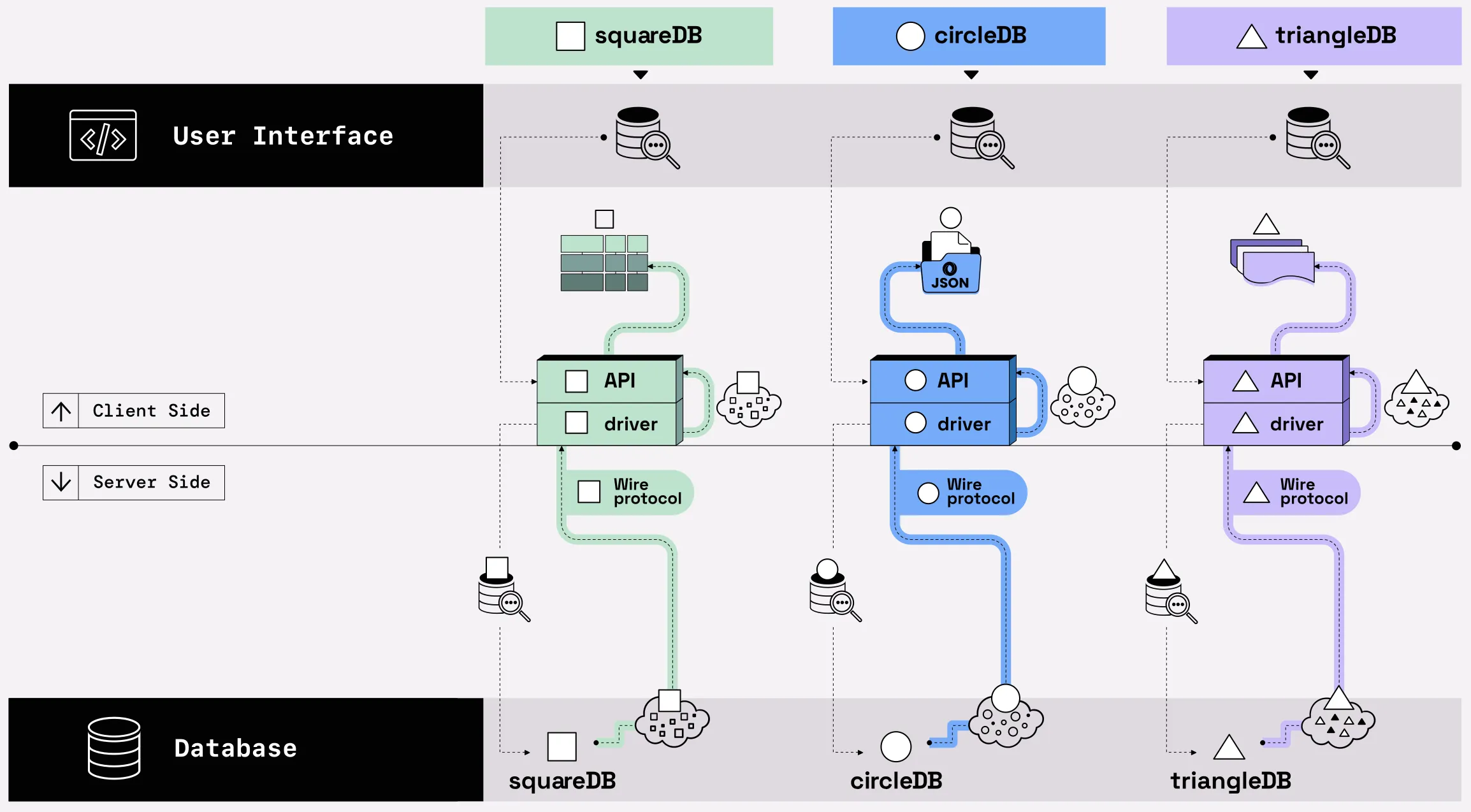
A data system without connectivity standards comes with a lot of asterisks. In the figure below, you can follow the user query from the user interface through the connectivity layer and ultimately over the wire to the database. But the return trip of the results back to the user: that is where the asterisks start adding up. With one query-database combination, it may not be too onerous. But if you need to connect to data across more than one database, and especially if you want to combine those results, you are going to have a bad time.
Figure 03.04. All the sprawl
Here is how you want connecting to a database to work*: *and what will get in the way of making it work
Sequence
Description
Pick a database connector
You pick from available database connectors.* Ideally, the connector is the same for >1 databases so you can use a consistent connector across different data sources.** *Most databases offer their own proprietary native connectors. But is it available for the programming language used by your user interface? **Non-native connectors may also be an option (like ODBC or JDBC), but they could be slower because there will be extra rounds of de/serialization. Read more: Mainlining Databases: Supporting Fast Transactional Workloads on Universal Columnar Data File Formats by Li et al.
Stage a query
You use the client API to stage a query. The client API calls the driver and submits the query to the driver on your behalf. The query stays client-side for now.
