Improving Apache Arrow One Change at a Time
By
S
Sam AlbersandS
Stephanie HazlittAuthor(s):
S
Sam AlbersS
Stephanie HazlittPublished: September 15, 2022
5 min read
Apache Arrow is an open-source multi-language toolkit that allows you to process larger-than-memory data sets. If you are processing large amounts of data — for machine learning preprocessing, analytics, or counting lots of things — your data may not fit into the memory available on your computer. The Apache Arrow project is building tools to help solve this blocker.
Every day, developers from around the world submit changes to the Apache Arrow code base. These code changes add to, fix, or improve Arrow and the Arrow documentation. And because Arrow is multi-language, some changes that improve one Arrow language binding can result in benefits to all who use Arrow.
Monitoring Changes in Apache Arrow
While Apache Arrow began as a standardized format for storing data in memory, the project has matured to include tools to help you analyze your data. To do this, Arrow makes use of several compute engines under the hood, including the newly named Arrow C++ execution engine — Acero. The recent Apache Arrow 9.0.0 release brought many new features to Arrow. One of these changes really caught our attention — the improvements to the Acero code that performs joins.
How did we know that the change in the Acero code made in arrow#13493 resulted in faster joins for Arrow users? Apache Arrow uses a benchmarking framework called conbench to track and show performance changes over time. Conbench was introduced in 2021 to track performance changes — regressions or improvements — with each code change in Arrow. One way that we measure performance is by running a set of 22 complex queries in R that simulate real-life data processing workloads. It seems reasonable to ask here, “why are we measuring performance of C++ code by benchmarking R code?”. This is the multilingual happy place of Apache Arrow — all users of the C++ Arrow library and the Acero engine, such as PyArrow and Arrow for R package users, benefit from any improvements in the C++ implementation. These standardized TPC-H like queries are expressed in R, but could also be expressed in your Arrow binding of choice. Regardless of language, the queries have elements that are likely familiar to you: grouped aggregation, filters, table joins, and more. Execution of these queries by Acero are continuously benchmarked across a range of data sizes, with conbench storing the time it takes for these queries to run. This is how we picked up on arrow#13493’s performance gain with dataset joins from Arrow 8.0.0 to Arrow 9.0.0. We first noticed this gain in query 22 which was 5 times faster after this change.
