Simplifying database connectivity with Arrow Flight SQL and ADBC
By
D
David Li, T
Tom DrabasandA
Alison HillAuthor(s):
D
David LiT
Tom DrabasA
Alison HillPublished: August 25, 2022
9 min read
Work in Your Language of Choice
Multi-language tools allow users the freedom to work where they want, how they want, unleashing greater productivity. We design and build composable data systems that enable users to write code once, in any language, on any device, and at any scale to develop pipelines faster.
TL;DR The projects shared in this post are:
- Arrow Database Connectivity (we will use the ADBC acronym throughout the post)
- Arrow Flight SQL (we shorten this to Flight SQL in this post)
- Arrow Flight RPC (we shorten this to Flight RPC in this post)
From the start, Apache Arrow has aimed to bridge data ecosystems together. With the ADBC and Flight SQL projects under active development, the Arrow community is now working to simplify database connectivity for both clients and vendors. In this post, we’ll explain who each project tries to help and how they fit together.
Flight SQL or ADBC? Well…
Why two projects? Because database clients and vendors face overlapping but distinct problems.
Database clients face a choice when deciding how to get Arrow data. They could start from a tried-and-true, generic API like JDBC and ODBC. This choice makes it easy to work with different databases. But, neither API has native support for the Arrow columnar format, so the data has to be converted. Converting row-oriented data to columnar is costly. It adds extra development time and uses expensive hardware resources. Another option is to integrate with database-specific libraries that do offer columnar data. Some examples include clickhouse-cpp or google-cloud-bigquery. This option requires extra development work for each database that clients want to use. The ADBC project provides a simpler way for clients to get Arrow data. ADBC is a standard API for connecting Arrow-native clients with databases, engines, and storage. ADBC is modular, and abstracts over different wire protocols and database-specific libraries.
Database vendors also have to make a difficult choice when deciding how to serve up data to clients. If they implement existing generic APIs and protocols, they have to give up some of the benefits of columnar data. On the other hand, they could implement a custom API. But, they would have to then build out support for every different client, now and into the future. Flight SQL offers an alternative for vendors with a fully integrated, Arrow-native wire protocol. Flight SQL is flexible, and not only integrates with ADBC, but also with JDBC and ODBC.
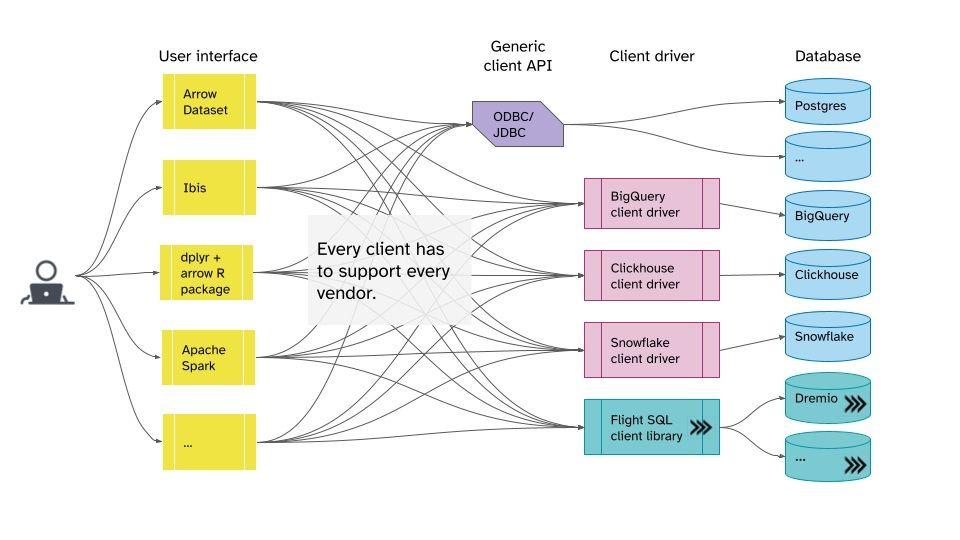
Figure 1. Current state where every client has to support every vendor
In short: in the Arrow-native future, clients will use ADBC to connect to databases. ADBC abstracts over the Flight SQL protocol and other options, including JDBC/ODBC and custom clients. Vendors implement the Flight SQL protocol to be compatible with any client using ADBC.
Let’s look at each of these use cases more closely.
Database vendors
Database vendors can use Flight SQL to build on top of the Arrow Flight stack. Flight RPC provides a framework for transporting Arrow data. Flight SQL tells us how to use Flight RPC—what messages to send, what calls to make—for talking to databases that implement the Flight SQL protocol. Just like how projects like Google Cloud Spanner and Amazon Aurora reimplement the Postgres wire protocol to benefit from its ecosystem, you can do the same with Flight SQL and the Arrow ecosystem.
Despite the name, Flight SQL is not a SQL dialect or abstraction layer. SQL queries still need to comply with the database specific SQL syntax to communicate with the database. Flight SQL only acts as an intermediary between the client and the database—all it wants to do is send your query over safely and get your data back[1].