Send a query
You use a driver for the database you need to connect to.*** After receiving the query from the client API, the driver generates a request that is sent over the database-specific wire protocol to the database server. ***Lots of variability in behavior across different drivers. Read more: Database Drivers: Naughty or Nice?
Execute the query & return the result set
The database server receives the query and generates a result. This result set is formatted and transported back to the client driver over the database-specific wire protocol.**** ****Most wire protocols use a different data format from the in-memory format used by the database server. This requires the server to de/serialize the data before transporting. Read more: Don't hold my data hostage, Raasveldt & Muhleisen.
Ready the result set
The client driver receives the result set. Again, depending on the data format needs of the client API, it may need to be de/serialized. If not, the result just passes through.***** *****For O/JDBC as the client API, the required format is row-oriented. This means that if the server returned columnar data and the wire protocol preserved that columnar format, the result set would be converted to row-oriented on the client-side.
Present results to users
The client API arranges the result set to present to users.****** ******It is anyone's guess what the returned data format will be: client's native dataframe format; text-based format like CSV, XML, JSON; or something else. Usually, this last conversion exercise is left to the user to make the data useful (i.e., to analyze, combine with other data, and share). In most cases, users can expect another round of data format conversion.
Here is how it actually works:
Sorry I'm late, I just Hadooped my way through a Hive, and I've been living in a powder keg and giving off Apache Sparks…
Skimming the sequence above, most of the asterisks are about the format of the results set: converting, re-converting, and yet again converting the format of the return results so that users can get the result set in an interoperable data format based on standards.
The dumbest piece of the modern data stack:
1. Store columnar data in an RDBMS (relational database management system).
2. Pivot that data to a row-oriented format for transport over the wire.
3. Pivot the row-oriented format back to columnar for viz/analysis.
Maybe it is not the dumbest but it is one of the oldest pieces - the problem stems from data systems designed for yesterday's workloads with yesterday's connectivity layers, built for yesterday's row-wise database systems. Nowadays, these are exactly the kind of accidental complexities that make modern data teams develop around the data system, adding shadow IT infrastructure and leapfrogging around established data engineering pipelines. Many of the asterisks listed would benefit from systems designed on top of standard data formats that maintain that format throughout the path the data is traveling.
Why the focus on columnar format? For most analytics use cases, a columnar format is more than just functional - it is performant. The reason we recommend standards and tools that support columnar-based formats is that today's data systems were built for yesterday's row-wise workflows when row-based as the default format made sense. A columnar default makes the most common workflows faster, but flips the burden of data conversions to the opposite end, so that users can convert from columnar to row-oriented when their workflows call for it.
3.2 Three essential data connectivity standards
A composable data system cannot decrease the number of databases in use. But, it can increase the composability of the databases in use. In short, a composable data system can make the data sprawl feel smaller because people can connect to data no matter where exactly it is stored.
What does it mean to make the sprawl feel smaller? It means that a composable system can:
Make it easier on users to reach across data systems to combine data from different sources, answer bigger questions with more complete and current datasets, and rest assured that they can connect to the data they need with less surprises, asterisks, and "it depends."
Reduce the number of surfaces and knobs that data people have to touch to access data.
Reduce waste in the system, like the confetti of data copies, glue-infra, and band-aid connectivity solutions.
Reduce waiting time for results to make it easier to iterate quickly.
Standards distill data connectivity down to three essential complexities:
Results set format – data people like columnar data for most analytics use cases
Data access – data people want seamless and snappy access
Data transport – developers want to (a) keep the data format the same throughout the data pipeline and (b) use columnar format as the default data format (for goodness sake)
These are mainly quality of life improvements for data people using the data systems. Here are some things that data people do not want to care about:
The specific database where the data is stored – It should not matter exactly where the data is stored, only that they can access it from a reliable client API. Bonus points for a consistent client database API that works for >1 data source.
Which driver they need to use – It depends on the database, so the most important things are that the driver exists (i.e., it is compatible with the required wire protocol).
What wire protocol they are using under the hood – Again, nobody wants to care about this, but as long as it does no harm: if the data storage layer serves Arrow data, users would like to be able to keep their Arrow data. No additional acrobatics should be required on the part of the user end to pivot columnar data back to columnar format after transport.
Layer
Complexity pain
Connectivity gain
Results set
So many data formats to deal with
A single interoperable data format based on standards
Data access
So many client APIs
So many different drivers
A single client API
A single driver to manage, without extra downloads, dependencies, or gaps in functionality
Data transport
So many wire protocols to support/maintain
A single wire protocol
How does it all work? Let's go.
3.2.1 A standard data format for connectivity
Data systems return different data formats. Most cloud vendors use a proprietary on-disk binary file format. Often, this means that the best way to share data between systems is to convert into a common text-based format like CSV, JSON, or XML. This means that data people have to grapple with wrangling various unfriendly tabular data formats into shapes they can work with, like dataframes.