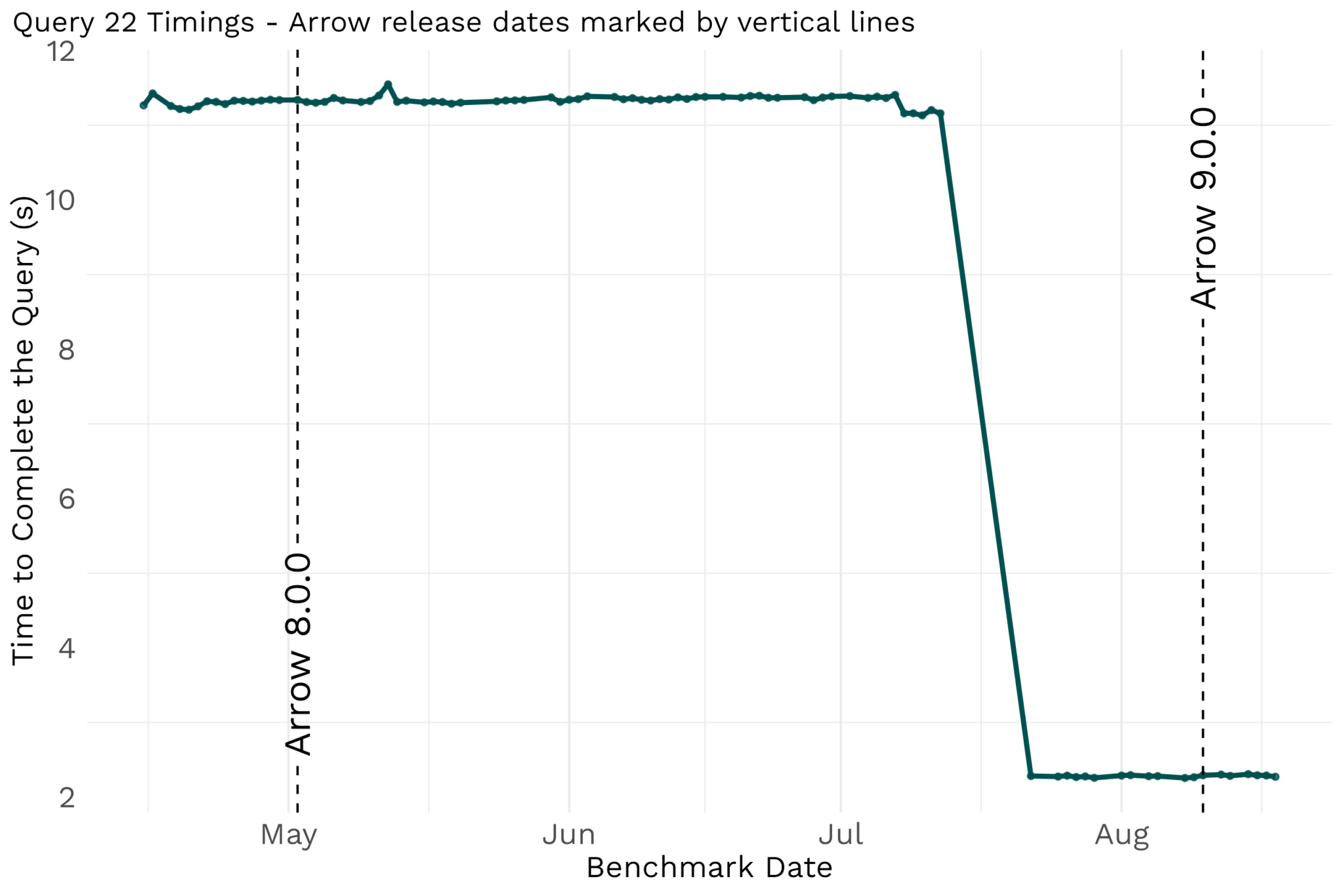
How did one code change result in such a performance uplift? One clue can be found in the code change name “[C++][Compute] Hash Join performance improvement v2”. This development effort was all about improving performance with joins in Arrow C++ and thus the Arrow libraries with a binding to the Arrow C++ Acero execution engine (Python, R and Ruby). We can also have a look at the types of operations that query 22 is doing with some arrow and dplyr code:
r
## Example using tpch
library(arrow)
library(arrowbench)
library(dplyr)
temp_tpch_dir <- tempdir()
Sys.setenv(ARROWBENCH_DATA_DIR = temp_tpch_dir)
## remotes::install_github("voltrondata-labs/arrowbench", dependencies = TRUE)
## will require a working python installation and will install duckdb for you
## with the ability to generate TPC-H datasets to custom library
tpch_data <- generate_tpch(scale_factor = 0.1)
acctbal_mins <- open_dataset(tpch_data$customer) %>%
filter(
substr(
c_phone, 1, 2) %in% c("13", "31", "23", "29", "30", "18", "17") &
c_acctbal > 0
) %>%
summarise(acctbal_min = mean(c_acctbal, na.rm = TRUE), join_id = 1L)
query_22 <- open_dataset(tpch_data$customer) %>%
mutate(cntrycode = substr(c_phone, 1, 2), join_id = 1L) %>%
left_join(acctbal_mins, by = "join_id") %>%
filter(
cntrycode %in% c("13", "31", "23", "29", "30", "18", "17") &
c_acctbal > acctbal_min ) %>%
anti_join(open_dataset(tpch_data$orders), by = c("c_custkey" = "o_custkey")) %>%
select(cntrycode, c_acctbal) %>%
group_by(cntrycode) %>%
summarise(
numcust = n(),
totacctbal = sum(c_acctbal)
) %>%
ungroup() %>%
arrange(cntrycode)
collect(query_22)
#> # A tibble: 7 × 3
#> cntrycode numcust totacctbal
#> <chr> <int> <dbl>
#> 1 13 94 714035.
#> 2 17 96 722560.
#> 3 18 99 738013.
#> 4 23 93 708285.
#> 5 29 85 632693.
#> 6 30 87 646748.
#> 7 31 87 647372.Query 22 does a join between a large table and a medium-sized table, so the effect size with the join improvement was very noticeable. However, query 22 wasn’t the only query to improve. Several queries with joins in their execution plans experienced significant performance improvements after code changes in arrow#13493 were merged to the Arrow code base.