So Flight SQL is the “full stack” for database vendors:
- a client driver (the Flight SQL client library),
- a wire protocol (the Flight SQL specification), and
- a networking library (Flight RPC).
In a nutshell, here is how they work together:
- A client API calls the Flight SQL client library (the driver)
- The driver makes a request to the database according to the wire protocol (so Flight SQL will put the query in a request payload and package it up, then use Flight RPC to make an RPC call)
- The database responds according to the wire protocol
- The Flight SQL client library returns Arrow data to the client API
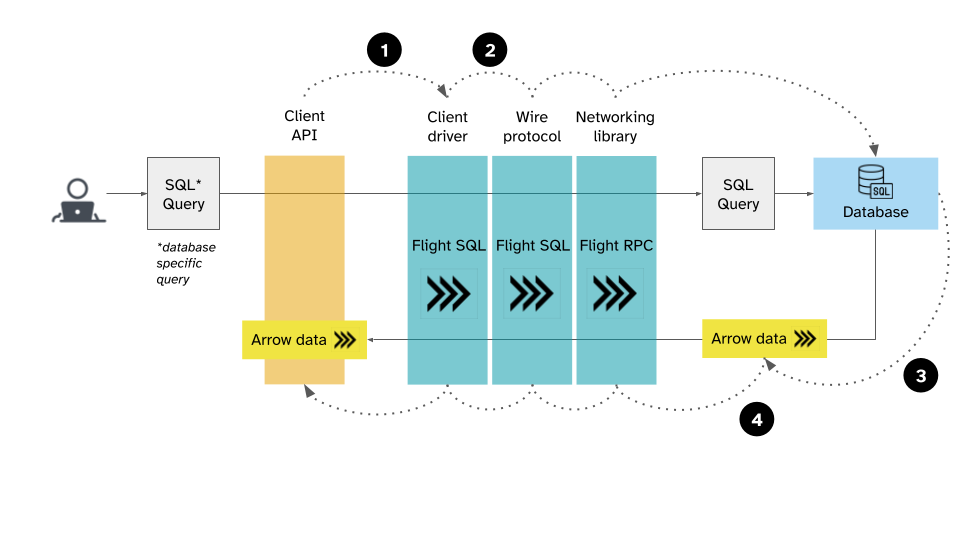
Figure 2. Vision for how Flight SQL connects the client API to a database This means that if you are implementing a database, you can add support for Flight SQL to give your users Arrow-native data access.
Database clients
Currently, database clients who want to access Arrow data have two options. Unfortunately, each option has a downside.
Option 1: Use Arrow-native, but database-specific, APIs
Some systems like Dremio, Google BigQuery, and Snowflake offer Arrow-native data access. But each of them has a different API, and that means extra code for each case. Flight SQL alone cannot help here. It would be like directly using libpq to talk to Postgres: it’s low level, and only helps if the database vendor implements it. And if not, it is hard for a client to retrofit it onto an existing database because it is a “full stack” solution.
Downside: You will benefit from Arrow data, but you will also have to write new code for each database you want to use.
Option 2: Use generic, non-Arrow APIs
Clients could use JDBC/ODBC. These client APIs abstract over different databases, which means less custom code for each database. However, custom code will need to be written to convert the data to Arrow’s columnar format at the end.
Downside: Converting data from JDBC/ODBC to Arrow slows your application down, and you do not benefit from the fact that many databases are Arrow-native underneath.
With the development of ADBC, there is now a third option for database clients. ADBC is a generic database interaction API that provides clients with a standard API for submitting queries to and fetching Arrow data from databases. Underneath, it abstracts over vendor specific drivers, which can in turn use any protocol, whether Flight SQL or something else. In that respect, ADBC takes inspiration from JDBC and ODBC, but is built for Arrow data and analytics use cases.
Unlike Flight SQL, ADBC is purely the client API that applications code to. This gives database vendors flexibility to bring their own wire protocol: ADBC could delegate to the BigQuery client, or Flight SQL, or even take data from JDBC and transpose it into Arrow data.
ADBC fits together naturally with Flight SQL: databases that implement Flight SQL will get ADBC support “for free”, much like how implementing the Postgres wire protocol gives you JDBC and ODBC drivers “for free”. Any vendor that implements Flight SQL would make their database immediately accessible via ADBC. But, whether Flight SQL is used or not, client applications that use ADBC are none the wiser.