Although most data storage is now columnar, most off-the-shelf wire protocols are row-oriented by default. This means that most data systems convert columnar data to row-oriented for transport over the wire. Even if the wire protocol did preserve columnar data, the client API can still intervene and convert to row-oriented just before delivering the results. Naturally, this forces data people waiting at the end of the pipeline to manually convert the row-oriented data that is returned from the client API back into a columnar format that is more usable for in-memory processing.
While it would be ideal to preserve data formats, actually doing that can be harder than just accepting the fate of all the conversions.
At this point you might be thinking: does anyone really care about all this? Why does it matter if all the conversions happen behind the scenes, or if we ask the data people at the end of the pipeline to wrangle yet another JSON file? It matters to data people because it is annoying and wastes their time - they are constantly faced with developing around the accidental complexities of data connectivity, which takes their time and energy away from focusing on the essential complexities. It matters to data systems people because unnecessary conversions saturate the pipelines, increase costs and consume electricity (kW) without adding value, because the most useful results can be very large and each conversion step is really a "copy and convert".
A composable data system enables Arrow data connectivity. Unfortunately, a standard data format is not enough. To make composable connectivity a reality, we need to add two more standards to the data system connectivity layer:
Every system provides a database interface to allow users to connect to the database server from a client application. The interface separates database access into a "front-end" and a "back-end" on the client application side:
Front-end: The client API is there to let users submit queries to the database.
Back-end: The client driver handles translating the generic commands generated by the client API into database-specific instructions. It then ferries the request to the database, and when the database responds, it ferries the response back to the client API.
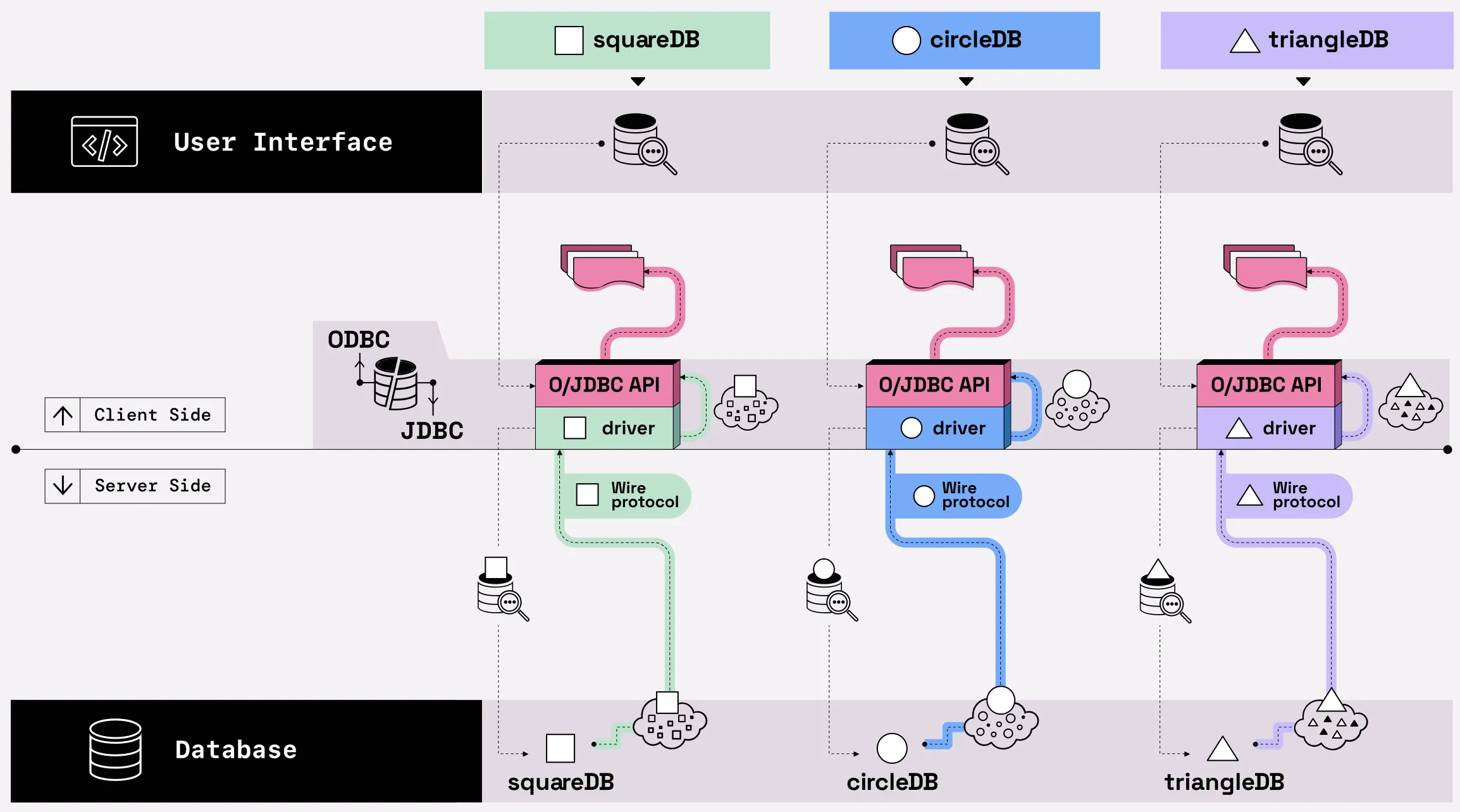
There are two existing, widely used standard client APIs:
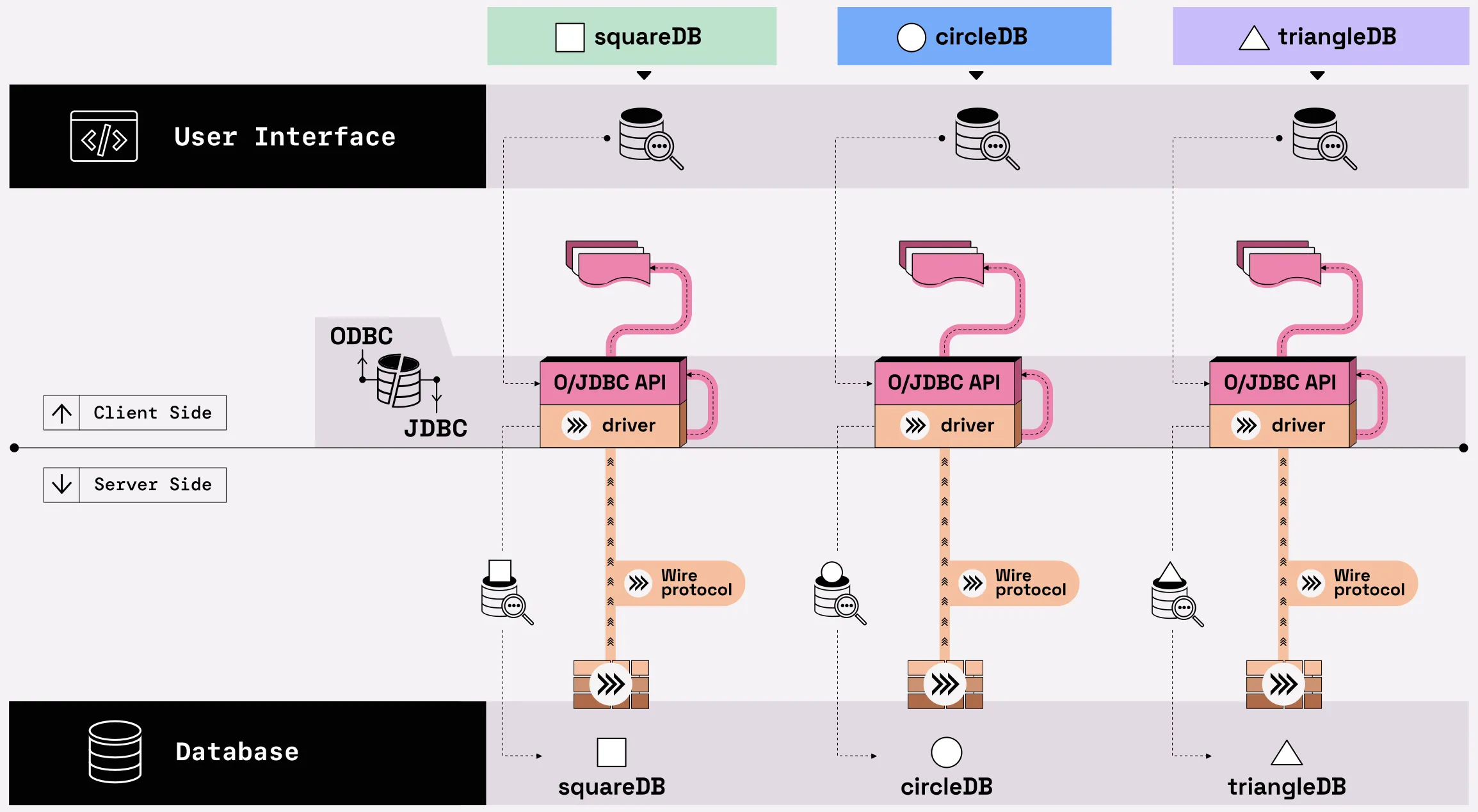
Both ODBC and JDBC are row-oriented client APIs that allow developers to access data independent of the underlying database being used. They both work with a pluggable ecosystem of drivers to handle different wire protocols for accessing data. Which sounds great. But row-oriented client APIs means we are still introducing a lot of "copy and convert" steps on the return trip from the database, and at the end of the journey, our Arrow-loving, dataframe-hugging users are still unhappy.
Figure 03.05. O/JDBC standardize data connectivity, but one row at a time.