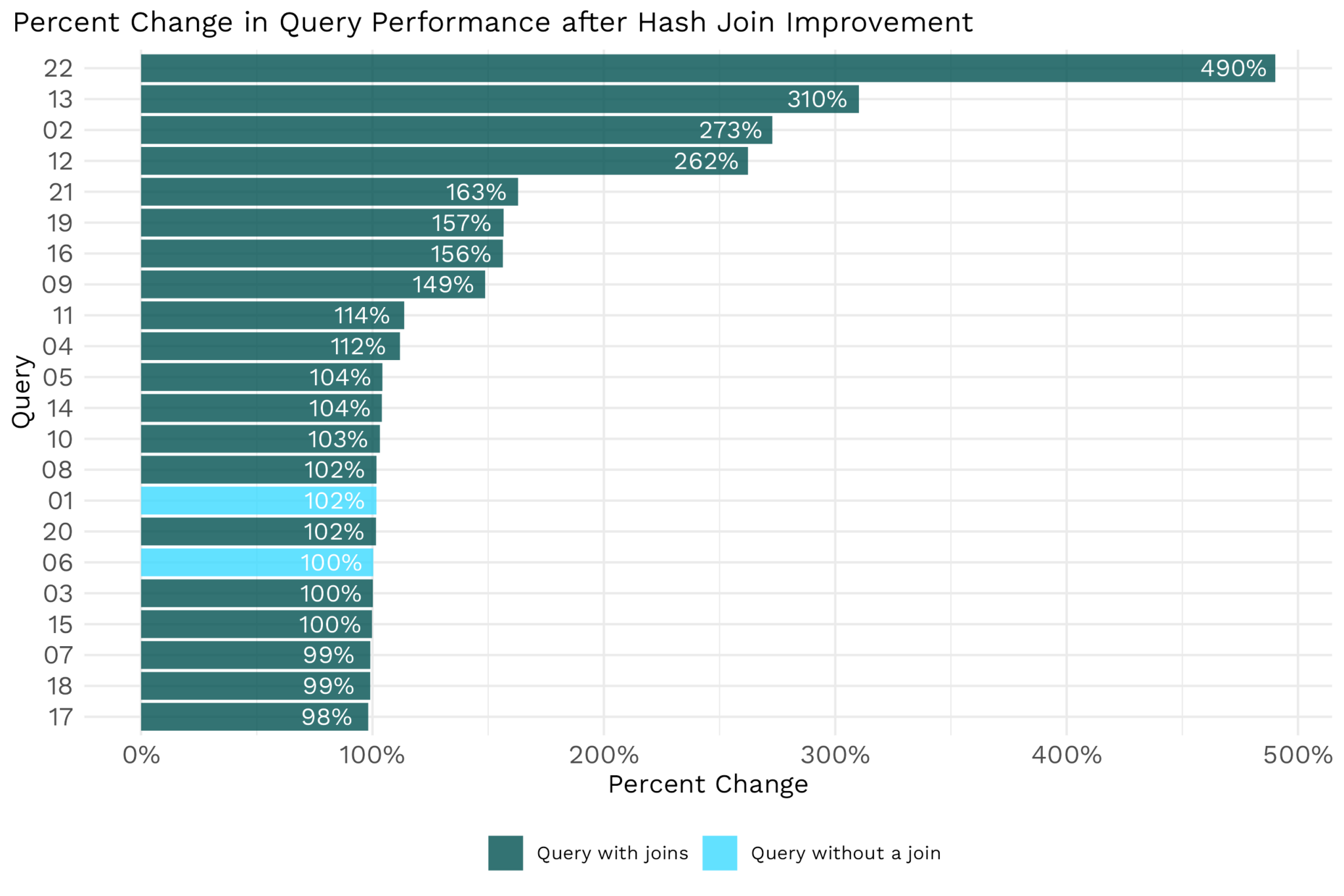
Changes for the Better
The Apache Arrow project sees hundreds of code changes in every quarterly release. We highlighted here how a code change to Arrow, and specifically to Arrow’s internal Acero compute engine, drove significant performance gains for joins in Arrow workflows. You can think of Acero taking your analytics plan – or your “execution plan” – to work out how to group and compute over your datasets objects, and return the results. For a full introduction to Acero, you can watch the Acero talk from The Data Thread.
This post highlights how the Apache Arrow project leverages continuous benchmarking to ensure that performance changes – gains and, of course, regressions too – are easily traceable. The Arrow developer community is watching carefully to ensure every code change improves Arrow and the Arrow experience for developers and users alike.
If you’re working within the Apache Arrow ecosystem, we’re here to support you. Check out Voltron Data Enterprise Support subscription options today.
Photo credit: Akin Cakiner

Keep up with us