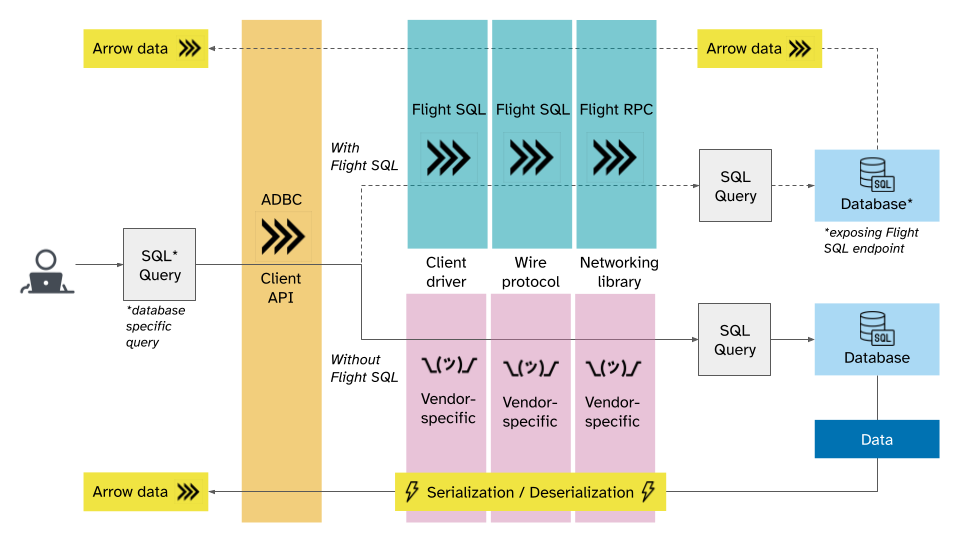
Figure 3. Vision for how ADBC could be used by database clients with and without Flight SQL
Towards an Arrow-native future for database clients and vendors
To summarize:
- Flight RPC is a framework for fast network transport of Arrow data. But, it lacks semantics, and assumes that database vendors will bring their own semantics.
- Flight SQL is a client driver and a wire protocol. It helps database vendors by defining the semantics for interacting with databases using Flight RPC—executing queries, fetching metadata, and so on. Vendors won’t need to serialize or convert Arrow data when using Flight SQL.
- ADBC is a client API. It helps database clients by providing a common Arrow-based API around Flight - SQL and other vendor-specific APIs, making it easier for Arrow-native clients to connect to Arrow-native databases, engines, and storage.
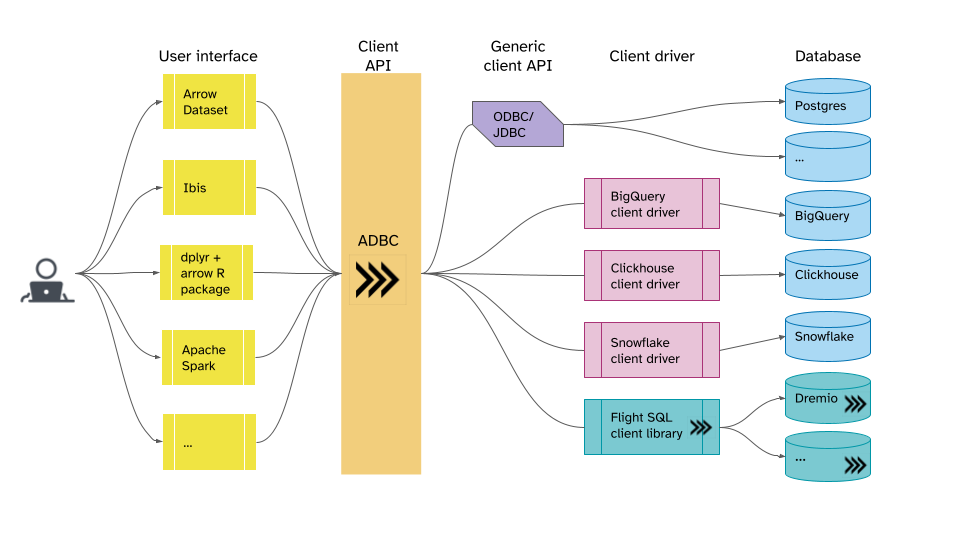
Figure 4. Vision for how ADBC could be used by database clients to get Arrow data from disparate databases
Flight SQL aims to help database vendors that already support columnar data, but would currently have to design their own wire protocols, or bend existing ones to their will. ADBC aims to help database clients that currently have to write specialized code for connecting to each database they want to use, even if all they want is Arrow data in the end. Together, they make getting to a fast, Arrow-native future easy.
Both ADBC and Flight SQL are currently under active development. If you are a database vendor who already has adopted Arrow’s columnar format, we hope you’ll take a look at Flight SQL (available since Arrow 7.0.0) and check out the source repo (https://github.com/apache/arrow). If you are designing a database client and are interested in streamlining how users connect to Arrow data, please have a look at the ADBC source repo (https://github.com/apache/arrow-adbc).
To communicate with Arrow developers about either of these two projects, reach out on the Arrow mailing list: https://arrow.apache.org/community/#mailing-lists. And, if you’re working within the Apache Arrow ecosystem, we’re here to support you. Check out Voltron Data Enterprise Support subscription options today.
Photo Source: https://www.pexels.com/photo/black-multicolored-control-panel-lot-726233/
References
- But, on that note, there are discussions ongoing to generalize Flight SQL to Substrait plans, and Substrait does aim to abstract different query languages.
Previous Article

Keep up with us