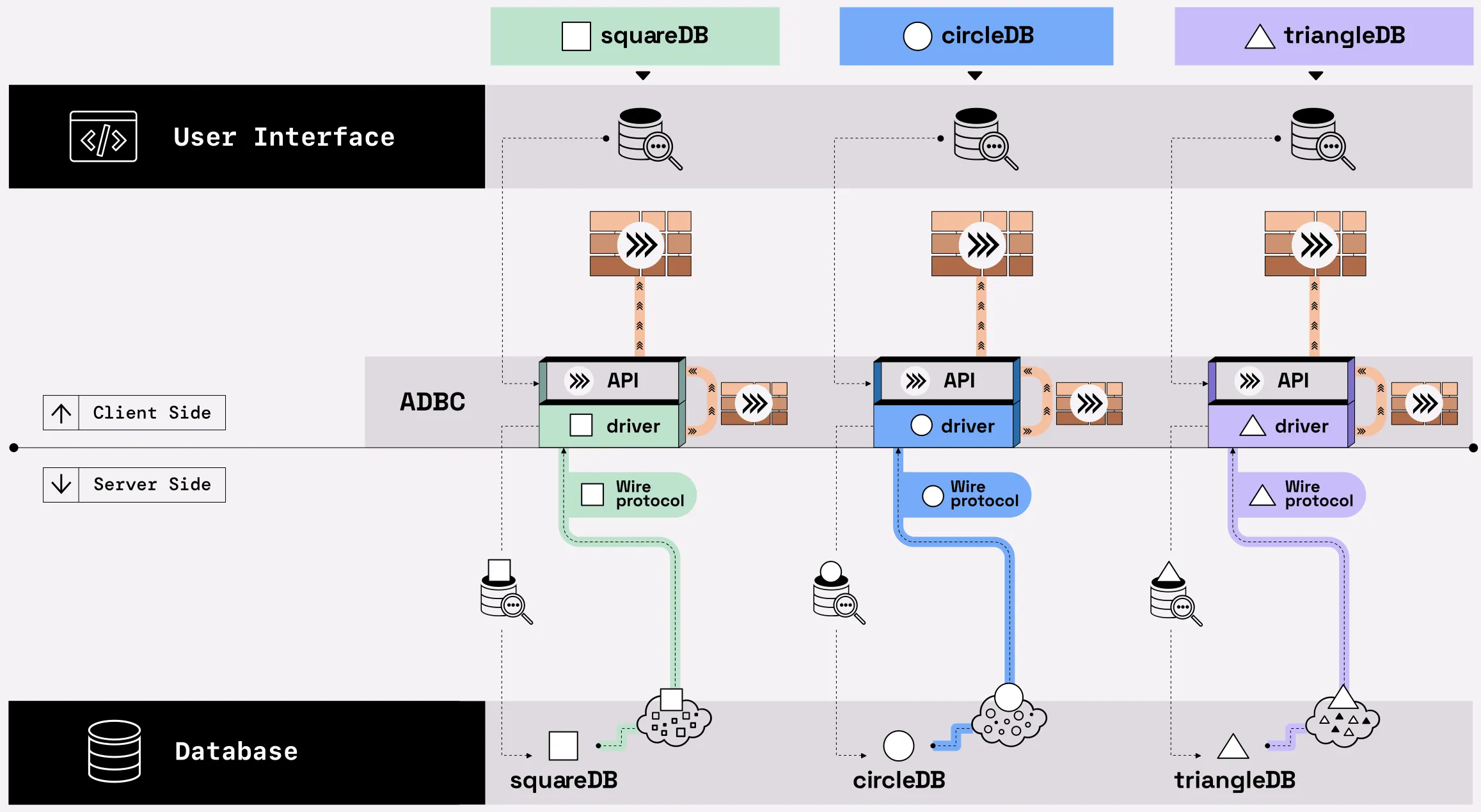
A columnar client API, on the other hand, can preserve columnar results (like Arrow-formatted data) transported over the wire. It could also convert any result set from a database to columnar, so that users do not have to ever fiddle around with conversions after the fact. The Arrow Database Connectivity (ADBC) project was designed to do just that: return results in Arrow format regardless of the format served by the database and the format required by the wire protocol for transporting it. ADBC is a composable client API for fetching and returning Arrow data from databases. ADBC comes with a pluggable ecosystem of drivers to handle different wire protocols including Snowflake, DuckDB, Postgres, SQLite, JDBC, and BigQuery (in the works).
Figure 03.06. ADBC standardizes data connectivity: regardless of the database system, ADBC returns Arrow data.
When DuckDB benchmarked their ADBC interface compared to ODBC, they found that ADBC was 38x faster than ODBC at reading in data from a data source to the client. They attributed the difference to "the extra allocations and copies that exist in ODBC." Our own team at Voltron Data found similar results comparing ADBC and JDBC at reading in data to the client.
