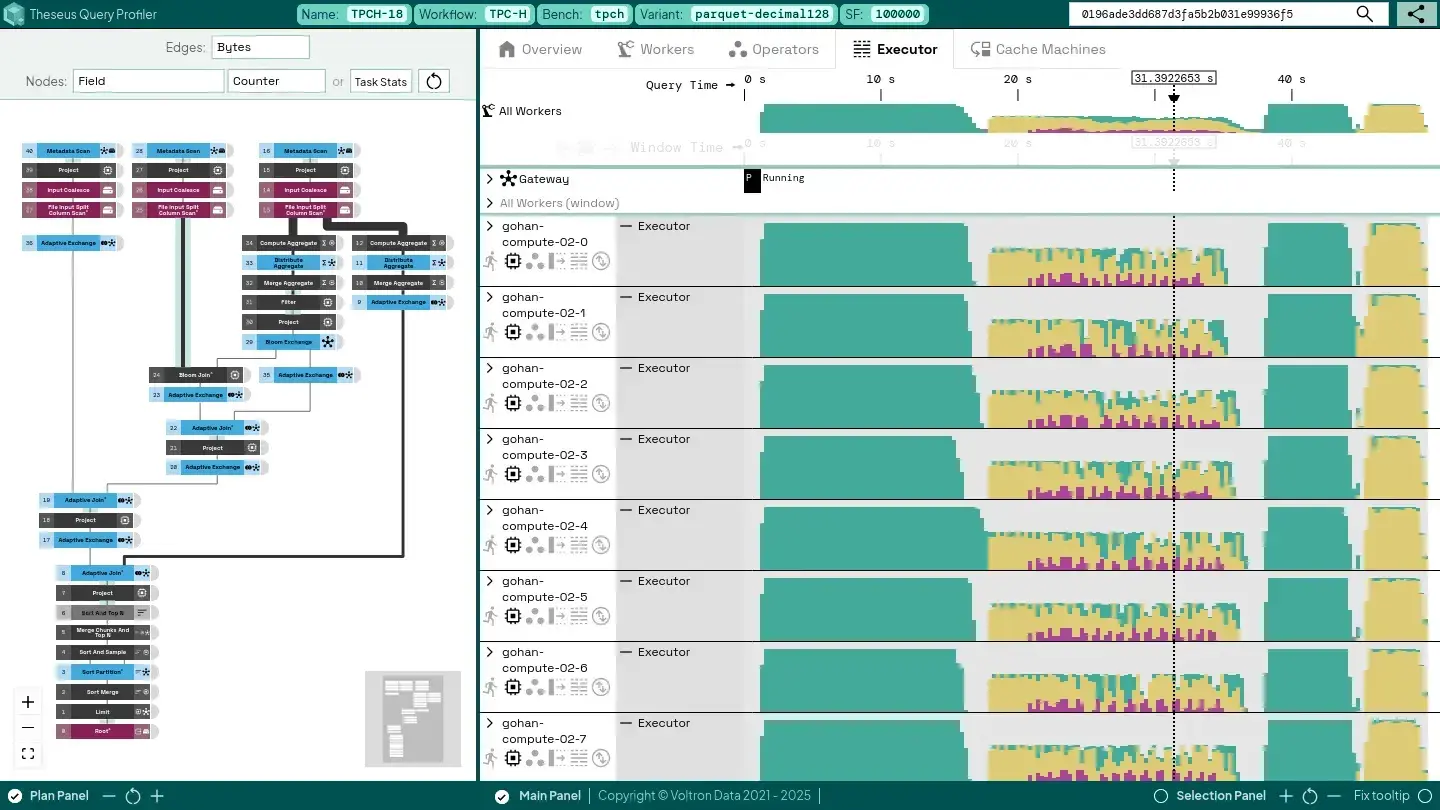
Top 5 Challenges in Large-Scale Data Pipelines — And How GPU-Accelerated Analytics Unlocks Next-Level InnovationVoltron Data
Modern Data Governance and Security with Voltron Data's Theseus: Meeting the Requirements of EO-14028 and OMB M-21-31Steven Morrow
Fast, Elegant, and Performant Geospatial Data Analysis with ArrowKKae SuarezDDewey Dunningtonand 2 more
GPUs for Analytics: An Experiment with Tuning, Chunking, Compression & DecompressionJJoost HoozemansKKae Suarez
The Standard Dataframe Language for Data Analysis and Data EngineeringMMarlene MhangamiFFernanda Foertter
nanoarrow: A Lightweight, Embeddable Arrow Implementation for Data PipelinesKKae SuarezDDewey Dunnington
Dataframe Interoperability in Python: How PyArrow Enables Modular WorkflowsFFrançois MichonneauAAlenka Frim
Use LLMs with Python UDFs to Query & Generate Tabular Data in Natural LanguageCCody PetersonMMarlene Mhangami
Explore a New Way to Deploy Data Storage and Analytics with Arrow Flight SQL and Apache SupersetKKae Suarez
Ibis 5.1: Faster file reading with DuckDB, Arrow-Native Workflows for Snowflake, and moreKKae SuarezAAnja Boskovic
Scaling Down: The Python Libraries You Need to Compress and Analyze the PUMS DatasetKKae SuarezMMarlene Mhangami
Running an Arrow Flight SQL Server and Querying Data with JDBC and ADBCPPhilip MooreTTom Drabasand 1 more
Making Big Data Feel Small: Analysis of Hacker News Stories with BigQuery and Ibis (Part 1)MMarlene Mhangami
Arrow 8.0.0 Release Brings New Functionality for PyArrow, Arrow Flight, C++ Engine, and MoreAAlessandro MolinaWWill Jones
Introducing Substrait: An Interoperable Data to Engine ConnectorPPhillip CloudJJacques Nadeauand 3 more