Connector
Time (s)
ODBC
28.149
ADBC
0.724
Table 03.01. Comparison of data reading times using ODBC and ADBC. Data from DuckDB (August 2023)
Connector
Time (s)
JDBC - Py4J
130.58
JDBC - Super Jar
9.09
ADBC
6.03
Table 03.02. Comparison of data reading times using two JDBC drivers and ADBC. Data from Voltron Data (May 2023)
3.2.3 A standard data transport layer
Every system exposes a way for external client applications to access data from the database server. When clients and servers are located either on different machines or on different cloud systems, the data is sent over the wire. Sending data over the wire between two systems requires that both sides of the exchange need to shake hands on two main things:
Wire protocol: defines the format for exchanging messages between a database server and its clients. Many data systems roll their own wire protocol.
Result set wire format: defines the format of the results that need to be packaged up and sent back to the client driver, according to the wire protocol.
How would a standard wire protocol support better connectivity in a composable data system? This one is for the data system developers and maintainers. Say you want to keep all the data in the exact same format throughout the journey from database to user, and you want to be sure that the returned data is columnar because 99% of your data sources are columnar.
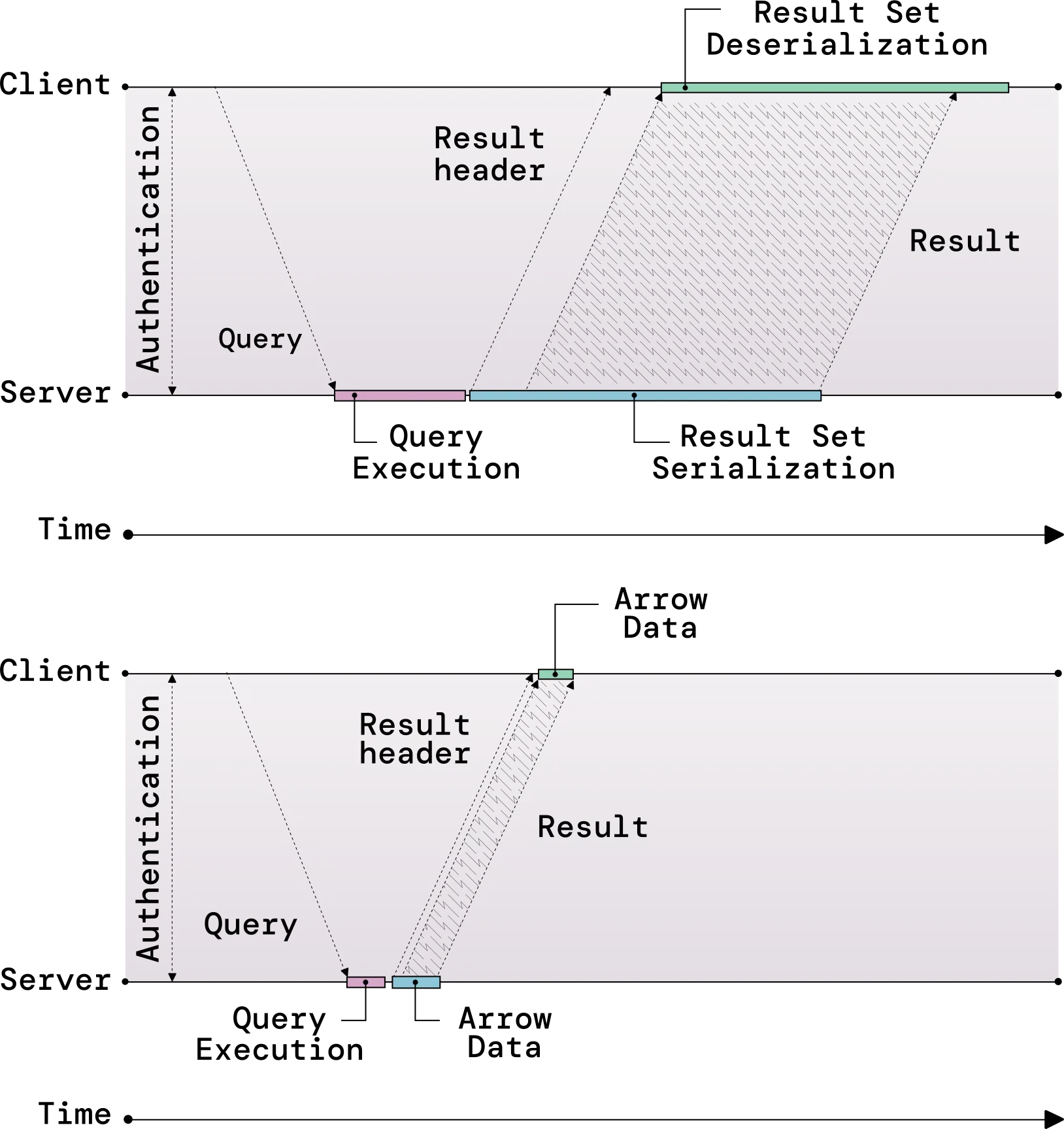
The Arrow Flight SQL project is a composable client-server database protocol, also called a wire protocol, for transporting Arrow data between clients and servers that are separated by a network boundary. Flight SQL defines a standard format, agnostic of any specific database or other type of data system, for doing common actions with SQL databases like executing queries, getting metadata, and fetching query results as Arrow data.
Figure 03.07. ADBC and Flight SQL work together to standardize data connectivity: regardless of the database system, users always get Arrow data in return with a standard client API, and system developers get a standard columnar wire protocol to rely on.
Adopting Flight SQL as a standard on the server-side saves database developers from:
Writing their own wire protocol for transporting columnar Arrow data
Supporting that protocol in multiple languages
Developing client drivers for each database
Developing their own client API (folks who want an Arrow-native API can swap in ADBC, folks who have legacy code that relies on J/ODBC can swap in those respective drivers)
We implemented the Arrow FlightSQL protocol, on top of Flight, which lets InfluxDB 3.0 work in the SQL-based ecosystem. There are clients for FlightSQL that implement popular interfaces such as JDBC, ODBC, and Python DBI, which we can use without modification.
Unlike other systems I have worked on, InfluxDB 3.0 does not have a client driver team and likely won't need one, thanks to Flight and FlightSQL. (By the way, if you don't understand why implementing a JDBC or ODBC driver is so complex and nuanced it often takes a whole team of developers, consider yourself lucky.)
A healthy data connectivity layer is fundamental to any data system design or redesign that does not start with "move all your data from over there to over here." A composable data connectivity layer can help data systems developers climb the data system hierarchy of needs: all you need is MICE.
Figure 03.09. The data systems hierarchy of needs: All you need is MICE.
In true composable fashion, the standards for data connectivity can be mixed and matched, so in this section, we will focus on two common design patterns for strengthening a composable connectivity layer:
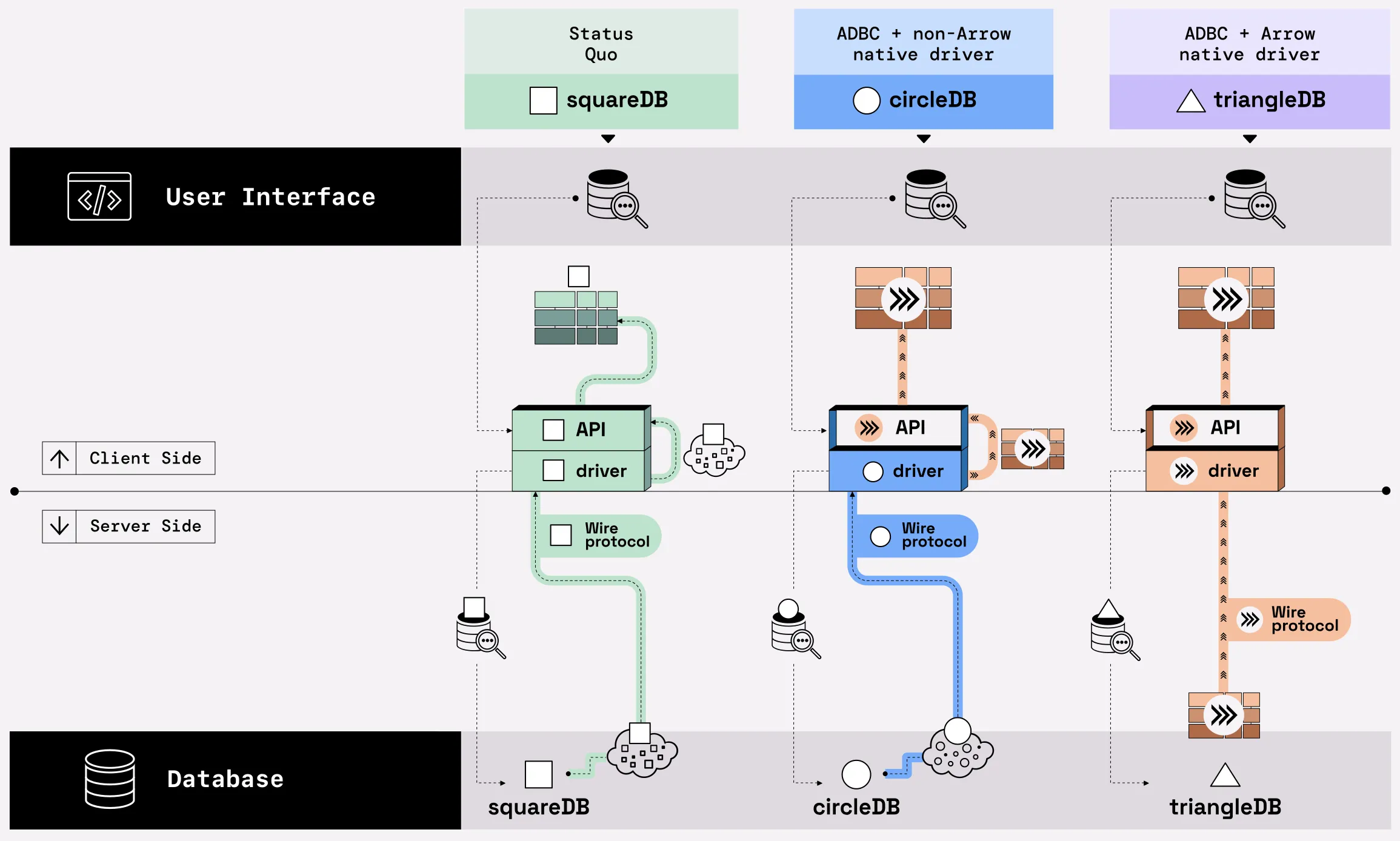
Arrow-native data access: This approach, shown as snailDB in the figure, is enabled by adopting ADBC (Arrow Database Connectivity) as a client API. Compared to the status quo data system (turtleDB), ADBC layers in as a client API that can fetch Arrow data from an Arrow-native database. ADBC can also convert any formatted results into Arrow format to return to users, regardless of the format(s) used by the database and the wire protocol. Adopting ADBC involves only making changes to the client side of a data system, and returns Arrow data to users. This design pattern is a "two birds, one stone" solution: you get both Arrow as a data format and Arrow-native data access.
Arrow-native data access and transport: This approach is shown as slothDB in the figure, and it is enabled by adopting ADBC as an Arrow-native client API on the client side, and changing the underlying wire protocol for the database. As such, this solution requires development work on the server side, which may not always be possible. This design pattern is Arrow all the way if the database serves Arrow-formatted data. If not, the fallback is to return Arrow data from the ADBC client API, converting the data format on the client side.
Figure 03.10. Comparison of the three connectivity approaches: with a database-specific connector (Status Quo), with ADBC and a non-Arrow native driver, and with ADBC and an Arrow-native driver.
In the following four sections, we will outline the advantages and asterisks involved in each of these two composable connectivity design patterns.
3.3.1 Modularity in data connectivity
Figure 03.11. A modular connector is interchangeable: you can easily choose to use it or leave it.
MODULAR
Advantages
Asterisks
ADBC + non-Arrow native driver
Available in multiple programming languages (C/C++, Go, Java, Python, R)
Supports multiple data systems (DuckDB, Snowflake, Postgres, SQLite, and more on the way)
The system still uses different drivers and protocols under the hood
Developers still have to maintain drivers for each database in use
Your database may not have a supported driver yet
ADBC + Flight SQL as an Arrow-native driver
Use the same driver to connect to different databases as long as they expose a Flight SQL endpoint
If you cannot switch to ADBC as a client API, there is already a specific driver for O/JDBC pipelines, so you can incorporate Flight SQL and keep your O/JDBC client code in place (see Figure 03.12)
Requires server-side support that may not be easy to add
Figure 03.12. The Flight SQL protocol is compatible with ODBC and JDBC. You can augment your system by using Flight SQL but keep your O/JDBC client API code in place.
3.3.2 Interoperability in data connectivity
Figure 03.13. A connector needs to interoperate on two levels:
Data format: Return results a standard format that does not require conversions
Wire protocol: Provide a consistent API regardless of the database system
INTEROPERABLE
Advantages
Asterisks
ADBC + non-Arrow native driver
Arrow data back regardless of database system: users get the same results back for the same query across supported databases
Consistent user experience across databases with the same client API
Your pipeline may still have kinks: you still have de/serializations happening that slow data flow
Still have to worry about how to actually write equivalent queries spanning SQL dialects that vary across databases
ADBC + Flight SQL as an Arrow-native driver
Consistent developer experience using a standard API for transporting Arrow data from any database system
The data stays in Arrow format all the way, without internal de/serialization
Flight SQL is a young growing project with support for the following database systems Postgres, Dremio, Graphana, Presto on possible horizon
Still have to worry about how to actually write equivalent queries spanning SQL dialects that vary across databases
3.3.3 Customizing data connectivity solutions
Figure 03.14. A connector does not get in the way if a system needs to flex and adapt to changes, and can even make changes safer and smoother.
CUSTOMIZABLE
Advantages
Asterisks
ADBC + non-Arrow native driver
Common data format makes it possible to combine results across different databases
Any programming language that can talk to C can create a library to use ADBC as a data access interface
ADBC + Flight SQL as an Arrow-native driver
Common wire protocol makes it possible to compose with different Flight SQL clients. Flight SQL also supports JDBC and ODBC clients
Drumroll... the final installment of The Composable Codex is next. In the last chapter, it is time to face The Wall. It is a place where most data systems are headed and we make the case for how to navigate your system over it (hello, engines).
You can keep up with all things Voltron Data by following us on LinkedIn and X (formerly Twitter). If you want to receive alerts for future content like The Composable Codex, sign up for our email list (we won't send you product promotions).
The Codex is written by engineers, data scientists, and leaders at Voltron Data. You can find out more about what we do at Voltron Data here: https://voltrondata.com/how-it-works





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}